



VQGAN超高像素(1280x460)自然风景生成

阅读本篇文章你可以了解到
2022年中旬,stable diffusion开始火起来进入到大众视野。实际上在2021年,还有一个能根据文字生成高清图片的模型–VQGAN。
接下来我们就来解密,凭什么VQGAN可以在stable diffusion出来之前扛起文生图的大旗。阅读之前强烈建议读者先学习一下《VQ-VAE》:Stable Diffusion设计的架构源泉》
文章目录
1 VQGAN核心思想
VQGAN的论文名为Taming Transformers for High-Resolution Image Synthesis,直译过来是「驯服Transformer模型以实现高清图像合成」。可以看出,该方法是在用Transformer生成图像。可是,为什么这个模型叫做VQGAN,是一个GAN呢?这是因为,VQGAN使用了两阶段的图像生成方法:
- 训练时,先训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。
- 生成时,先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像。
其中,第一个图像压缩模型叫做VQGAN,第二个压缩图像生成模型是一个基于Transformer的模型。
为什么会有这种乍看起来非常麻烦的图像生成方法呢?要理解VQGAN的这种设计动机,有两条路线可以走。两条路线看待问题的角度不同,但实际上是在讲同一件事。
- 第一条路线是从Transformer入手。Transformer已经在文本生成领域大展身手。同时,Transformer也在视觉任务中开始崭露头角。相比擅长捕捉局部特征的CNN,Transformer的优势在于它能更好地融合图像的全局信息。可是,Transformer的自注意力操作开销太大,只能生成一些分辨率较低的图像。因此,作者认为,可以综合CNN和Transformer的优势,先用基于CNN的VQGAN把图像压缩成一个尺寸更小、信息更丰富的小图像,再用Transformer来生成小图像。
- 第二条路线是从VQVAE入手。VQVAE是VQGAN的前作,它有着和VQGAN一模一样两阶段图像生成方法。不同的是,VQVAE没有使用GAN结构,且其配套的压缩图像生成模型是基于CNN的。为提升VQVAE的生成效果,作者提出了两项改进策略:1) 图像压缩模型VQVAE仅使用了均方误差,压缩图像的复原结果较为模糊,可以把图像压缩模型换成GAN;2) 在生成压缩图片这个任务上,基于CNN的图像生成模型比不过Transformer,可以用Transformer代替原来的CNN。
第一条思路是作者在论文的引言中描述的,听起来比较高大上;而第二条思路是读者读过文章后能够自然总结出来的,相对来说比较清晰易懂。如果你已经理解了VQVAE,你能通过第二条思路瞬间弄懂VQGAN的原理。说难听点,VQGAN就是一个改进版的VQVAE。然而,VQGAN的改进非常有效,且使用了若干技巧来实现带约束(比如根据文字描述)的高清图像生成,有非常多地方值得学习。
2 VQVAE创新点
2.1 创新点1-图像压缩模型VQVAE被改进成了VQGAN
一般VAE重建出来出来的图像都会比较模糊。这是因为VAE只使用了均方误差,而均方误差只能保证像素值尽可能接近,却不能保证图像的感知效果更加接近。为此,作者把GAN的一些方法引入VQVAE,改造出了VQGAN。
具体来说,VQGAN有两项改进。
- 第一,作者用感知误差(perceptual loss)代替原来的均方误差作为VQGAN的重建误差。计算感知误差的方法如下:把两幅图像分别输入VGG,取出中间某几层卷积层的特征,计算特征图像之间的均方误差
- 第二,作者引入了GAN的对抗训练机制,加入了一个基于图块的判别器,把GAN误差加入了总误差。基于图块的判别器,即判别器不为整幅图输出一个真或假的判断结果,而是把图像拆成若干图块,分别输出每个图块的判断结果,再对所有图块的判断结果取一个均值。这只是GAN的一种改进策略而已,没有对GAN本身做太大的改动
L = L V G + λ L G A N L = L_{VG} + \lambda L_{GAN} L=LVG+λLGAN
其中, λ \lambda λ是控制两种误差比例的权重。作者在论文中使用了一个公式来自适应地设置 λ \lambda λ。和普通的GAN一样,VQGAN的编码器、解码器(即生成器)、codebook会最小化误差,判别器会最大化误差
有了一个保真度高的图像压缩模型,我们可以进入下一步,训练一个生成压缩图像的模型。
2.2 创新点2-基于 Transformer 的压缩图像生成模型
如前所述,经VQGAN得到的压缩图像与真实图像有一个本质性的不同:真实图像的像素值具有连续性,相邻的颜色更加相似,而压缩图像的像素值则没有这种连续性。压缩图像的这一特性让寻找一个压缩图像生成模型变得异常困难。多数强大的真实图像生成模型(比如GAN)都是输出一个连续的浮点颜色值,再做一个浮点转整数的操作,得到最终的像素值。而对于压缩图像来说,这种输出连续颜色的模型都不适用了。因此,之前的VQVAE使用了一个能建模离散颜色的PixelCNN模型作为压缩图像生成模型。但PixelCNN的表现不够优秀。
恰好,功能强大的Transformer天生就支持建模离散的输出。在NLP中,每个单词都可以用一个离散的数字表示。Transformer会不断生成表示单词的数字,以达到生成句子的效果。
为了让Transformer生成图像,我们可以把生成句子的一个个单词,变成生成压缩图像的一个个像素。但是,要让Transformer生成二维图像,还需要克服一个问题:在生成句子时,Transformer会先生成第一个单词,再根据第一个单词生成第二个单词,再根据第一、第二个单词生成第三个单词……。也就是说,Transformer每次会根据之前所有的单词来生成下一单词。而图像是二维数据,没有先后的概念,怎样让像素和文字一样有先后顺序呢?
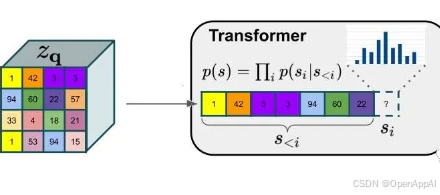
VQGAN的作者使用了自回归图像生成模型的常用做法,给图像的每个像素从左到右,从上到下规定一个顺序。有了先后顺序后,图像就可以被视为一个一维句子,可以用Transfomer生成句子的方式来生成图像了。在第 i i i步,Transformer会根据前 i − 1 i-1 i−1个像素 s < i s_{<i} s<i生成第 i i i个像素 s i s_i si,
2.3 创新点4-带约束的图像生成
在生成新图像时,我们更希望模型能够根据我们的需求生成图像。比如,我们希望模型生成「一幅优美的风景画」,又或者希望模型在一幅草图的基础上作画。这些需求就是模型的约束。为了实现带约束的图像生成,一般的做法是先有一个无约束(输入是随机数)的图像生成模型,再在这个模型的基础上把一个表示约束的向量插入进图像生成的某一步。
把约束向量插入进模型的方法是需要设计的,插入约束向量的方法往往和模型架构有着密切关系。比如假设一个生成模型是U-Net架构,我们可以把约束向量和当前特征图拼接在一起,输入进U-Net的每一大层。
为了实现带约束的图像生成,VQGAN的作者再次借鉴了Transformer实现带约束文字生成的方法。许多自然语言处理任务都可以看成是带约束的文字生成。比如机器翻译,其实可以看成在给定一种语言的句子的前提下,让模型「随机」生成一个另一种语言的句子。比如要把「健耀访问非洲」翻译成英语,我们可以对之前无约束文字生成的Transformer做一些修改。
也就是说,给定约束的句子 c c c,在第 i i i步,Transformer会根据前 i − 1 i-1 i−1个输出单词 s < i s_{<i} s<i以及 c c c生成第 i i i个单词。表示约束的单词被添加到了所有输出之前,作为这次「随机生成」的额外输入。
我们同样可以把这种思想搬到压缩图像生成里。比如对于MNIST数据集,我们希望模型只生成09这些数字中某一个数字的手写图像。也就是说,约束是类别信息,约束的取值是09。我们就可以把这个0~9的约束信息添加到Transformer的输入之前,以实现由类别约束的图像生成

但这种设计又会产生一个新的问题。假设约束条件不能简单地表示成整数,而是一些其他类型的数据,比如语义分割图像,那该怎么办呢?对于这种以图像形式表示的约束,作者的做法是,再训练另一个VQGAN,把约束图像压缩成另一套压缩图片。这一套压缩图片和生成图像的压缩图片有着不同的codebook,就像两种语言有着不同的单词一样。这样,约束图像也变成了一系列的整数,可以用之前的方法进行带约束图像生成了。

3 滑动窗口生成高清图像
由于Transformer注意力计算的开销很大,作者在所有配置中都只使用了 16 × 16 16 \times 16 16×16的压缩图像,再增大压缩图像尺寸的话计算资源就不够了。而另一方面,每张图像在VQGAN中的压缩比例是有限的。如果图像压缩得过多,则VQGAN的重建质量就不够好了。因此,设边长压缩了倍,则该方法一次能生成的图片的最大尺寸是 16 f × 16 f 16f \times 16f 16f×16f。在多项实验中, f = 16 f = 16 f=16的表现都较好。这样算下来,该方法一次只能生成 256 × 256 256 \times 256 256×256的图片。这种尺寸的图片还称不上高清图片。
- 为了生成更大尺寸的图片,作者先训练好了一套能生成 256 × 256 256 \times 256 256×256的图片的VQGAN+Transformer,再用了一种基于滑动窗口的采样机制来生成大图片。
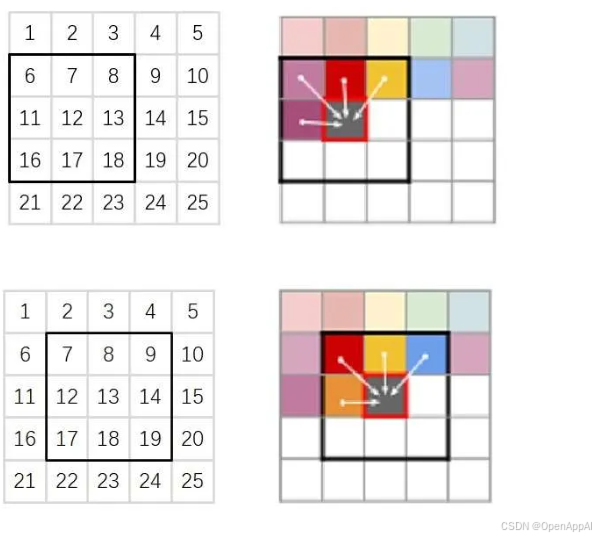
- 具体来说,作者把第一次生成图片划分成若干个256个像素的图块,每个图块大小是 16 × 16 16 \times 16 16×16,一共有 16 × 16 16 \times 16 16×16个图块。
- 之后,在每一轮生成时,只有待生成图块包含的 256 × 256 256 \times 256 256×256个像素会被输入进VQGAN和Transformer,由Transformer生成一个新的压缩图像像素,再把该压缩图像像素解码成最后的像素图块。
作者在论文中解释了为什么用滑动窗口生成高清图像是合理的。作者先是讨论了两种情况,只要满足这两种情况中的任意一种,拿滑动窗口生成图像就是合理的。
- 第一种情况是数据集的统计规律是几乎空间不变,也就是说训练集图片每 256 × 256 256 \times 256 256×256个像素的统计规律是类似的。这和我们拿 3 × 3 3\times 3 3×3卷积卷图像是因为图像每 3 × 3 3\times 3 3×3个像素的统计规律类似的原理是一样的。
- 第二种情况是有空间上的约束信息。比如之前提到的用语义分割图来指导图像生成。由于语义分割也是一张图片,它给每个待生成像素都提供了额外信息。这样,哪怕是用滑动窗口,在局部语义的指导下,模型也足以生成图像了。
若是两种情况都不满足呢?比如在对齐的人脸数据集上做无约束生成。在对齐的人脸数据集里,每张图片中人的五官所在的坐标是差不多的,图片的空间不变性不满足;做无约束生成,自然也没有额外的空间信息。在这种情况下,我们可以人为地添加一个坐标约束,即从左到右、从上到下地给每个像素标一个序号,把每个滑动窗口里的坐标序号做为约束。有了坐标约束后,就还原成了上面的第二种情况,每个像素有了额外的空间信息,基于滑动窗口的方法依然可行。
4 论文实验
在实验部分,作者先是分别验证了基于Transformer的压缩图像生成模型较以往模型的优越性(4.1节)、VQGAN较以往模型的优越性(4.4节末尾)、使用VQGAN做图像压缩的必要性及相关消融实验(4.3节),再把整个生成方法综合起来,在多项图像生成任务上与以往的图像生成模型做定量对比(4.4节),最后展示了该方法惊艳的带约束生成效果(4.2节)。
4.1 验证了基于Transformer的压缩图像生成模型的有效性
在论文4.1节中,作者验证了基于Transformer的压缩图像生成模型的有效性。之前,压缩图像都是使用能输出离散分布的PixelCNN系列模型来生成的。PixelCNN系列的最强模型是PixelSNAIL。为确保公平,作者对比了相同训练时间、相同训练步数下两个网络在不同训练集下的负对数似然(NLL)指标。结果表明,基于Transformer的模型确实训练得更快。
对于直接能建模离散分布的模型来说,NLL就是交叉熵损失函数。

4.2 VQGAN较以往模型的优越性
在论文4.4节末尾,作者将VQGAN和之前的图像压缩模型对比,验证了引入感知误差和GAN结构的有效性。作者汇报了各模型重建图像集与原数据集(ImageNet的训练集和验证集)的FID(指标FID是越低越好)。同时,结果也说明,增大codebook的尺寸或者编码种类都能提升重建效果。

4.3 使用VQGAN做图像压缩的必要性及相关消融实验
在论文4.3节中,作者验证了使用VQGAN的必要性。作者训了两个模型,一个直接让Transformer做真实图像生成,一个用VQGAN把图像边长压缩2倍,再用Transformer生成压缩图像。经比较,使用了VQGAN后,图像生成速度快了10多倍,且图像生成效果也有所提升。
另外,作者还做了有关图像边长压缩比例 f f f的消融实验。作者固定让Transformer生成 16 × 16 16\times16 16×16的压缩图片,即每次训练时用到的图像尺寸都是 16 f × 16 f 16f\times16f 16f×16f。之后,作者训练了不同 f f f下的模型,用各个模型来生成图片。结果显示 f = 16 f=16 f=16时效果最好。这是因为,在固定Transformer的生成分辨率的前提下, f f f越小,Transformer的感受野越小。如果Transformer的感受野过小,就学习不到足够的信息。

4.4 在多项图像生成任务上与以往的图像生成模型做定量对比
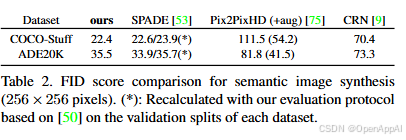
在论文4.4节中,作者探究了VQGAN+Transformer在多项基准测试(benchmark)上的结果。首先是语义图像合成(根据语义分割图像来生成)任务。本文的这套方法还不错。
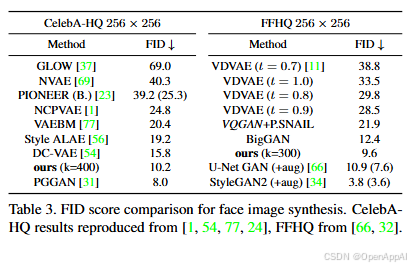
接着是人脸生成任务。这套方法表现还行,但还是比不过专精于某一任务的GAN。
4.5 VQGAN+Transformer在各种约束下的图像生成结果
在论文4.2节中,作者展示了多才多艺的VQGAN+Transformer在各种约束下的图像生成结果。这些图像都是按照默认配置生成的,大小 256 × 256 256\times256 256×256为。

作者还展示了使用了滑动窗口算法后,模型生成的不同分辨率的图像。

总结
VQGAN是一个改进版的VQVAE,它将感知误差和GAN引入了图像压缩模型,把压缩图像生成模型替换成了更强大的Transformer。相比纯种的GAN(如StyleGAN),VQGAN的强大之处在于它支持带约束的高清图像生成。VQGAN借助NLP中"decoder-only"策略实现了带约束图像生成,并使用滑动窗口机制实现了高清图像生成。虽然在某些特定任务上VQGAN还是落后于其他GAN,但VQGAN的泛化性和灵活性都要比纯种GAN要强。它的这些潜力直接促成了Stable Diffusion的诞生。
如果你是读完了VQVAE再来读的VQGAN,为了完全理解VQGAN,你只需要掌握本文提到的4个知识点:VQVAE到VQGAN的改进方法、使用Transformer做图像生成的方法、使用"decoder-only"策略做带约束图像生成的方法、用滑动滑动窗口生成任意尺寸的图片的思想。
参考资料
https://mp.weixin.qq.com/s/5nYdRg7G-mKGXfNxV5_WZQ
https://zhuanlan.zhihu.com/p/515214329

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









