



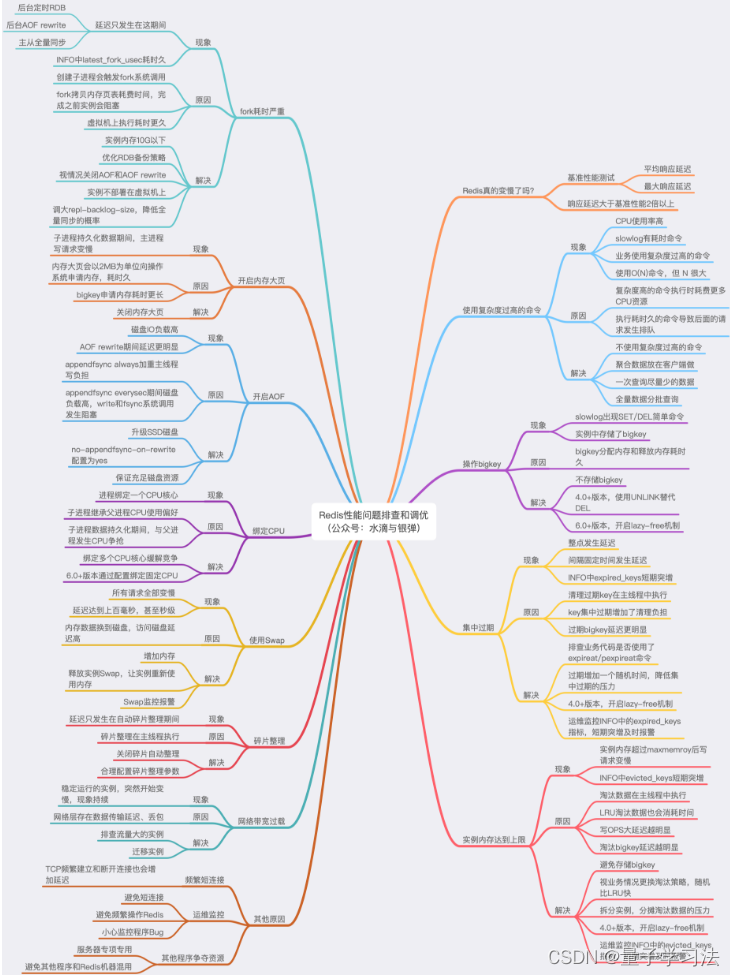
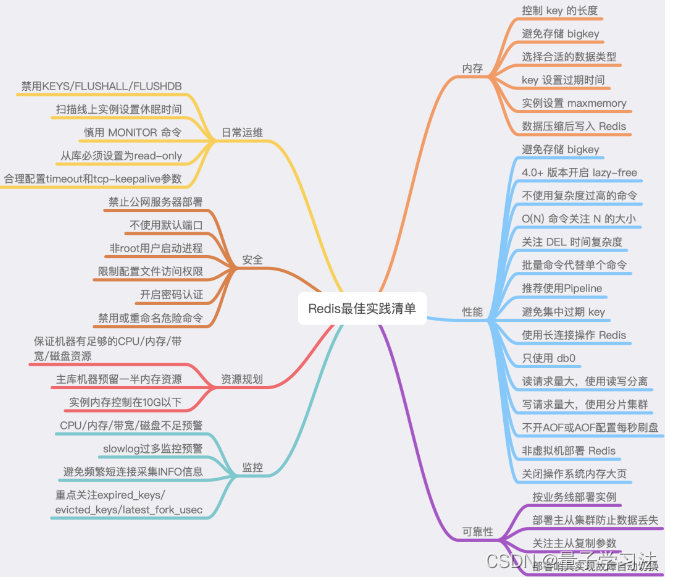
 文章深入探讨了Redis性能下降的原因,包括CPU资源消耗过高、内存管理问题(如bigkey和内存碎片)、数据持久化对磁盘的影响、网络连接负载以及操作系统层面的因素如写时复制和内存配置。提供了从多个维度排查和解决Redis性能问题的思路。
文章深入探讨了Redis性能下降的原因,包括CPU资源消耗过高、内存管理问题(如bigkey和内存碎片)、数据持久化对磁盘的影响、网络连接负载以及操作系统层面的因素如写时复制和内存配置。提供了从多个维度排查和解决Redis性能问题的思路。
-
CPU 相关:使用复杂度过高命令、O(N)的这个N,数据的持久化,都与耗费过多的 CPU 资源有关
-
内存相关:bigkey 内存的申请和释放、数据过期、数据淘汰、碎片整理、内存大页、内存写时复制都与内存息息相关
-
磁盘相关:数据持久化、AOF 刷盘策略,也会受到磁盘的影响
-
网络相关:短连接、实例流量过载、网络流量过载,也会降低 Redis 性能
-
计算机系统:CPU 结构、内存分配,都属于最基础的计算机系统知识
-
操作系统:写时复制、内存大页、Swap、CPU 绑定,都属于操作系统层面的知识
参考文献

















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









