



 TD3芯片提供10/25Gbps NRZ SerDes,支持高密度的100GbE端口连接,最多32个100G接口,适用于TOR或汇聚交换机。其交换性能达3.2Tbps(BCM56870)/2Tbps(BCM56873),特色功能包括RDMA、EVPN+VxLAN、芯片可视化和PIPELINE可编程,适用于1U接入交换机和Linecard。然而,该芯片暂不支持SR和源路由,但PIPLINE编程可用于处理多种网络协议。
TD3芯片提供10/25Gbps NRZ SerDes,支持高密度的100GbE端口连接,最多32个100G接口,适用于TOR或汇聚交换机。其交换性能达3.2Tbps(BCM56870)/2Tbps(BCM56873),特色功能包括RDMA、EVPN+VxLAN、芯片可视化和PIPELINE可编程,适用于1U接入交换机和Linecard。然而,该芯片暂不支持SR和源路由,但PIPLINE编程可用于处理多种网络协议。
全称 Trident 3, 属于StrataXGS产品线, 10/25Gbps NRZ SerDes,实现高密度的1/2.5/5/10/25/40/50/100GbE端口连接, 最多支持32*100G接口, 主要用于TOR或汇聚交换机.

关键指标:
- 交换性能:3.2T(BCM56870)/2T(BCM56873)bps
- 定位:1U接入交换机、Linecard
- 典型产品形态:
- 32*100G
- 4825G + 12100G
- 4825G + 8100G
- Buffer:32M(全共享)
- IPV4表项:324K
- MAC表项:288K
- 特色功能:RDMA、EVPN+VxLAN,芯片可视化,PIPELINE可编程、telemetry
- 缺点:暂时不支持SR和源路由, PBR
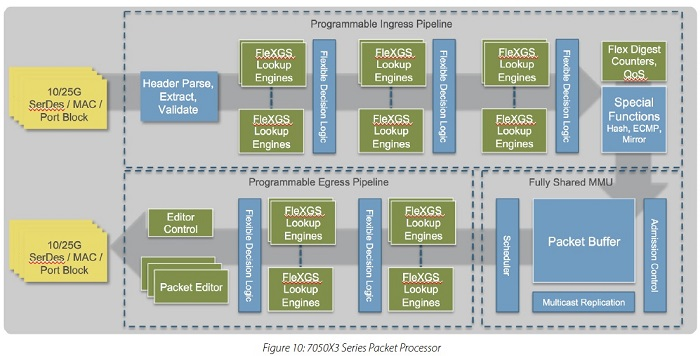
PIPLINE编程可用来处理VXLAN、GPE、MPLS、MPLS OVER GRE 、MPLS OVER UDP、telementry、带外网络可视化以及ERSPAN协议

TD3 PIPELINE

















 6243
6243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









