




 本文介绍了C++中stringstream在使用过程中遇到的问题,特别是关于str(), clear(), eof(), rdbuf()->in_avail()的用法。当stringstream输出完缓存内容后,会设置结束状态,导致无法正常工作。通过调用clear()可以清除状态,使其恢复正常。同时提醒开发者,判断stringstream是否为空不应仅依赖于empty()方法,因为它可能返回true但仍有内容可读。"
108708155,5879680,Windows访问Linux分区的3种工具详解,"['Linux', 'Windows', '运维', '文件系统']
本文介绍了C++中stringstream在使用过程中遇到的问题,特别是关于str(), clear(), eof(), rdbuf()->in_avail()的用法。当stringstream输出完缓存内容后,会设置结束状态,导致无法正常工作。通过调用clear()可以清除状态,使其恢复正常。同时提醒开发者,判断stringstream是否为空不应仅依赖于empty()方法,因为它可能返回true但仍有内容可读。"
108708155,5879680,Windows访问Linux分区的3种工具详解,"['Linux', 'Windows', '运维', '文件系统']
今儿使用stringsteam可是遇到了一个大坑了
先把坑贴上来
int main()
{
stringstream ss;
int tmp = 0;
ss << "1";
ss >> tmp;
cout << tmp << endl;
ss << "2";
ss >> tmp;
cout << tmp << endl;
};
大家觉得这两次的输出是什么,1和2? 哈哈哈 我就是这么错的,它会输出1和1

为啥捏,这解释的东西就比较多了,首先单纯的解释这个问题,我看网上并没有解释相关问题
首先,我们都知道ss.clear()是用来清楚ss的状态,问题就在于,当ss将缓存中的所有东西输出之后,就会设置一个结束的状态,从而导致ss无法正常使用了,看代码
int main()
{
stringstream ss;
int tmp = 0;
ss << "1";
ss >> tmp;
cout << "第一次输出tmp " << tmp << endl;
cout << "ss 为空吗? " << ss.eof() << endl;
ss << "2";
cout << "ss此时的缓存大小是 " << ss.rdbuf()->in_avail() << endl;
ss >> tmp;
cout << tmp << endl;
};
输出结果
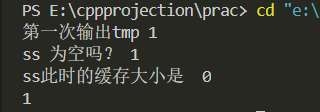
可以看到,当我们第一次输出tmp之后,ss标志位eof已经是空的了,所以当再次ss << "2"的时候,并没有写入到缓存中,所以此时ss可用的缓存就是0
因此,如果我们想继续接着这样使用的话,就应该先把ss的状态清空一下
int main()
{
stringstream ss;
int tmp = 0;
ss << "1";
ss >> tmp;
cout << "第一次输出tmp " << tmp << endl;
cout << "ss 为空吗? " << ss.eof() << endl;
//清空ss状态
ss.clear();
cout << "此时ss的eof是" << ss.eof() << endl;
ss << "2";
cout << "ss此时的缓存大小是 " << ss.rdbuf()->in_avail() << endl;
ss >> tmp;
cout << tmp << endl;
};
结果

可以看到此时ss可以按照我们设想的方式工作了。
切记, 判断ss是否为空的方式是 ? 明天修改
if (ss.rdbuf() -> in_avail() == 0)
和
if (ss.str().empty())
万万不是
if(ss.str().size() == 0)
因此ss占用的内存并不会释放,甚至是可读的,但就是empty()为真。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









