




一、字符串常用操作
- 常用的内置方法
# str1 = 'I love Python'
# str2 = 'abvabde'
str1.casefold() # 将所有字符串的字符变为小写
# 'i love python'
str2.count('ab') # 统计字符串‘ab’出现的次数,也可以加参数st2.count('ab',0,6)
str1.find('love') # 查找某个子字符串在字符串中的位置
# find 方法还可以接收可选的起始点和结束点参数
sub = "$$$ Get rich now!!! $$$"
sub.find("$$$") # 0
sub.find("$$$",1) # 20
# 当指定起始和终止值时,包含第一个索引,但是不包含第二个索引
sub.find("$$$",1,15) #-1
# join(sub)是以字符串作为分隔符,插入到sub字符串中所有的字符之间
'_'.join('LOVE')
# 'L_O_V_E'
# split() 用于拆分字符串
"1+2+3+4".split("+")
# ['1', '2', '3', '4']
str1.split() # 如果不提供任何分隔符,程序会把所有空格作为分隔符
# ['I', 'love', 'Python']
对于 join 方法,需要被连接的序列元素都必须是字符串
2. 格式化
a. format()方法接受位置参数和关键字参数,二者会传递到一个叫做replacement字段,这个replacement字段在字符串内由大括号({ })表示。
# 字符串中{0},{1},{2}和位置有关,一次被format()的三个参数替换。
"{0} love {1}_{2}".format("I","Python","Spider")
# 'I love Python_Spider'
# 位置函数可以和关键字参数综合在一起使用,但是位置参数一定要放在关键字参数之前
"{0} love {b}_{c}".format("I",b = "Python",c = "Spider")
# 'I love Python_Spider'
- 常用转义字符及含义
| 符号 | 说明 |
|---|---|
| \ ’ | 单引号 |
| \ n | 换行符 |
| \ r | 回车符 |
| \ \ | 反斜杠 |
4.常用的BIF(内建方法)
#number = [1,3,2,8,5]
# 1. list()方法用于把一个可迭代对象转换为列表
b = list('Python')
# b = ['P', 'y', 't', 'h', 'o', 'n']
# 2. tuple()方法用于把一个可迭代的对象转换为元组
c = tuple('Python')
# c = ('P', 'y', 't', 'h', 'o', 'n')
# 3. max()与min()和sum()方法
max(number) #max()方法返回序列最大值
min(number) # min()方法返回序列最小值
sum(number) #返回序列的和
sum(number,1) #加参数,意为从参数开始加起返回
# 4. reversed()方法用于返回逆向迭代的值,返回的不是列表,是一个迭代器对象。
for i in reversed(number):
print(i)
# 5. enumerate()方法生成由二元组
#str1 = 'Python'
for i in enumerate(str1):
print(i)
#结果:
(1, 'y')
(2, 't')
(3, 'h')
(4, 'o')
(5, 'n')
# zip()方法返回由各个可迭代参数共同组成的元组
list1 = [1,2,3,4,5,6]
for each in zip(list1,str1):
print(each)
# 结果:
(1, 'P')
(2, 'y')
(3, 't')
(4, 'h')
(5, 'o')
(6, 'n')
二、补充
- 字符串都是不可变的
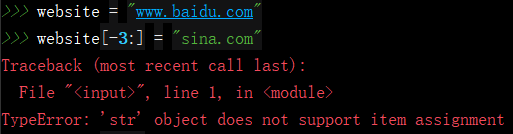
- 格式化实数,使用 f 说明转换的类型,同时提供需要的精度
format = "PI with three decimals:%.3f"
from math import pi
print(format % pi)
# PI with three decimals:3.142
- 使用模板字符串 string.Template
import string
s = string.Template("$x,glorious $x!")
s.substitute(x='slurm') # 'slurm,glorious slurm!'
# 如果替换字段是单词的一部分,参数名就必须用括号括起来,从而准确指明结尾
s = string.Template("It's ${x}tastic!")
s.substitute(x='slurm') # "It's slurmtastic!"
# 可以使用 $$ 插入美元符号
s = string.Template("Make $$ selling $x!")
s.substitute(x='slurm') # 'Make $ selling slurm!'
- 格式化操作符,如果右操作数是元祖,其中的每一个值都需要一个对应的转换说明符
"%s plus %s equals %s" % (1,1,2) # '1 plus 1 equals 2'
- 字段宽度和精度
转换说明符可以包括字段宽度和精度。
字段宽度是转换后的值所保留的最小字符个数
精度(对于数字转换来说)是结果中应该包含的小数位数,或者是转换后的值所能包含的最大字符个数
如果是 * 那么精度将会从元祖中读出
"%10f" % pi
' 3.141593'
"%10.2f" % pi
' 3.14'
"%.5s" % "Guido van Rossum"
'Guido'
可以使用 * (星号)作为字段宽度或精度,此时数值会从元祖中读出
print("%.*s" % (5,"Guido van Rossum")) # Guido
- 符号、对齐和用 0 填充
在字段宽度和精度值之前还可以放置一个 “标志”,该标志可以是零、加号、减号或空格
"%10.2f" % pi # ' 3.14'
# 这里的010,不是八进制数,代表的是字段宽度为10,并且用0来填充空位
"%010.2f" % pi #'0000003.14'
# (-)减号用来左对齐数值
"%-10.2f" % pi # '3.14 '
# (+)加号,表示无论正数还是负数都标识出符号,对齐时很有作用
print("%+5d\n%+5d" % (10,-10))
+10
-10
# (" ")空格意味着在正数前加上空格,在对齐正负数很有作用
print("% 5d\n% 5d" % (10,-10))
10
-10
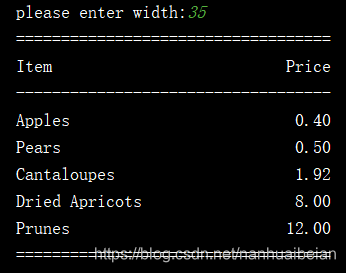
- 字符串格式化示例
代码中使用星号字段宽度说明符来格式化一张包含水果价格的表格,表格的总宽度由用户输入。
因为是由用户提供信息,所以就不能在转换说明符中将字段宽度硬编码
使用星号运算符就可以从转换元祖中读出字段宽度
width_str = input("please enter width:")
width = int(width_str)
price_width = 10
item_width = int(width) - price_width
# 左对齐,值从元祖中取
header_format = "%-*s%*s"
format = "%-*s%*.2f"
print("="*width)
# 使用星号运算符,从转换元祖中读出字段宽度
print(header_format % (item_width,'Item',price_width,'Price'))
print('-'*width)
print(format % (item_width,'Apples',price_width,0.4))
print(format % (item_width,'Pears',price_width,0.5))
print(format % (item_width,'Cantaloupes',price_width,1.92))
print(format % (item_width,'Dried Apricots',price_width,8))
print(format % (item_width,'Prunes',price_width,12))
print("="*width)
8.lower 方法和 title 方法
# lower 方法返回字符串的小写字母版
name = "Gumby"
names = ["gumby","smith","jones"]
if name.lower() in names:
print("Found it!")
# Found it!
# title 方法,将字符串转换为标题,也就是所有单词的首字母大写,其他字母小写
"found it !!!".title()
# 'Found It !!!'
- replace 方法:返回某字符串的所有匹配项均被替换之后得到字符串
"This is a test".replace("test","problem")
'This is a problem'
- strip 方法:返回去除两侧(不包括内部)空格的字符串
" internal whitespace is kept ".strip()
# 'internal whitespace is kept'
# 也可以指定需要去除的字符,将它们列为参数即可
# 但是这个方法只能去除两侧的字符,所有字符串中的星号没有被去掉
"***SPAM * for * everyone!!!***".strip("*!")
# 'SPAM * for * everyone'


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











