






 本文详细介绍了数据库查询的基本操作,包括选择、连接、嵌套查询和集合操作等,强调了SQL中的SELECT语句及其在处理单表、多表、子查询和集合操作中的应用。内容涵盖投影、选择、连接、外连接、子查询(如IN、比较运算符、ANY/SOME、ALL谓词、EXISTS谓词)、GROUP BY和HAVING子句、ORDER BY子句以及聚集函数。通过对实例的解析,阐述了如何利用SQL进行复杂的数据查询和分析。
本文详细介绍了数据库查询的基本操作,包括选择、连接、嵌套查询和集合操作等,强调了SQL中的SELECT语句及其在处理单表、多表、子查询和集合操作中的应用。内容涵盖投影、选择、连接、外连接、子查询(如IN、比较运算符、ANY/SOME、ALL谓词、EXISTS谓词)、GROUP BY和HAVING子句、ORDER BY子句以及聚集函数。通过对实例的解析,阐述了如何利用SQL进行复杂的数据查询和分析。
本文属于「数据库系统」系列文章之一,这一系列着重于「数据库系统知识的学习与实践」。由于文章内容随时可能发生更新变动,欢迎关注和收藏数据库系统系列文章汇总目录一文以作备忘。需要特别说明的是,为了透彻理解和全面掌握数据库系统,本系列文章中参考了诸多博客、教程、文档、书籍等资料,限于时间精力有限,这里无法一一列出。部分重要资料的不完全参考目录如下所示,在后续学习整理中还会逐渐补充:
- 数据库系统概念 第六版
Database System Concepts, Sixth Edition,作者是Abraham Silberschatz, Henry F. Korth, S. Sudarshan,机械工业出版社- 数据库系统概论 第五版,王珊 萨师煊编著,高等教育出版社
数据查询是数据库的核心操作。SQL提供了 select 语句进行数据查询,该语句具有灵活的使用方式和强大的功能。可以说,SQL的数据查询功能是最丰富的,也是最复杂的,需要细致认真的练习才能加以掌握。其一般格式为:
select [all | distinct] <目标列表达式>[, <目标列表达式>] ...
from <表名或视图名>[, <表名或视图名>] ... | (<select语句>) [as] <别名>
[where <条件表达式>]
[group by <列名1>[, <列名2>] ... [having <条件表达式>]]
[order by <列名1> [asc | desc]
[, <列名2> [asc | desc]] ... ];
整个SQL语句的含义是,根据 where 子句的条件表达式,从 from 子句指定的基本表、视图或派生表中找出满足条件的元组,再按 select 子句中的目标列表达式选出元组中的属性值,最终形成结果表。
- 如果有
group by子句,则将结果按<列名1>, ...的值进行分组,该属性列值相等的元组为一个组。通常会在每组中使用聚集函数。如果group by子句带有having短语,则只有满足指定条件的组才予以输出。 - 如果有
order by子句,则结果表还要按<列名1>, ...的值的升序或降序排序。
不严谨地说,此处的 where 子句等价于
σ
\sigma
σ 选择运算,select 子句基本等价于
∏
\prod
∏ 投影运算(还需要加上 distinct)。因此,这条语句的基本功能等同于关系代数式
∏
A
(
σ
F
(
R
)
)
\prod {}_A(\sigma_{F}(R))
∏A(σF(R))(
R
R
R 是数据来源,
F
F
F 是选择行的条件,
A
A
A 是查询目标)。当然,SELECT 查询语句的总体表达能力大大超过该关系代数式——select 语句既可以完成简单的单表查询,也可以完成复杂的连接查询和嵌套查询。下面以学生-选课数据库为例,说明 select 语句的各种用法。
3.4.1 单表查询
单表查询是指仅涉及到一个表的查询。
- 查询指定的列,用户只需要表中的一部分属性列,可以用
select <目标列表达式>指定要查询的列实现。 - 查询表中的行,带有
where子句的select语句,执行结果只输出查询条件为真的那些记录。 group by子句,根据后面的列名进行分组,并使用聚集函数进行计算。order by子句,后面根据多个变量名进行排序。
1. 选择表中的若干列
选择表中的全部或部分列,即关系代数的投影运算。
(1) 查询指定列
在很多情况下,用户只对表中的一部分属性列感兴趣,这时可以通过在 select 子句中的 <目标列表达式> 中指定要查询的属性列。
【例3.16】查询全体学生的学号与姓名。
答:该语句的执行过程可以是这样的:从 Student 表中取出一个元组,取出该元组在属性列 Sno, Sname 上的值,形成一个新的元组作为输出。对 Student 表中的所有元组做相同的处理,最后形成一个结果关系作为输出。
select Sno, Sname
from Student;
【例3.17】查询全体学生的姓名、学号、所在系。
答:<目标列表达式> 中各个列的先后顺序可以与表中的顺序不一致,用户可以根据应用的需要,改变列的显示顺序。本例中先列出姓名,再列出学号和系。
select Sname, Sno, Sdept
from Student;
(2) 查询全部列
将表中的所有属性列都选出来,有两种方法:一种是在 select 关键字后列出所有列名;如果列的显示顺序与其在基表中的顺序相同,也可简单地将 <目标列表达式> 指定为 * 。
【例3.18】查询全体学生的详细记录。
答:
select *
from Student;
/* 等价于 */
select Sno, Sname, Ssex, Sage, Sdept
from Student;
(3) 查询经过计算的值
select 子句的 <目标列表达式> 不仅可以是表中的属性列,也可以是表达式。
【例3.19】查询全体学生的姓名及其出生年份。
答:查询结果的第二列不是列名,而是一个算术表达式,使用当时的年份(假设为2014年)减去学生的年龄,这样得到的就是学生的出生年份。
select Sname, 2014 - Sage /* 查询结果的第2列是一个算术表达式 */
from Student;
输出结果为:

<目标列表达式> 不仅可以是算术表达式,还可以是字符串常量、函数等。
【例3.20】查询全体学生的姓名、出生年份和所在的院系,要求用小写字母表示系名。
答:
select Sname, 'Year of Birth:', 2014 - Sage, LOWER(Sdept)
from Student;
输出结果为:

用户可以通过指定别名来改变查询结果的列标题,这对于含算术表达式、常量、函数名的 <目标列表达式> 尤其有用,例如对于【例3.20】可以定义如下别名:
select Sname NAME, 'Year of Birth:' BIRTH, 2014 - Sage BIRTHDAY, LOWER(Sdept) DEPARTMENT
from Student;
输出结果为:

2. 选择表中的若干元组
(1) 消除取值重复的行
两个本来并不完全相同的元组,在投影到指定的某些列上后,可能会变成相同的行。可以用 distinct 消除它们。
【例3.21】查询选修了课程的学生学号。
答:
select Sno from SC;
执行上面的 select 语句后,结果为:

该查询结果里包含了许多重复的行。如想去掉结果表中重复的行,必须指定 distinct :
select distinct Sno from SC;
则执行结果为:

如果没有指定 distinct 关键词,则默认为 all ,即保留结果表中取值重复的行:
select Sno from SC;
/* 等价于 */
select all Sno from SC;
(2) 查询满足条件的元组
查询满足指定条件的元组,可以通过 where 子句实现。where 子句常用的查询条件如下表所示:
| 查询条件 | 谓词 |
|---|---|
| 比较 | =, >, <, >=, <=, !=, <>, !>, !< ,not + 上述比较运算符 |
| 确定范围 | between and, not between and |
| 确定集合 | in, not in |
| 字符匹配 | like, not like |
| 空值 | is null, is not null |
| 多重条件(逻辑运算) | and, or, not |
| 存在 | exists, not exists |
① 比较大小。用于进行比较的运算符一般包括:= 等于、> 大于、< 小于、>= 大于等于、<= 小于等于、!= 或 <> 不等于、!> 不大于、!< 不小于。
【例3.22】查询计算机科学系全体学生的名单。
答:关系DBMS执行如下查询的一种可能过程是:对 Student 表进行全表扫描,取出一个元组,检查该元组在 Sdept 列的值是否等于 'CS' ,如果相等则取出 Sname 列的值,形成一个新的元组输出;否则跳过该元组,取下一个元组。重复该过程,直到处理完 Student 表的所有元组。
select Sname
from Student
where Sdept = 'CS';
如果全校有数万个学生,计算机系的学生人数占全校学生的5%左右,可在 Student 表的 Sdept 列上建立索引,系统会利用该索引找出 Sdept = 'CS' 的元组,从中取出 Sname 列值形成结果关系。这就避免了对 Student 表的全表扫描,加快了查询速度。注意,如果学生较少,索引查找不一定能提高查询效率,系统仍会使用全表扫描。这由查询优化器按照某些规则、或估计执行代价来作出选择。
【例3.23】查询所有年龄在20岁以下的学生姓名及其年龄。
答:
select Sname, Sage
from Student
where Sage < 20;
【例3.24】查询考试成绩不及格的学生的学号。
答:这里使用了 distinct 短语,当一个学生有多门课程不及格时,他的学号也只列一次。
select distinct Sno
from SC
where Grade < 60;
② 确定范围。谓词 between ... and ... 和 not between ... and ... 可用来查找属性值在(或不在)指定范围内的元组,其中 between 后是范围的下限(即低值),and 后是范围的上限(即高值)。
【例3.25】查询年龄在
20
∼
23
20\sim 23
20∼23 岁(包括20岁和23岁)之间的学生的姓名、系别和年龄。
答:
select Sname, Sdept, Sage
from Student
where Sage between 20 and 23;
【例3.26】查询年龄不在
20
∼
23
20\sim 23
20∼23 岁之间的学生姓名、系别和年龄。
答:
select Sname, Sdept, Sage
from Student
where Sage not between 20 and 23;
③ 确定集合。谓词 in 可用来查找属性值属于指定集合的元组。与 in 相对的谓词是 not in ,用于查找属性值不属于指定集合的元组。
【例3.27】查询计算机科学系 CS 、数学系 MA 和信息系 IS 学生的姓名和性别。
答:
select Sname, Ssex
from Student
where Sdept in ('CS', 'MA', 'IS');
【例3.28】查询既不是计算机科学系、数学系,也不是信息系的学生的姓名和性别。
答:
select Sname, Ssex
from Student
where Sdept not in ('CS', 'MA', 'IS');
④ 字符匹配。谓词 like 可用来进行字符串的匹配。其一般语法格式如下:
[not] like '<匹配串>' [escape '<换码字符>']
其含义是查找「指定的属性列值」与 <匹配串> 相匹配的元组。<匹配串> 可以是一个完整的字符串,也可以含有通配符 % 和 _ :
%代表任意长度(长度可以为 0 0 0 )的字符串。例如a%b表示以a开头,以b结尾的任意长度的字符串,如acb, addgb, ab等都满足该匹配串。_代表任意单个字符。例如a_b表示以a开头、以b结尾的、长度为 3 3 3 的任意字符串,如acb, afb等都满足该匹配串。
【例3.29】查询学号为 201215121 的学生的详细情况。
答:如果 like 后面的匹配串中不含通配符,则可用 = 等于运算符取代 like 谓词,用 != 或 <> 不等于运算符取代 not like 谓词。
select *
from Student
where Sno like '201215121';
/* 等价于 */
select *
from Student
where Sno = '201215121';
【例3.30】查询所有姓刘的学生的姓名、学号和性别。
答:
select Sname, Sno, Ssex
from Student
where Sname like '刘%';
【例3.31】查询姓“欧阳”且全名为三个汉字的学生的姓名。
答:注意,数据库字符集为 ASCII 时一个汉字需要两个 _ ;当字符集为 GBK 时只需要一个 _ 。
select Sname
from Student
where Sname like '欧阳__';
【例3.32】查询名字中第二个字为“阳”的学生的姓名和学号。
答:
select Sname, Sno
from Student
where Sname like '__阳%';
【例3.33】查询所有不姓刘的学生的姓名、学号和性别。
答:
select Sname, Sno, Ssex
from Student
where Sname not like '刘%';
如果用户要查询的字符串本身就含有通配符 % 或 _ ,这时就要使用 escape '<换码字符>' 短语对通配符进行转义。
【例3.34】查询 DB_Design 课程的课程号和学分。
答:escape '\' 表示 \ 为换码字符,这样匹配串中紧跟在 \ 后面的字符 _ 不再具有通配符的含义,转义为普通的 _ 字符。
select Cno, Credit
from Course
where Cname like 'DB\_Design' escape '\';
【例3.35】查询以 DB_ 开头,且倒数第三个字符为 i 的课程的详细情况。
答:这里的匹配串为 DB\_%i__ ,第一个 _ 前面有换码字符 \ ,所以被转义为普通的 _ 字符;i 后面的两个 _ 的前面均没有换码字符 \ ,所以它们仍作为通配符。
select *
from Course
where Cname like 'DB\_%i__' escape '\';
⑤ 涉及空值的查询。判断是否为空值要用 is null 和 is not null 。
【例3.36】某些学生选修课程后没有参加考试,所以有选课记录,但没有考试成绩。查询缺少成绩的学生的学号和相应的课程号。
答:注意,这里的 is 不能用等号 = 代替。
select Sno, Cno
from SC
where Grade is null; /* 分数Grade是空值 */
【例3.37】查询所有有成绩的学生学号和课程号。
答:
select Sno, Cno
from SC
where Grade is not null;
⑥ 多重条件查询。逻辑运算符 and 和 or 可用来连接多个查询条件。and 的优先级高于 or ,但用户可用括号改变优先级。
【例3.38】查询计算机科学系年龄在
20
20
20 岁以下的学生姓名。
答:
select Sname
from Student
where Sdept = 'CS' and Sage < 20;
在【例3.27】中的 in 谓词实际上是多个 or 运算符的缩写,因此该例中的查询也可以用 or 运算符,写成如下等价形式:
select Sname, Ssex
from Student
where Sdept = 'CS' or Sdept = 'MA' or Sdept = 'IS';
3. order by 子句
用户可用 order by 子句,对查询结果按照一个或多个属性列的升序 asc 或降序 desc 排列,其中的第一个属性列为主序并依次类推。每一个属性列名后用 asc 或者 desc 声明升序还是降序,默认升序。对于空值,排序时显示的次序由具体系统实现来决定。例如按升序排,含空值的元组最后显示;按降序排,空值的元组则最先显示。各个系统的实现可以不同,只要保持一致即可。
【例3.39】查询选修了
3
3
3 号课程的学生的学号及其成绩,查询结果按照分数的降序排列。
答:
select Sno, Grade
from SC
where Cno = '3'
order by Grade desc;
【例3.40】查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
答:
select *
from Student
order by Sdept, Sage desc;
4. 聚集函数
为了进一步方便用户,增强检索功能,SQL提供了许多聚集函数,主要有:
COUNT ([DISTINCT | ALL] * ) // 统计元组个数
COUNT ([DISTINCT | ALL] <列名>) // 统计一列中值的个数
SUM ([DISTINCT | ALL] <列名>) // 计算一数值型列值的总和
AVG ([DISTINCT | ALL] <列名>) // 计算一数值型列值的平均值
MAX ([DISTINCT | ALL] <列名>) // 求一列值的最大值
Min ([DISTINCT | ALL] <列名>) // 求一列值的最小值
注意:
- 聚集函数中可以指定
distinct短语,即在统计或计算时取消指定列中的重复值。如果不指定distinct短语或指定all短语(all为默认设置),则表示不取消重复值。 - 聚集函数在统计或计算时一般忽略/跳过空值,除了
count(*)外,count(*)是对元组进行计数,某个元组的一个或部分列取空值,不影响count的统计结果。 where子句中不能使用聚集函数作为条件表达式,聚集函数只能用于select子句和group by中的having子句。- 如果未对查询结果分组,聚集函数将作用于整个查询结果,即整个查询结果只有一个函数值。否则,聚集函数将作用于每一个组,即每一组都有一个函数值。
【例3.41】查询学生总人数。
答:
select count(*)
from Student;
【例3.42】查询选修了课程的学生人数。
答:学生每选修一门课,在 SC 中都有一条相应的记录。一个学生要选修多门课程,为避免重复计算学生人数,必须在 count 函数中用 distinct 短语。
select count(distinct Sno)
from SC;
【例3.43】计算选修
1
1
1 号课程的学生平均成绩。
答:
select avg(Grade)
from SC
where Cno = '1';
【例3.44】查询选修
1
1
1 号课程的学生最高分数。
答:
select max(Grade)
from SC
where Cno = '1';
【例3.45】查询学生 201215012 选修课程的总学分数。
答:
select sum(Ccredit)
from SC, Course
where Sno = '201215012' and SC.Cno = Course.Cno;
5. group by 子句
group by 子句将查询结果按某一列或多列的值分组,值相等的为一组。对查询结果分组的目的是为了细化聚集函数的作用对象,再对每组数据进行算术计算或者聚集函数等操作,最后每个组产生结果表中的一条记录。
如果未对查询结果分组,聚集函数将作用于整个查询结果,只有一个函数值,如前面的【3.41~3.45】。对查询结果分组后,聚集函数将作用于每一组,即每一组都有一个函数值。
【例3.46】求各个课程号及相应的选课人数。
答:如下的语句对查询结果按 Cno 的值分组,所有具有相同 Cno 值的元组为一组,然后对每一组作用聚集函数 count 进行计算,以求得该组的学生人数。
select Cno, count(Sno)
from Student
group by Cno;
查询结果可能为:
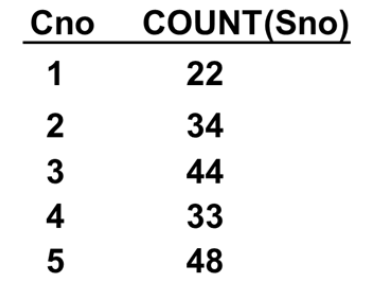
如果分组后还要求按一定的条件对这些组进行筛选,最终只输出满足指定条件的组,则可以使用 having 短语指定筛选条件,在各组中进行控制,选择满足指定条件的组进行输出。
【例3.47】查询选修了三门以上课程的学生学号。
答:下面先用 group by 子句按 Sno 进行分组,再用聚集函数 count 对每一组计数;having 短语给出了选择组的条件,只有满足条件(即元组个数
>
3
>3
>3 ,表示此学生选修的课程超过三门)的组才会被选出来。
select Sno
from SC
group by Sno
having count(*) > 3;
where 子句和 having 短语的区别在于作用对象不同。where 子句作用于基本表或视图,从中选择满足条件的元组;having 短语作用于组,从中选择满足条件的组。
【例3.48】查询平均成绩大于等于
90
90
90 分的学生学号和平均成绩。
答:下面的语句是错误的!
select Sno, avg(Grade)
from SC
where avg(Grade) >= 90
group by Sno;
因为 where 子句中是不能用聚集函数作为条件表达式的。正确的查询语句应该是:
select Sno, avg(Grade)
from SC
group by Sno
having avg(Grade) >= 90;
3.4.2 连接查询
前面的查询都是针对一个表进行的。若一个查询同时涉及两个以上的表,则称之为连接查询。连接查询是关系数据库中最主要的查询,包括等值连接查询、自然连接查询、非等值连接查询、自身连接查询、外连接查询和复合条件连接查询等。
1. 等值与非等值连接查询
连接查询的 where 子句中用来连接两个表的条件称为连接条件或连接谓词,其一般格式为:
[<表名1>.]<列名1> <比较运算符> [<表名2>].<列名2>
此外,连接谓词还可以使用下面的形式:
[<表名1>.]<列名1> between [<表名2>.]<列名2> and [<表名2>.]<列名3>
其中,连接谓词中的列名也称为连接字段,这些连接列的数据类型必须是可比的(包括可判等的),但名字不必相同(当连接条件中比较的两个列名相同时,必须在其列名前加上所属的表的名字和圆点表示区别)。比较运算符则主要有 =, >, <, >=, <=, !=, <> 等。
- 当连接运算符为
=时,称为等值连接,后面还会学到外连接; - 使用其他运算符时,称为非等值连接。
【例3.49】查询每个学生及其选修课程的情况。
答:学生情况存放在 Student 表中,学生选课情况存放在 SC 表中,所以本查询实际上涉及 Student 和 SC 两个表。这两个表之间的联系是通过公关属性 Sno 实现的。
select Student.*, SC.*
from Student, SC
where Student.Sno = SC.Sno; /* 将Student与SC中同一学生的元组连接起来 */
假设 Student 表、SC 表的数据如图3.2(见3.2 学生-课程数据库)所示,该查询的执行结果如下图所示:
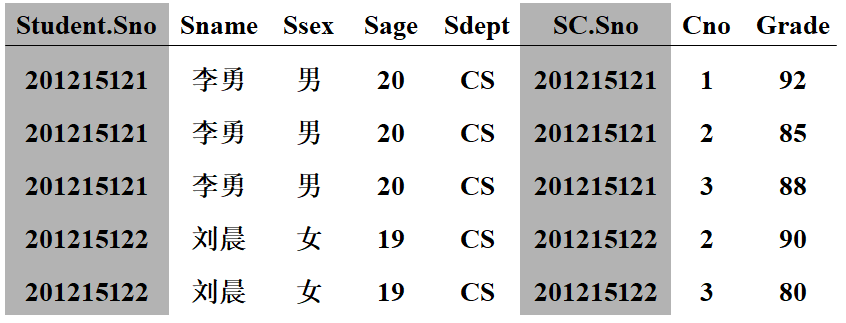
本例中,select 子句与 where 子句中的属性名前,都加上了表名前缀,这是为了避免混淆。如果属性名在参加连接的各表中是唯一的,则可以省略表名前缀。
关系DBMS执行该连接操作的一种可能过程是:首先在表 Student 中找到第一个元组,然后从头开始扫描 SC 表,逐一查找与 Student 第一个元组的 Sno 相等的 SC 元组,找到后就将 Student 中的第一个元组与该元组拼接起来,形成结果表中一个元组。SC 全部查找完后,再找 Student 中的第二个元组,然后再从头开始扫描 SC ,逐一查找满足连接条件的元组,找到后就将 Student 中的第二个元组与该元组拼接起来,形成结果表中一个元组。重复上述操作,直到 Student 中的全部元组都处理完毕为止。这就是嵌套循环连接算法的基本思想。
如果在 SC 表的 Sno 上建立了索引的话,就不用每次全表扫描 SC 表了,而是根据 Sno 值通过索引找到相应的 SC 元组。用索引查询 SC 中满足条件的元组,一般会比全表扫描快。
若在等值连接中,把目标列重复的属性值去掉,则为自然连接。
【例3.50】对例3.49用自然连接完成。
答:本例中,由于 Sname, Ssex, Sage, Sdep, Cno, Grade 属性列在 Student 表与 SC 表中是唯一的,因此引用时可以去掉表名前缀;而 Sno 在两个表中都出现了,因此引用时必须加上表名前缀。
select Student.Sno, Sname, Ssex, Sage, Sdept, Cno, Grade
from Student, SC
where Student.Sno = SC.Sno;
一条SQL语句可以同时完成选择和连接查询,这时 where 子句是由连接谓词和选择谓词组合的复合条件。
【例3.51】查询选修
2
2
2 号课程且成绩在
90
90
90 分以上的所有学生的学号和姓名。
答:如下查询的一种优化(高效)的执行过程是,先从 SC 中挑选出 Cno = '2' 并且 Grade > 90 的元组,形成一个中间关系,再和 Student 中满足条件的元组进行连接,得到最终的结果关系。
select Student.Sno, Sname
from Student, SC
where Student.Sno = SC.Sno /* 连接谓词 */
and SC.Cno = '2' and SC.Grade > 90; /* 其他限定条件 */
2. 自身连接
连接操作不仅可在两个表之间进行,也可以是一个表与其自己进行连接,称为表的自身连接。由于是同一个表,需要给表起别名以示区别;由于所有属性名都是同名属性,因此必须使用别名前缀。
【例3.52】查询每一门课的间接先修课(即先修课的先修课)。
答:在 Course 表中只有每门课的直接先修课信息,而没有先修课的先修课。要得到这个信息,必须先对一门课找到其先修课,再按此先修课的课程号,查找它的先修课程。这就要将 Course 表与其自身连接。为此,先要为 Course 表取两个别名,一个是 First ,另一个是 Second :
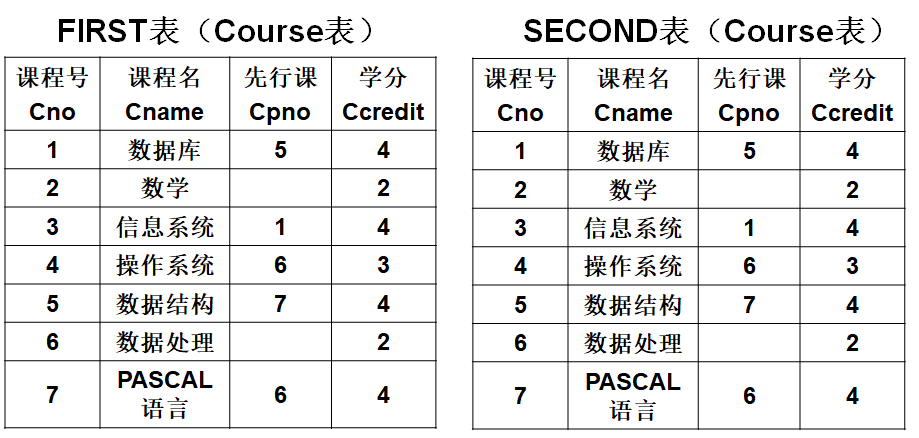
完成该查询的SQL语句很简单:
select First.Cno, Second.Cpno
from Course First, Course Second
where First.Cpno = Second.Cno;
该查询的结果为:
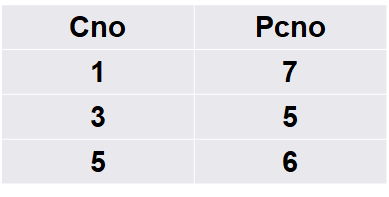
3. 外连接
在通常的连接操作中,只有满足连接条件的元组才能作为结果输出。如【例3.49】的结果表中没有 201215123 和 201215125 两个学生的信息,原因在于他们没有选课,在 SC 表中么有相应的元组,导致 Student 表中这些元组在连接时被舍弃了。
有时想以 Student 表为主体,列出每个学生的基本情况及其选课情况。若某个学生没有选课,仍把 Student 的悬浮元组保存在结果关系中,而在 SC 表的属性上填空值 NULL ,这时就需要使用外连接。外连接的概念已在第二章2.4.2节中说明过,与普通连接的区别是:外连接操作以指定表为连接主体,将主体表中不满足连接条件的元组一并输出。左外连接以左边关系为主体、列出左边关系中所有的元组;右外连接以右边关系为主体、列出右边关系中所有的元组。
【例3.53】查询每个学生及其选修课程的情况。
答:可参照【例3.53】改写【例3.49】。
select Student.Sno, Sname, Ssex, Sage, Sdept, Cno, Grade
from Student left outer join SC on (Student.Sno = SC.Sno);
/* 也可以使用using来去掉结果表中的重复值 */
/* from Student left outer join SC using (Sno); */
执行结果如下:
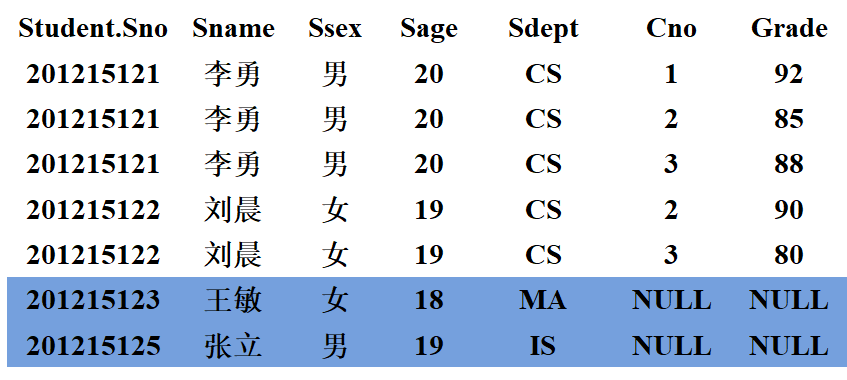
4. 多表连接
连接操作除了可以是两表连接、一个表与其自身连接、外连接之外,还可以是两个以上的表进行连接,后者通常称为多表连接。
【例3.54】查询每个学生的学号、姓名、选修的课程及成绩。
答:本查询涉及三个表,完成该查询的SQL语句如下:
select Student.Sno, Sname, Cname, Grade
from Student, SC, Course
where Student.Sno = SC.Sno and SC.Cno = Course.Cno;
关系DBMS在执行多表连接时,通常是先进行两个表的连接操作,再将其连接结果与第三个表进行连接。本例的一种可能的执行方式是:先将 Student 表与 SC 表进行连接,得到每个学生的学号、姓名、所选课程号和相应的成绩,然后再将其与 Course 表进行连接,得到最终结果。
3.4.3 嵌套查询
在SQL语言中,一个 select-from-where 语句称为一个查询块。将一个查询块嵌套在另一个查询块的 where 子句或 having 短语的条件中的查询,称为嵌套查询 nested query 。例如:
select Sname /* 外层查询或父查询 */
from Student
where Sno in (
select Sno /* 内层查询或子查询 */
from SC
where Cno = '2'
);
本例中,下层查询块 select Sno from SC where Cno = '2' 是嵌套在上层查询块 select Sname from Student where Sno in 的 where 子句中的。上层查询块称为外层查询或父查询,下层查询块称为内层查询或子查询。
SQL语言允许多层嵌套查询,即一个子查询中还可以嵌套其他子查询。需要特别指出的是,子查询的 select 语句中不能使用 order by 子句,order by 子句只能对最终查询结果排序。
嵌套查询使用户可以用多个简单查询构成复杂的查询,从而增强SQL的查询能力。以层层嵌套的方式来构造程序,正是SQL中结构化的含义所在。
1. 带有 in 谓词的子查询
在嵌套查询中,子查询的结果往往是一个集合,所以谓词 in 是嵌套查询中最经常使用的谓词。带有 in 谓词的子查询,是指父查询与子查询之间用 in 进行连接,判断某个属性列值是否在子查询的结果中。
【例3.55】查询与“刘晨”在同一个系学习的学生。
答:先分步来完成此查询,然后再构造嵌套查询:
/* 确定刘晨所在系名 */
select Sdept
from Student
where Sname = '刘晨';
/* 结果为CS */
/* 查找所有在CS系学习的学生 */
select Sno, Sname, Sdept
from Student
where Sdept = 'CS';
得到的结果如下:

子查询实现:将第一步查询嵌入到第二步查询的条件中,用以构造第二步查询的条件。构造出的嵌套查询如下:
select Sno, Sname, Sdept
from Student
where Sdept in (
select Sdept
from Student
where Sname = '刘晨';
);
本例中,子查询的查询条件不依赖于父查询,称为不相关子查询。一种求解方法是由里向外处理,即先执行子查询,子查询的结果用于建立其父查询的查找条件。得到如下的语句,然后执行该语句:
select Sno, Sname, Sdept
from Student
where Sdept in ('CS');
本例中的查询也可以用自身连接来完成:
select S1.Sno, S1.Sname, S1.Sdept /* 例3.55的解法二 */
from Student S1, Student S2
where S1.Sdept = s2.Sdept and S2.Sname = '刘晨';
可见,实现同一个查询请求可以有多种方法,当然不同的方法其执行效率可能会有差别,甚至差别很大。这就是数据库编程人员应该掌握的数据库性能调优技术,有兴趣的可以参考本章相关文献资料、以及具体产品的性能调优方法。
【例3.56】查询选修了课程名为“信息系统”的学生学号和姓名。
答:本查询涉及学号、姓名、课程名三个属性,学号和姓名存放在 Student 表中,课程名存放在 Course 表中,但 Student 与 Course 两个表之间没有直接联系,必须通过 SC 表建立它们二者之间的联系。所以本查询实际上涉及三个关系。
select Sno, Sname
from Student
where Sno in (
select Sno
from SC
where Cno in (
select Cno
from Course
where Cname = '信息系统'
)
);
本查询同样可以用连接查询实现:
select Student.Sno, Sname
from Student, SC, Course
where Student.Sno = SC.Sno and SC.Cno = Course.Cno and Course.Cname = '信息系统';
有些嵌套查询可以用连接运算替代,有些是不能替代的。从【例3.55】和【例3.56】可以看出,查询涉及多个关系时,用嵌套查询逐步求解层次清楚、易于构造,具有结构化程序设计的优点。但是相比于连接运算,目前商用关系DBMS对嵌套查询的优化做得还不够完善,所以在实际应用中,能够用连接运算表达的查询尽可能采用连接运算。
【例3.55】和【例3.56】中子查询的查询条件不依赖于父查询,这类子查询称为不相关子查询。不相关子查询是较简单的一类子查询。如果子查询的查询条件依赖于父查询,这类子查询称为相关子查询 correlated subquery ,整个查询语句称为相关嵌套查询 correlated nested query 语句。【例3.57】就是一个相关子查询的例子。
2. 带有比较运算符的子查询
带有比较运算符的子查询是指,父查询与子查询之间用比较运算符进行连接。当用户能确切知道内层查询返回的是单个值时,可以用 >, <, =, >=, <=, !=, <> 等比较运算符。
例如在【例3.55】中,由于一个学生只可能在一个系中学习,也就是说内查询的结果是一个值,因此可用 = 替代 in 。
select Sno, Sname, Sdept /* 例3.55的解法三 */
from Student
where Sdept = (
select Sdept
from Student
where Sname = '刘晨'
);
【例3.57】找出每个学生超过他自己选修课程平均成绩的课程号。
答:下面的查询中,x 是 SC 表的别名,又称为元组变量,可用来表示 SC 表的一个元组。内层查询是求一个学生所有选修课程平均成绩的,至于是哪个学生的平均成绩,就要看参数 x.Sno 的值,而该值是与父查询相关的,因此这类查询称为相关子查询。
select Sno, Cno
from SC x
where Grade >= (
select avg(Grade) /* 某学生的平均成绩 */
from SC y
where y.Sno = x.Sno
);
如上语句的一种可能的执行过程,将采用以下三个步骤:
① 从外层查询中取出 SC 的一个元组 x ,将元组 x 的 Sno 值(如 201215121 )传送给内层查询:
select avg(Grade)
from SC y
where y.Sno = '201215121';
② 执行内层查询,得到值 88 (近似值),用该值代替内层查询,得到外层查询:
select Sno, Cno
from SC x
where Grade >= 88;
③ 执行这个外层查询,得到结果:
(201215121, 1)
(201215121, 3)
然后外层查询取出下一个元组,重复做上述①至③步骤的处理,直到外层的 SC 元组全部处理完毕。结果为:
(201215121, 1)
(201215121, 3)
(201215122, 2)
由此可见,求解相关子查询不能像求解不相关子查询那样,一次将子查询求解出来,然后求解父查询。内层查询由于与外层查询有关,因此必须反复求值。
3. 带有 some/any 或 all 谓词修饰符的子查询
子查询返回单值时,可以用比较运算符,但返回多值时要用 any(有的系统用 some)或 all 谓词修饰符。使用 any/all 修饰符时,必须同时使用比较运算符。其语义如下:
> any /* 大于子查询结果中的某个值 */
> all /* 大于子查询结果中的所有值 */
< any /* 小于子查询结果中的某个值 */
< all /* 小于子查询结果中的所有值 */
>= any /* 大于等于子查询结果中的某个值 */
>= all /* 大于等于子查询结果中的所有值 */
<= any /* 小于等于子查询结果中的某个值 */
<= all /* 小于等于子查询结果中的所有值 */
= any /* 等于子查询结果中的某个值 */
= all /* 等于子查询结果中的所有值,通常没有意义 */
!= any /* 不等于子查询结果中的某个值 */
!= all /* 不等于子查询结果中的所有值 */
【例3.58】查询非计算机科学系中,比计算机科学系中任意一个学生年龄小的学生姓名和年龄。
答:显然这是不相关子查询。关系DBMS在执行此查询时,首先处理子查询,找出 CS 系中所有学生的年龄,构成一个集合 (20, 19) ;然后处理父查询,找出所有不是 CS 系且年龄小于 20 或 19 的学生。
select Sname, Sage
from Student
where Sdept != 'CS' and Sage < any (
select Sage
from Student
where Sdept = 'CS'
);
查询结果如下:

本查询也可以用聚集函数来实现,首先用子查询找出 CS 系中最大年龄 (20) ,然后在父查询中查询所有非 CS 系且年龄小于 20 岁的学生。SQL语句如下:
select Sname, Sage
from Student
where Sdept != 'CS' and Sage < (
select max(Sage)
from Student
where Sdept = 'CS'
);
【例3.59】查询非计算机科学系中,比计算机科学系所有学生年龄都小的学生姓名及年龄。
答:显然这也是不相关子查询。关系DBMS在执行此查询时,首先处理子查询,找出 CS 系中所有学生的年龄,构成一个集合 (20, 19) ;然后处理父查询,找出所有不是 CS 系且年龄既小于 20 也小于 19 的学生。查询结果中只有 (王敏, 18) 。
select Sname, Sage
from Student
where Sdept != 'CS' and Sage < all (
select Sage
from Student
where Sdept = 'CS'
);
本查询同样也可以用聚集函数来实现,首先用子查询找出 CS 系中最小年龄 (19) ,然后在父查询中查询所有非 CS 系且年龄小于 19 岁的学生。SQL语句如下:
select Sname, Sage
from Student
where Sdept != 'CS' and Sage < (
select min(Sage)
from Student
where Sdept = 'CS'
);
事实上,用聚集函数实现子查询,通常比直接用 any 或 all 查询效率要高。any/all 与聚集函数的对应关系如下表所示,其中 = any 等价于 in 谓词,< any 等价于 < max ,<> all 等价于 not in 谓词,< all 等价于 < min 等等:

4. 带有 exists 谓词的子查询
exists 代表存在量词
∃
\exists
∃ ,带有 exists 谓词的子查询不返回任何数据,只产生逻辑真值 true 或逻辑假值 false ——使用存在量词 exists 后,若内层查询结果非空,则外层的 where 子句返回真值,否则返回假值。与 exists 谓词相对应的是 not exists 谓词,使用存在量词 not exists 后,若内层查询结果为空,则外层的 where 子句返回真值,否则返回假值。
我们可以利用 exists 判断
x
∈
S
,
S
⊆
R
,
S
=
R
,
x\in S,\ S \subseteq R,\ S = R,
x∈S, S⊆R, S=R,
S
∩
R
S\cap R
S∩R 非空等是否成立。要注意的是,由 exists 引出的子查询,其目标列表达式通常都用 * ,因为带 exists 的子查询只返回真值或假值,给出列名无实际意义。
【例3.60】查询所有选修了
1
1
1 号课程的学生姓名。
答:本查询涉及 Student 和 SC 表。可以在 Student 中依次取每个元组的 Sno 值,用此值去检查 SC 表。若 SC 表中存在这样的元组,其 Sno 值等于此 Student.Sno 值,并且其 Cno = '1' ,则取此 Student.Sname 送入结果表。将此想法写成SQL语句是:
select Sname
from Student
where exists (
select *
from SC
where Student.Sno = Sno and Cno = '1'
);
/* 或者写成 */
select Sname
from Student, SC
where Student.Sno = SC.Sno and Cno = '1';
本例中,子查询的查询条件依赖于外层父查询的某个属性值(Student.Sno),因此也是相关子查询。这个相关子查询的处理过程是:首先去外层父查询中 Student 表的第一个元组,根据它与内层查询相关的属性值(Sno 值)处理内层查询,若 where 子句返回值为真,则取外层查询中该元组的 Sname 放入结果表;然后再取 Student 表的下一个元组;重复这一过程,直到外层 Student 表全部检查完为止。
【例3.61】查询没有选修
1
1
1 号课程的学生姓名。
答:
select Sname
from Student
where not exists (
select *
from SC
where Student.Sno = Sno and Cno = '1'
);
一些带 exists 或 not exists 谓词的子查询,不能被其他形式的子查询等价替代,但所有带 in 谓词、比较运算符、any/all 谓词的子查询,都能用带 exists 谓词的子查询等价替换。例如带有 in 谓词的【例3.55】(查询与“刘晨”在同一个系学习的学生)可用如下带 exists 谓词的子查询替换:
select Sno, Sname, Sdept /* 例3.55的解法四 */
from Student S1
where exists (
select *
from Student S2
where S2.Sdept = S1.Sdept and S2.Sname = '刘晨'
);
由于带 exists 量词的相关子查询,只关心内层查询是否有返回值,并不需要查具体值,因此其效率并不一定低于不相关子查询,有时反而是高效的方法。
【例3.62】查询选修了全部课程的学生姓名。
答:由于SQL中没有全称量词 for all ,只有存在量词 exists ,我们可以把带有全称量词的谓词转换为等价的带有存在量词的谓词,从而用 exists/not exists 来实现带全称量词的查询:
∀
x
P
⇔
¬
∃
x
(
¬
P
)
\forall x P \Lrarr \lnot \exists x(\lnot P)
∀xP⇔¬∃x(¬P)
由于没有全称量词,可将题目的意思转换成等价的用存在量词的形式:查询这样的学生,不存在一门课程是他不选修的。其SQL语句如下:
select Sname
from Student
where not exists (
select *
from Course
where not exists (
select *
from SC
where Sno = Student.Sno and Cno = Course.Cno
)
);
【例3.63】查询至少选修了学生 201215122 选修的全部课程的学生号码。
答:本查询可用逻辑蕴含来表示:查询学号为 x 的学生,对所有的课程 y ,只要 201215122 学生选修了课程 y ,则 x 也选修了 y 。形式化表达:用
P
(
y
)
P(y)
P(y) 表示谓词“学生 201215122 选修了课程 y”,用
Q
(
x
,
y
)
Q(x, y)
Q(x,y) 表示谓词“学生 x 选修了课程 y” 。则上述查询为:
∀
y
(
P
(
y
)
→
Q
(
x
,
y
)
)
\forall y(P(y) \to Q(x, y))
∀y(P(y)→Q(x,y))
由于SQL语言中没有蕴含 implication 逻辑运算,我们可以利用谓词演算,将一个逻辑蕴含的谓词等价转换为:
P
(
y
)
→
Q
(
x
,
y
)
⇔
¬
P
(
y
)
∨
Q
(
x
,
y
)
P(y) \to Q(x, y) \Lrarr \lnot P(y) \lor Q(x, y)
P(y)→Q(x,y)⇔¬P(y)∨Q(x,y) 从而将上述查询转换为如下等价形式:
∀
y
(
P
(
y
)
→
Q
(
x
,
y
)
)
⇔
∀
y
(
¬
P
(
y
)
∨
Q
(
x
,
y
)
)
⇔
∀
y
(
¬
(
P
(
y
)
∧
¬
Q
(
x
,
y
)
)
)
⇔
¬
∃
y
(
P
(
y
)
∧
¬
Q
(
x
,
y
)
)
\begin{aligned} &\forall y(P(y) \to Q(x, y)) \\ \Lrarr\ &\forall y\ (\lnot P(y) \lor Q(x, y)) \\ \Lrarr\ &\forall y\ (\lnot (P(y) \land\lnot Q(x, y))) \\ \Lrarr\ & \lnot \exists y\ (P(y) \land\lnot Q(x, y)) \end{aligned}
⇔ ⇔ ⇔ ∀y(P(y)→Q(x,y))∀y (¬P(y)∨Q(x,y))∀y (¬(P(y)∧¬Q(x,y)))¬∃y (P(y)∧¬Q(x,y))
它表达的语义是:不存在这样的课程 y ,学生 201215122 选修了 y ,而学生 x 没有选修。用SQL语言表示如下:
select distinct Sno
from SC SCX
where not exists (
select *
from SC SCY
where SCY.Sno = '201215122' and not exists (
select *
from SC SCZ
where SCZ.Sno = SCX.Sno and SCZ.Cno = SCY.Cno
)
);
3.4.4 集合查询
select 语句的查询结果是元组的集合,所以多个 select 语句的结果可进行集合操作,集合操作主要包括并操作 union 、交操作 intersect 和差操作 except 。注意,参加集合操作的各查询结果的列数必须相同,对应项的数据类型也必须相同。注意,使用 union 将多个查询结果合并起来时,系统会自动去掉重复元组。如果要保留重复元组,则用 union all 操作符。
【例3.64】查询计算机科学系的学生及年龄不大于
19
19
19 岁的学生。
答:本例实际上是求计算机科学系的学生,以及年龄不大于
19
19
19 岁的学生的并集。
select *
from Student
where Sdept = 'CS'
union
select *
from Student
where Sage <= 19;
【例3.65】查询选修了课程
1
1
1 或选修了课程
2
2
2 的学生。
答:本例即,查询选修课程
1
1
1 的学生集合与选修课程
2
2
2 的学生集合的并集。
select *
from SC
where Cno = '1'
union
select *
from SC
where Cno = '2';
【例3.66】查询计算机科学系的学生与年龄不大于
19
19
19 岁的学生的交集。
答:
select *
from Student
where Sdept = 'CS'
intersect
select *
from Student
where Sage <= 19;
本例实际上就是查询计算机科学系中年龄不大于 19 19 19 岁的学生。
select *
from Student
where Sdept = 'CS' and Sage <= 19;
【例3.67】查询既选修了课程
1
1
1 又选修了课程
2
2
2 的学生。
答:本例即,查询选修课程
1
1
1 的学生的集合与选修课程
2
2
2 的学生的集合的交集。
select Sno
from SC
where Cno = '1'
intersect
select Sno
from SC
where Cno = '2';
本例也可以表示为:
select Sno
from SC
where Cno = '1' and Sno in (
select Sno
from SC
where Cno = '2'
);
【例3.68】查询计算机科学系的学生与年龄不大于
19
19
19 岁的学生的差集。
答:
select *
from Student
where Sdept = 'CS'
except
select *
from Student
where Sage <= 19;
本例实际上就是查询计算机科学系中年龄大于 19 19 19 岁的学生。
select *
from Student
where Sdept = 'CS' and Sage > 19;
3.4.5 基于派生表的查询
子查询不仅可以出现在 where 子句和 having 短语中,还可以出现在 from 子句中,此时子查询生成的临时派生表 derived table 成为主查询的查询对象。需要说明的是,通过 from 子句生成派生表时,as 关键字可省略,但必须为派生关系指定一个别名;而对于基本表,别名是可选择项。此外,如果子查询中没有聚集函数,派生表可以不指定属性列的别名,子查询 select 子句后面的列名为其默认属性列名。
比如,【例3.57】找出每个学生超过他自己选修课程平均成绩的课程号,也可以用如下的查询完成:
select Sno, Cno
from SC, (
select Sno, avg(Grade)
from SC
group by Sno
) as Avg_sc(avg_sno, avg_grade)
where SC.Sno = Avg_sc.avg_sno and SC.Grade >= Avg_sc.avg_grade;
这里的 from 子句中的子查询将生成一个派生表 Avg_sc ,该表由 avg_sno, avg_grade 两个属性组成,记录了每个学生的学号及平均成绩。主查询将 SC 表与 Avg_sc 按学号相等进行连接,选出修课成绩大于其平均成绩的课程号。
再例如【例3.60】查询所有选修了 1 1 1 号课程的学生姓名,可以用如下查询完成:
select Sname
from Student, (
select Sno
from SC
where Cno = '1'
) as SC1
where Student.Sno = SC1.Sno;
3.4.6 SELECT语句的一般格式
select 语句是SQL的核心语句,从前面的例子可以看到,其语句成分丰富多样。下面总结一下它的一般格式。
select 语句的一般格式:
select [ all | distinct ] <目标列表达式> [别名] [, <目标列表达式> [别名]] ...
from <表名或视图名> [别名] [, <表名或视图名> [别名]] ... | ( <select语句> ) [as] <别名>
[where <条件表达式>]
[group by <列名1> [ having <条件表达式> ]]
[order by <列名2> [ asc | desc ]];
1. 目标列表达式的可选格式
有以下四种:
*;<表名>.*;count( [ distinct | all ] *);[<表名>.]<属性列名表达式> [, [<表名>.]<属性列名表达式>] ...,其中,<属性列名表达式>可以是由「常量、属性列、作用于属性列的聚集函数」之间的任意算术运算+, -, *, /组成的运算公式。
2. 聚集函数的一般格式
{ count sum avg max min } ( [ distinct ∣ all ] ⟨ 列名 ⟩ ) \begin{Bmatrix} \text{count} \\ \text{sum} \\ \text{avg} \\ \max \\ \min \\ \end{Bmatrix} (\ [\ \text{distinct} \mid \text{all}\ ]\ \langle \text{列名} \rangle\ ) ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧countsumavgmaxmin⎭⎪⎪⎪⎪⎬⎪⎪⎪⎪⎫( [ distinct∣all ] ⟨列名⟩ )
3. WHERE子句的条件表达式的可选格式
(1)其中的
θ
\theta
θ 是比较运算符:
⟨
属
性
列
名
⟩
θ
{
⟨
属
性
列
名
⟩
⟨
常
量
⟩
[
all
∣
any
]
(
select
语
句
)
}
\langle 属性列名 \rangle \ \theta \begin{Bmatrix} \langle 属性列名 \rangle \\ \langle 常量 \rangle \\ [\ \text{all} \mid \text{any}\ ]\ (\ \text{select} 语句\ ) \end{Bmatrix}
⟨属性列名⟩ θ⎩⎨⎧⟨属性列名⟩⟨常量⟩[ all∣any ] ( select语句 )⎭⎬⎫
(2)(不)介于……和……之间:
⟨
属
性
列
名
⟩
[
not
]
between
{
⟨
属
性
列
名
⟩
⟨
常
量
⟩
(
select
语
句
)
}
and
{
⟨
属
性
列
名
⟩
⟨
常
量
⟩
(
select
语
句
)
}
\langle 属性列名 \rangle \ [\ \text{not} \ ] \text{ between } \begin{Bmatrix} \langle 属性列名 \rangle \\ \langle 常量 \rangle \\ (\ \text{select} 语句\ ) \end{Bmatrix} \text{and} \begin{Bmatrix} \langle 属性列名 \rangle \\ \langle 常量 \rangle \\ (\ \text{select} 语句\ ) \end{Bmatrix}
⟨属性列名⟩ [ not ] between ⎩⎨⎧⟨属性列名⟩⟨常量⟩( select语句 )⎭⎬⎫and⎩⎨⎧⟨属性列名⟩⟨常量⟩( select语句 )⎭⎬⎫
(3)(不)在……之中:
⟨
属
性
列
名
⟩
[
not
]
in
{
(
⟨
值
1
⟩
[
,
⟨
值
2
⟩
]
…
)
(
select
语
句
)
}
\langle 属性列名 \rangle \ [\ \text{not} \ ] \text{ in } \begin{Bmatrix} (\ \langle 值1\rangle \ [,\ \langle 值2\rangle \ ] \dots \ ) \\ (\ \text{select}语句\ ) \end{Bmatrix}
⟨属性列名⟩ [ not ] in {( ⟨值1⟩ [, ⟨值2⟩ ]… )( select语句 )}
(4)(不)像:
⟨
属
性
列
名
⟩
[
not
]
like
⟨
匹
配
串
⟩
\langle 属性列名\rangle \ [\ \text{not}\ ]\ \text{like}\ \langle 匹配串\rangle
⟨属性列名⟩ [ not ] like ⟨匹配串⟩
(5)为空:
⟨
属
性
列
名
⟩
is
[
not
]
null
\langle 属性列名\rangle \ \text{is}\ [\ \text{not}\ ]\ \text{null}
⟨属性列名⟩ is [ not ] null
(6)(不)存在:
[
not
]
exists
(
select
语
句
)
[\ \text{not}\ ]\ \text{exists}\ (\ \text{select} 语句\ )
[ not ] exists ( select语句 )
(7)条件表达式:
⟨
条
件
表
达
式
⟩
{
and
or
}
⟨
条
件
表
达
式
⟩
[
{
and
or
}
⟨
条
件
表
达
式
⟩
]
…
\langle 条件表达式 \rangle \ \begin{Bmatrix} \text{and} \\ \text{or} \\ \end{Bmatrix} \langle 条件表达式 \rangle \ \bigg[ \begin{Bmatrix} \text{and} \\ \text{or} \\ \end{Bmatrix} \langle 条件表达式 \rangle \bigg ] \dots
⟨条件表达式⟩ {andor}⟨条件表达式⟩ [{andor}⟨条件表达式⟩]…



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











