




1. 引言
本文介绍了一种(在众多方法中的一种)用于 嵌入式系统消息序列化 的方法。
该方法基于 Google 的 protobuf 序列化格式,并在其基础上加入了 转义(escaping) 和 帧封装(framing),以便数据可以通过如 UART、SPI、WebSocket 或任何其他“字节流”式通信通道进行传输。
2. Schema 与无 Schema 序列化的比较
在嵌入式系统中,使用 “基于 Schema 的序列化格式” 还是 “无 Schema 的格式” 更好?
Geoffrey Hunter通常认为基于 Schema 的格式更适合嵌入式系统,原因如下:
- 1)它允许在嵌入式代码中创建与 Schema 相匹配的结构体(struct)或类(class),这些结构可用于序列化和反序列化消息。
如果没有这些 Schema 定义的结构体,就难以在不使用动态内存分配的情况下(许多嵌入式系统在运行时会避免动态分配)表达这些数据。 - 2)Schema 提供了一种定义和记录设备间消息“API”的方式。
在强类型语言中,这能显著改善开发体验,因为消息类型可以对应到包含字段的对象。
.proto文件中的类型、变量名和注释也可作为 API 的文档(也可以从.proto文件生成正式文档,如 pseudomuto/protoc-gen-doc)。
基于 Schema 的序列化格式包括:
- protobuf
- Cap’n Proto
- 和 FlatBuffers。
无 Schema 的序列化格式包括:
- JSON
- CBOR
- 和 MessagePack。
3. protobuf
将使用 protobuf 将计算机内存中的对象转换为字节流(即所谓的序列化过程)。
protobuf 是一种由 Google 开发的 基于 Schema 的二进制序列化格式,是目前最流行的序列化方案之一。
消息的 Schema(定义)存放在 .proto 文件中。
protobuf 官方支持 C++、Java、Python 等语言,但 不官方支持 C!
幸运的是,有一个广受欢迎的第三方工具 Nanopb 为 C 提供了支持,并且非常适合在嵌入式系统中使用。
对于每种语言,protobuf 包含两个主要部分:
- 1)编译器:将
.proto文件编译为目标语言中的对象,每个消息都会对应一个结构或类。 - 2)运行时库:提供用于序列化和反序列化消息的函数。
protobuf 会将消息中的每个变量编码为一个 标签(tag)(即唯一的变量 ID)以及变量的值。
有人可能会认为为每个变量添加标签是一种浪费——为什么不直接按顺序发送变量并省下那些标签占用的字节呢?
原因在于这能实现:
- 向前兼容和向后兼容。
- 标签允许新版本的代码接收旧格式的消息并为缺失字段创建默认值;
- 旧版本的代码则可以接收新消息并忽略它不认识的字段。
- 此外,这种机制还允许字段是可选的,并且在字段值为默认值时可以选择不发送。
下面来看一个简单示例来理解 protobuf 的工作原理。
以下是一个最基础的 .proto 文件:
message myMessage {
uint32 myInt = 1;
}

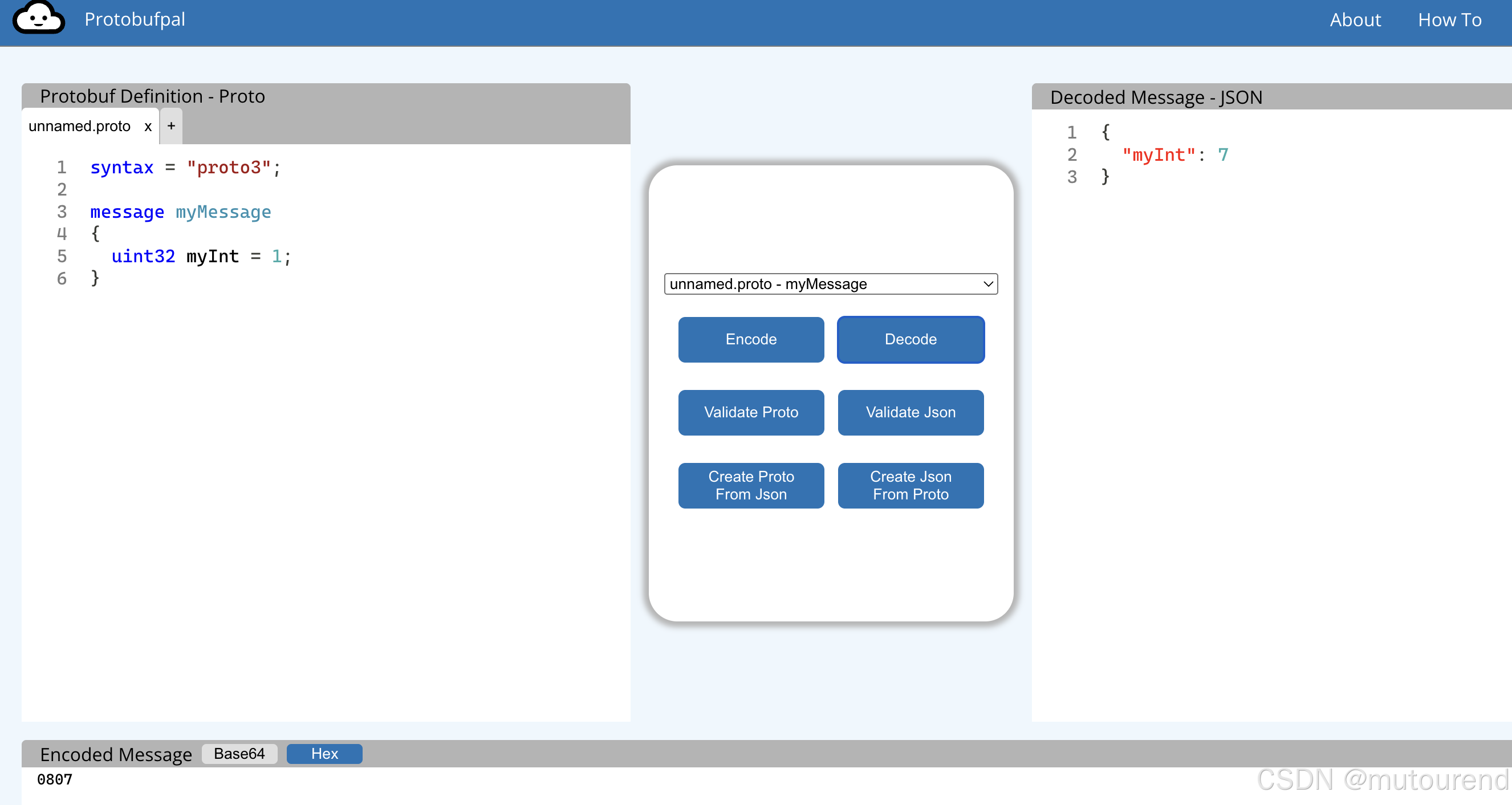
将 myInt 设为 7。编码结果如下(使用 https://www.protobufpal.com/ 生成):
08 07
第一个字节 0x08 是标签(tag)左移 3 位后的结果(即 1 << 3)。
可以通过将标签改为 2 来验证这一点,此时第一个字节会变为 0x10(若标签为 3,则为 0x18,以此类推)。
第二个字节 0x07 则是变量的实际值。
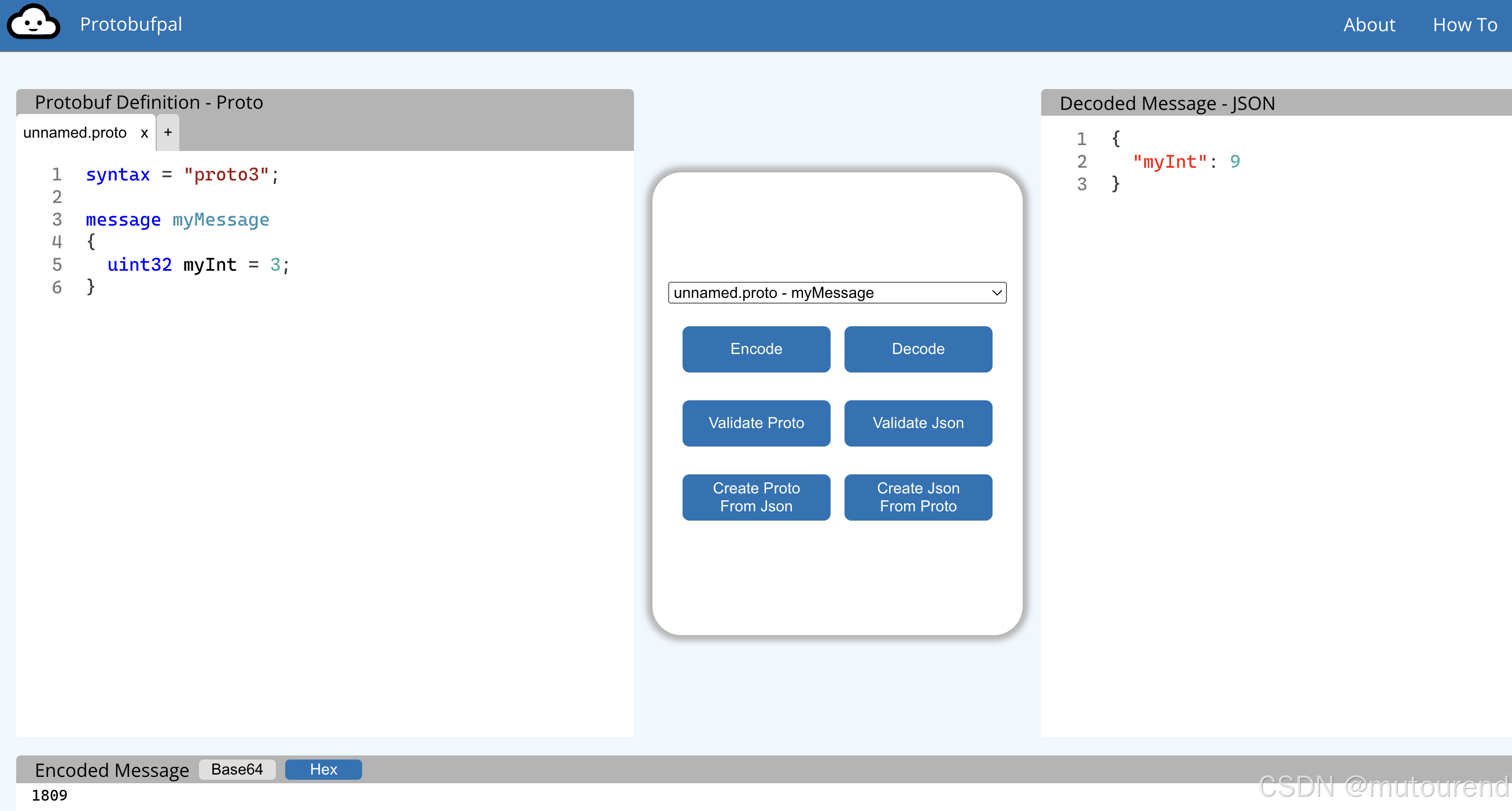
uint32 是一种 可变长度(variable-width) 类型(注意,protobuf 中并没有 uint8 或 uint16)。
对于不超过 127 的 uint32,protobuf 使用 2 个字节进行编码(1 个字节用于标签及元信息,另 1 个字节用于数值本身)。
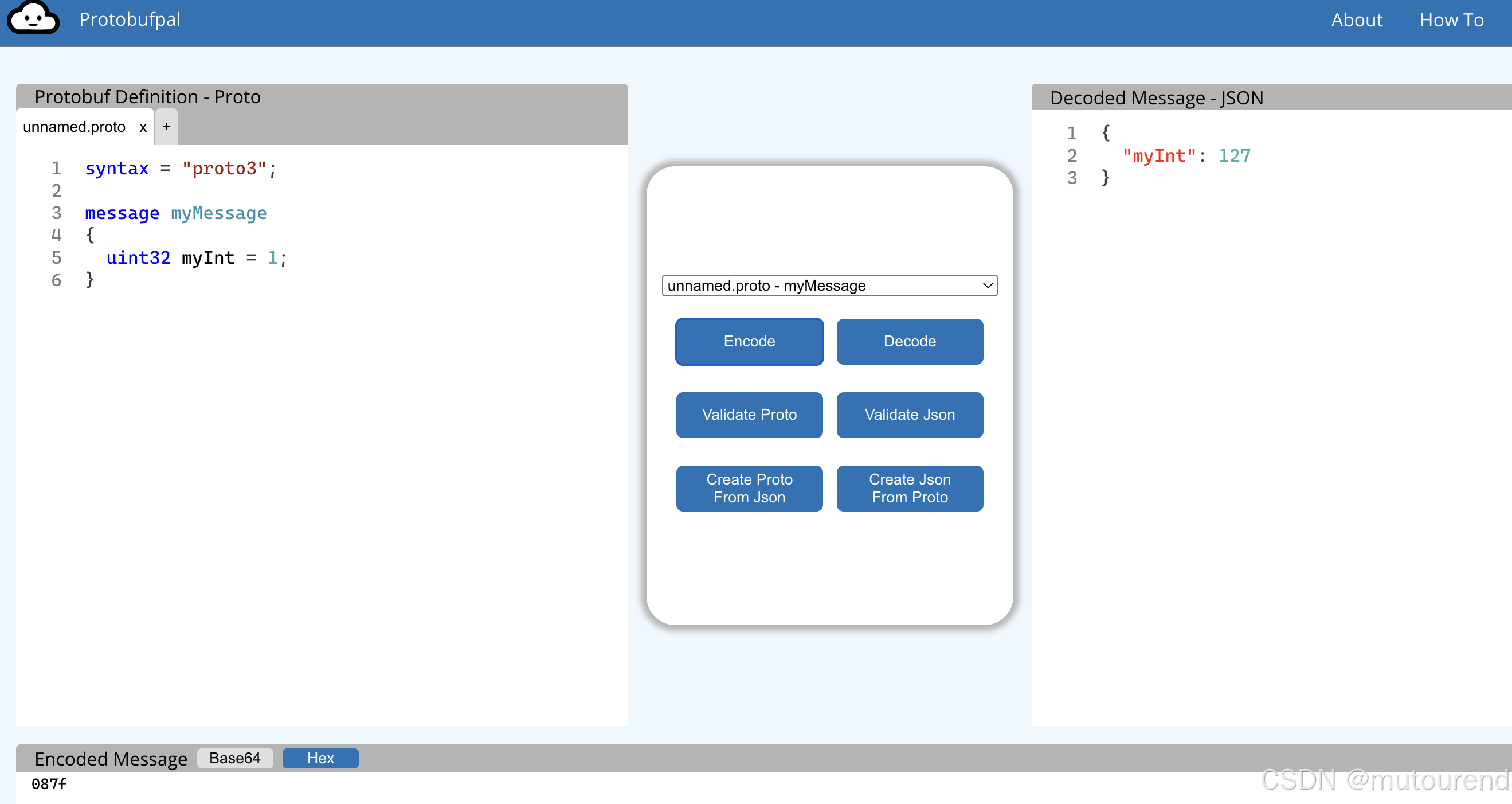
当数值为 128 时,编码需要 3 个字节:
Value Encoded Msg.
7 08 07
127 08 7F
128 08 80 01
protobuf 支持许多在嵌入式系统中很实用的数据类型,如:
- string:可用于序列化任意长度的
char*字符串。 - bytes:可用于序列化二进制数据。
- repeated:可用于序列化任意长度的数组(即重复字段)。
protobuf 在嵌入式系统中的一个 缺点 是缺乏小数据类型。
它提供了 uint32 和 bytes(字节数组)类型,但没有 uint8、uint16 或位域(bit fields)!
不过,protobuf 的编码方式非常聪明——它会对小的 uint32 值使用少于 4 个字节进行编码(如上例所示)。
然而,这仍然缺乏小类型的表达力。
在使用 Nanopb 时,默认情况下所有的 uint32 字段都会映射为结构体中的 uint32_t 类型,
这可能会造成部分用户的内存问题。
幸运的是,Nanopb 提供了一种方法,可以在 .proto 文件中指定更小的数据类型,从而使生成的结构体使用较小类型(若解码时收到的数值无法容纳于较小类型中,则会抛出错误)。
如果“小数据类型缺失”对你来说是致命问题,可以看看 bitproto(https://github.com/hit9/bitproto(C+Python))(详见下文 “替代方案” 部分)。
protobuf 只要满足以下两个条件,就能将接收到的字节流正确解码为消息:
- 1)你知道消息的类型;
- 2)你提供的字节流与创建消息时的编码字节完全一致。
这在通过 UART 等流式通信通道 传输字节时会引出两个问题:
- 1)如果你要发送多种类型的消息,如何知道当前消息的类型?
- 2)如何区分一条消息的结束和下一条消息的开始?
4. Protobuf 默认值
protobuf 不会发送被设置为默认值的字段。
在 proto3 语法中,也无法设置自定义默认值(这样设计是为了多语言间的可移植性)。
protobuf 使用以下默认值:
uint32,int32,sint32,fixed32,sfixed32:0bool:falsestring,bytes,repeated: 长度为 0 的数组enum: 枚举的第一个值(在proto3中总是 0)message: Language-specific语言相关的null表示
因此,在设计逻辑时若依赖于“字段是否存在”,需要特别小心。
默认情况下,除了 message 类型(即非标量类型)之外,你无法区分 一个字段是被显式设置为默认值,还是根本没有被赋值。
message 类型则不同:
- 如果未赋值,它将被设置为
null。
protobuf 提供了 optional 修饰符,以便于检测标量类型字段的存在性。
在这种情况下,即使字段被设置为默认值,protobuf 也会将其编码发送。
编码器如何判断字段被设置过取决于具体语言实现。
在解码端,protobuf 提供语言特定的 API 来判断字段是否被设置,以及其值。
5. 消息类型(The Message Type)
关于“如何在接收端知道消息类型”这个问题,有几种常见的解决方法:
- 1)使用 枚举(enum) 来定义消息类型,并在每个消息中附带该类型字段;
- 2)使用一个 “包装(wrapper)”消息,其中包含一个
oneof字段,用于表示所有可能的消息类型(推荐此方案)。
在高级语言中,这类问题可以通过 RPC 客户端 机制解决。
对于 protobuf 而言,gRPC 是最自然的选择——它构建在 protobuf 之上,并在 .proto 文件中同时定义了 RPC 接口与消息。
不过,这种方式不太适合低层嵌入式系统,因为 gRPC 的服务端与客户端都相对臃肿。
也有面向嵌入式的轻量级 RPC 库,如 eRPC,但它们的生态支持程度远不如 protobuf 在高层语言中的成熟度。
5.1 枚举(enum)方法
一种解决方案是使用 enum(枚举) 来定义消息类型,然后将其与消息一同发送(如,在消息前的 header(消息头) 中,稍后会更详细地介绍消息头的结构)。
下面是在 .proto 文件中的一个示例:
enum MessageType {
HelloMessage = 1;
GoodbyeMessage = 2;
}
message HelloMessage {
string greeting = 1;
}
message GoodbyeMessage {
string greeting = 1;
}
5.2 oneof 方法
另一种方式是使用 protobuf 的 oneof 功能,创建一个“包装(wrapper)消息”,其中包含一个 oneof 字段,代表所有可能被发送的消息类型。
oneof 允许你定义一个字段,该字段可以是多种不同类型之一(可以将其类比为 C 语言中的 union)。
下面是在 .proto 文件中的示例:
message HelloMsg {
string greeting = 1;
}
message GoodbyeMsg {
string greeting = 1;
}
message WrapperMsg {
oneof innerMsg {
HelloMsg helloMsg = 1;
GoodbyeMsg goodbyeMsg = 2;
}
}
在底层,protobuf 会为 oneof 字段中的每种可能消息编码一个 ID(使用标签号 tag number),
并在生成的代码中提供接口来判断当前是哪种类型的消息。
从某种意义上讲,这种方法与上面的 enum 方法 类似,区别在于这里 protobuf 自动生成并在消息中包含该“枚举”,而不是由你手动在消息头中定义。
这种“包装消息(wrapped message)”的另一个好处是——你可以向该包装层添加通用字段,这些字段将自动出现在所有消息中。
如:
- 可以在其中添加一个 时间戳(timestamp) 或 CRC 校验码(checksum) 字段,非常实用。
6. 转义与分帧(Escaping and Framing)
protobuf 本身无法确定一条消息何时结束,下一条消息何时开始。
这对于需要以stream-like流式方式(如通过 UART)发送数据时是个问题。
解决方案是:
- 对 protobuf 编码后的消息进行进一步处理,通过添加一个 特定的“包结束符”(end-of-packet delimiter) 来实现分帧。
- 同时,还需要确保消息中若包含该结束符,则对其进行转义(escape)。
这一过程称为 “转义与分帧(escaping and framing)”。
如,你可以选择 0xFE 作为包结束符(建议避免使用常见字节,如 0x00 或 0xFF,以减少需要转义的次数)。
同时,也可以选择一个 包起始符(start-of-packet delimiter),这不是必须的,但当在数据流中“半途连接”到另一设备时,它能帮助更容易地丢弃无效数据。这里选择 0xFD 作为起始符。
最后,还需要选择一个 转义字符(escape character),如 0xFC。
然后在编码(encoding)阶段:
- 每当遇到包结束符
0xFE,将其替换为0xFC 0x00。 - 每当遇到包起始符
0xFD,将其替换为0xFC 0x01。 - 每当遇到转义字符
0xFC,将其替换为0xFC 0x02(即对转义字符本身进行转义)。
经过这样的处理后,消息中将不会再出现 0xFE 或 0xFD,这样就可以安全地在消息前后分别添加这些字节,作为唯一的包起始符(SOP)和包结束符(EOP)。
如,假设有以下 protobuf 编码后的消息:
0x08 0xFE 0x01 0xFC 0xAA
经过转义(escaping)后:
0x08 0xFC 0x00 0x01 0xFC 0x02 0xAA
然后进行分帧(framing):
|<- SOP |<- EOP
0xFD 0x08 0xFC 0x00 0x01 0xFC 0x02 0xAA 0xFE
这就是发送端在通信通道(如 UART、SPI 等)上传输的完整字节序列。
6.1 接收端该怎么做?
接收端该怎么做?
- 接收端会丢弃所有字节,直到遇到包起始符(SOP)。
- 然后它会缓存后续的字节,直到接收到包结束符(EOP)。
- 接着执行反转义(unescaping)操作,恢复原始的 protobuf 编码消息。
如果使用了前面提到的 oneof 方法,这条消息随后就可以通过 protobuf 解码。
如果使用的是 enum 方法 来区分消息类型,则需要在执行转义与分帧前,将消息类型添加到 protobuf 编码消息的开头。
- 在解码时,需要先解析这个消息类型字段,然后调用对应的解码函数。
另外,也可以选择在消息头中添加一个 CRC 校验码(checksum),以验证消息完整性。
- 通常应当对“protobuf 编码后的消息”和“消息类型枚举值(如果使用)”一起计算 CRC。
提示:
如果担心转义操作会导致消息长度显著增加,可以了解一下 COBS(Constant Overhead Byte Stuffing)。
* 它是一种更巧妙的转义与分帧方法,每 254 个数据字节的最大小幅开销仅为 1 个字节。
7. Nanopb
Nanopb 是一个在 C/嵌入式系统 中使用 protobuf 的流行库。
Nanopb 允许在 .proto 文件中添加额外的信息,以便在为 C 编译时帮助生成结构体(struct)。
这对于诸如 string、repeated 和 bytes 这类可变长度字段尤其有用。
- 如果不指定额外信息,Nanopb 会期望你使用 回调(callback) 的方式处理数据流。
- 相比之下,使用固定大小成员的结构体更方便,因此除非有特别的理由,否则强烈建议显式指定这些额外选项。
首先,需要在 .proto 文件中添加:
import "nanopb.proto";
7.1 Nanopb 选项(Nanopb Options)
Nanopb 提供了一些可以在 .proto 文件中使用的特殊选项,这些选项的作用包括:
- 避免动态内存分配;
- 避免使用回调;
- 通过允许小于 32 位的字段来减小结构体内存占用;
- 让 Nanopb 生成固定大小结构体来保存消息数据。
这些额外的选项不会妨碍将 .proto 文件编译为 Python 等其他语言使用,但必须确保 nanopb.proto 文件是可导入的,
即使这些选项在目标语言中会被忽略,详情见 Nanopb: API reference。
安装 Nanopb 后,还会提供一个版本的 protoc(官方 protobuf 编译器),可直接使用。
Nanopb 选项(Nanopb Options)有:
-
1)用于
bytes的max_size
可以使用max_size选项来指定一个bytes字段的最大大小:message Image { bytes data = 1 [(nanopb).max_size = 256]; }Nanopb 将为该字段生成一个包含 256 字节数据区 的结构体:
typedef PB_BYTES_ARRAY_T(256) BinaryData_data_t; typedef struct _BinaryDataSet { BinaryData_data_t data; } BinaryData; -
2)用于
repeated的max_count
可以使用max_count选项来指定一个repeated字段的最大元素数量:/* 表示一个 x, y 笛卡尔坐标点 */ message Point { float x = 1; // x 坐标,范围 [0, 1] float y = 2; // y 坐标,范围 [0, 1] } message PointsArray { repeated Point points = 1 [(nanopb).max_count = 10]; }Nanopb 会为
points字段生成一个包含 10 个元素的数组结构体,
并添加一个points_count字段,用于记录数组中当前有效元素的数量:typedef struct _Point { uint32_t x; /* x 坐标,范围 [0, 1] */ uint32_t y; /* y 坐标,范围 [0, 1] */ } Point; typedef struct _PointsArray { pb_size_t points_count; Point points[10]; } PointsArray; -
3)用于
string的max_length
可以使用max_length选项来设置字符串字段的最大长度:message HelloMsg { string text = 1 [(nanopb).max_length = 40]; // 消息文本内容 }Nanopb 会为
text字段生成一个长度为 41 的char数组(额外的+1用于存放字符串的空终止符\0):typedef struct _HelloMsgSet { char text[41]; } HelloMsg;字符串字段不需要单独记录长度,因为其长度由结尾的空字符自动确定。
-
4)
int_size
可以使用 Nanopb 的int_size选项(如IS_8、IS_16等)来指定生成结构体中整数字段的确切大小。
标准的.proto语法不允许定义小于 32 位的整型(尽管在传输时,小整数仍会被压缩为更少的字节)。
这个选项允许在生成的结构体中使用更小的整数类型,从而节省 MCU 上宝贵的 RAM,尤其适用于repeated字段。import "nanopb.proto"; message Frame { uint32 my_number = 1 [(nanopb).int_size = IS_8]; // 这会在结构体中生成一个 uint8_t。 int32 my_other_number = 2 [(nanopb).int_size = IS_16]; // 这会在结构体中生成一个 int16_t。 }在使用
IS_8、IS_16等选项时,整型的有符号性会保持一致(如uint32→uint8_t,int32→int8_t)。int_size选项支持以下类型:IS_DEFAULT:根据 protobuf 类型,默认为 32 位或 64 位。IS_8:uint8_t或int8_t。IS_16:uint16_t或int16_t。IS_32:uint32_t或int32_t。IS_64:uint64_t或int64_t。
8. 生成 Python 代码
官方 protobuf 编译器生成的 Python 代码非常糟糕。
它会将一个巨大的字符串嵌入到 Python 文件中,并在运行时动态生成类。
这意味着无法直接查看或智能提示消息类结构,IDE 也无法提供类型提示。
幸运的是,有更好的替代方案。
https://github.com/danielgtaylor/python-betterproto(Python) 是一个很受欢迎的工具,截至 2024 年 5 月已有 1.4k 颗星。
- 它能从
.proto文件中生成真正的 Python 数据类(dataclass),而不是运行时动态生成的类。 - 此外,它还支持 gRPC(虽然在嵌入式开发中不太常用)。
9. 替代方案——bitproto 和 zcbor
bitproto(https://github.com/hit9/bitproto(C+Python)) 是一种类似 protobuf 的序列化格式,它允许在比特级别上指定变量宽度,从而克服了 protobuf 在小数据类型定义上的一些限制。
bitproto使用与 protobuf 类似的文件格式来描述消息。
https://github.com/NordicSemiconductor/zcbor(C+Python) 是一个用 C(兼容 C++)编写的 CBOR 库,通过 CDDL 定义消息结构,相当于为 CBOR 提供了“模式(schema)”功能。
zcbor可以从这些模式中自动生成 C/C++ 代码。
截至 2024 年 5 月,该库在 GitHub 上已有 100 颗星。
参考资料
[1] Geoffrey Hunter 2024年10月博客 Serialization for Embedded Systems

















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









