




 本文介绍了深网的概念及其与表面网络的区别,并详细解释了深网的组成及特点。此外,还提供了一个Python程序实例,演示如何从深网中抓取股票信息。
本文介绍了深网的概念及其与表面网络的区别,并详细解释了深网的组成及特点。此外,还提供了一个Python程序实例,演示如何从深网中抓取股票信息。
一、什么是Deep Web? 它与普通的Web页面有什么差异?
答:
深网(英语:Deep Web,又称不可见网、隐藏网)是指互联网上那些不能被标准搜索引擎索引的非表面网络内容。
迈克尔·伯格曼将当今互联网上的搜索服务比喻为像在地球的海洋表面的拉起一个大网的搜索,巨量的表面信息固然可以通过这种方式被查找得到,可是还有相当大量的信息由于隐藏在深处而被搜索引擎错失掉。绝大部分这些隐藏的信息是须通过动态请求产生的网页信息,而标准的搜索引擎却无法对其进行查找。传统的搜索引擎“看”不到,也获取不了这些存在于深网的内容,除非通过特定的搜查这些页面才会动态产生。于是相对的,深网就隐藏了起来。据估计,深网要比表面网站大几个数量级(仅作估计,无学术依据)。
整个Web看似杂乱无章,但如果按其所蕴涵信息的“深度”可以划分为SurfaceWeb和DeepWeb两大部分。SurfaceWeb是指通过超链接可以被传统搜索引擎索引到的页面的集合。DeepWeb是指Web中不能被传统的搜索引擎索引到的那部分内容。广义上来说,DeepWeb的内容主要包含4个方面:(1)通过填写表单形成对后台在线数据库的查询而得到的动态页面;(2)由于缺乏被指向的超链接而没有被搜索引擎索引到的页面,大约占整个比例的21.3%;(3)需要注册或其它限制才能访问的内容;(4)Web上可访问的非网页文件,比如图片文件、PDF和Word文档等。
而在实际中应用中,人们则更关注于DeepWeb中的第一部分内容。其原因不难理解,这部分内容对结构化数据的集成更有意义,可以采用的技术也更丰富。DeepWeb数据集成也主要是指对结构化信息的集成,我们同时把Web中可访问的在线数据库称为Web数据库或WDB。这些内容只有在被查询时才会由Web服务器动态生成页面,把结果返回给访问者(图1),因此没有超链接指向这些页面,这是和那些可以被直接访问的静态页面的根本区别。随着Web相关技术的日益成熟和DeepWeb所蕴含信息量的快速增长,通过对web数据库的访问逐渐成为获取信息的主要手段,而对DeepWeb的研究也越来越受到人们的关注。
二、编写程序实现一个Deep Web信息采集,可以是天气信息、股票信息等。
页面分析:获取url接口,动态拉取爬取网页信息

代码实现:
import requests
import json
import os
# url= "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402508937289440778_1658838703304&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838703305"
#
# res = requests.get(url)
# result = res.text.split("jQuery112402508937289440778_1658838703304")[1].split("(")[1].split(");")[0]
# result_json = json.loads(result)
# # print(result_json)
def save_data(data, date):
if not os.path.exists(r'stock_data_%s.csv' % date):
with open("stock_data_%s.csv" % date, "a+", encoding='utf-8') as f:
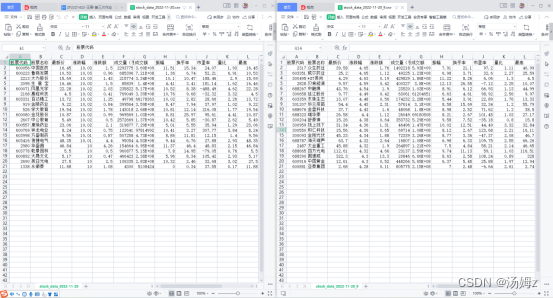
f.write("股票代码,股票名称,最新价,涨跌幅,涨跌额,成交量(手),成交额,振幅,换手率,市盈率,量比,最高,最低,今开,昨收,市净率\n")
for i in data:
Code = i["f12"]
Name = i["f14"]
Close = i['f2']
ChangePercent = i["f3"]
Change = i['f4']
Volume = i['f5']
Amount = i['f6']
Amplitude = i['f7']
TurnoverRate = i['f8']
PERation = i['f9']
VolumeRate = i['f10']
Hign = i['f15']
Low = i['f16']
Open = i['f17']
PreviousClose = i['f18']
PB = i['f22']
row = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.format(
Code,Name,Close,ChangePercent,Change,Volume,Amount,Amplitude,
TurnoverRate,PERation,VolumeRate,Hign,Low,Open,PreviousClose,PB)
f.write(row)
f.write('\n')
for i in range(1, 10):
print("抓取网页%s" % str(i))
url = "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402508937289440778_1658838703304&pn=%s&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838703305" % str(i)
res = requests.get(url)
result = res.text.split("jQuery112402508937289440778_1658838703304")[1].split("(")[1].split(");")[0]
result_json = json.loads(result)
stock_data = result_json['data']['diff']
save_data(stock_data, '2022-11-20_%s'%i)
爬取结果



















 3364
3364




 到【灌水乐园】发言
到【灌水乐园】发言









