




 本文详细介绍了在Linux环境下搭建Hadoop集群的前期准备工作,包括修改主机名、配置IP、主机映射、创建hadoop用户、关闭防火墙和Selinux、设置启动级别为3、安装JDK、克隆虚拟机、时间同步和SSH免密登录等关键步骤,适用于不同Linux技能水平的读者。
本文详细介绍了在Linux环境下搭建Hadoop集群的前期准备工作,包括修改主机名、配置IP、主机映射、创建hadoop用户、关闭防火墙和Selinux、设置启动级别为3、安装JDK、克隆虚拟机、时间同步和SSH免密登录等关键步骤,适用于不同Linux技能水平的读者。
本系列文章,通用性较强。
不管略懂linux命令的,或者是忘记hadoop搭建细节的,都可以参考本文章。
环境准备:
电脑系统:Windows10
vmware虚拟机:
操作系统:CentOS6.7
linux用户:root用户
JDK:jdk8.0,linux、windows系统JDK
1、修改各服务器的主机名
vi /etc/sysconfig/network
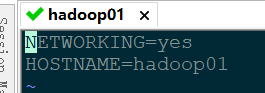
按一下i(进入编辑模式),然后写完按esc(进入命令模式),输入:wq(保存并退出)即可!
2、配置各服务器的IP(本文中相对最难)
Linux 服务器的 IP 修改方式有三种:1.桌面版,2.命令行,3.安装系统时。
命令行式修改IP 这位作者写的很详细。
我的IP修改为了192.168.110.111
当然,我们在修改IP之前还需要在VMware上进行这些操作:
1)点击编辑-->虚拟网络编辑器
2)会弹出下面的框。
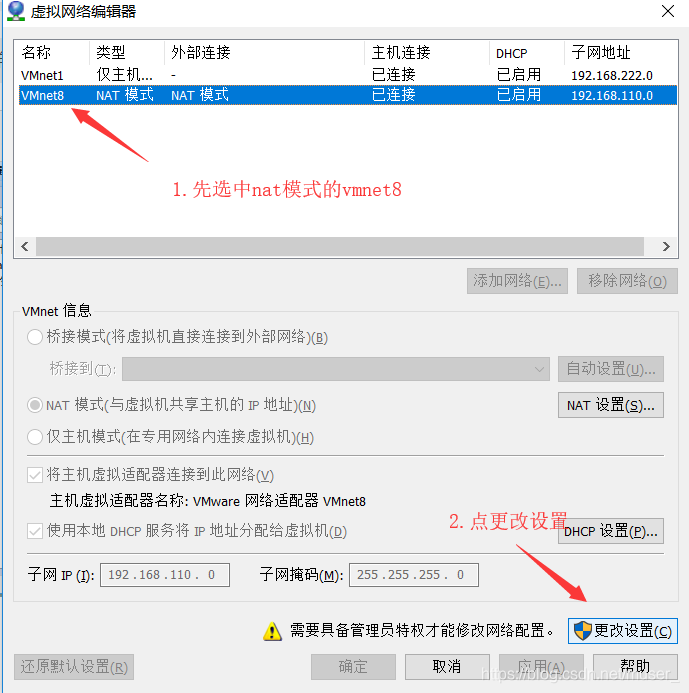
3)再弹(查看windows的IP方法:win+R-->cmd-->ipconfig)
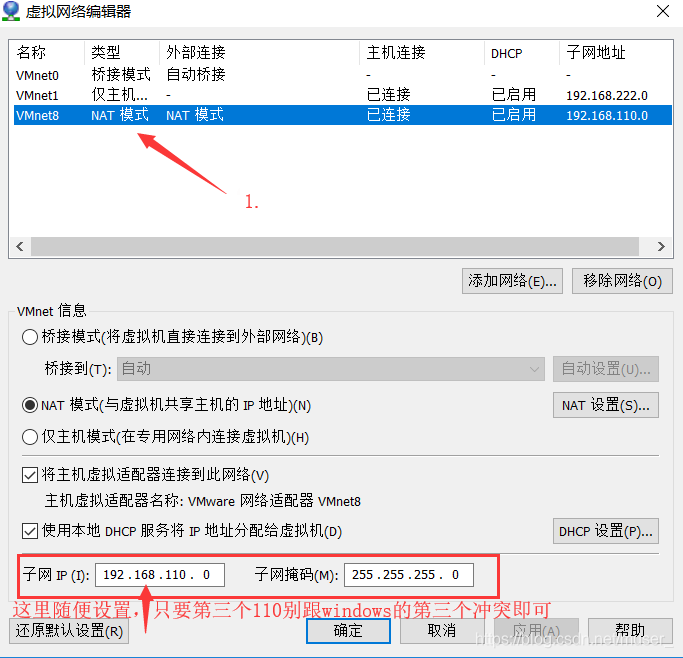
3、配置各服务器的主机映射
vi /etc/hosts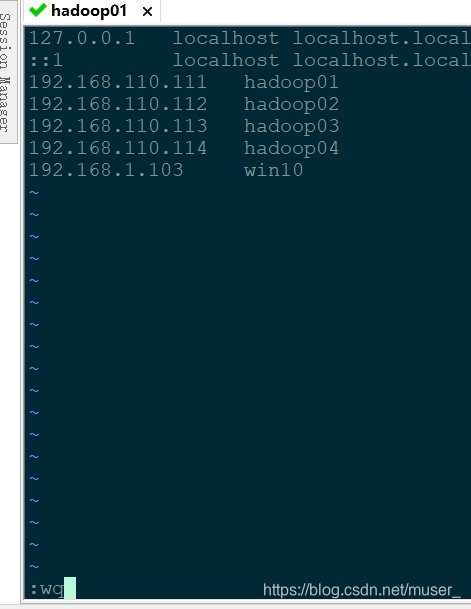
192.168.110.111 hadoop01
192.168.110.112 hadoop02
192.168.110.113 hadoop03
192.168.110.114 hadoop04
4、添加hadoop用户,并且添加sudoer权限
vim /etc/sudoers找到 root ALL=(ALL) ALL 这一行 (可以在命令行模式中输入 :/ALL= )能直接找到。
然后在他下面添加一行:
hadoop ALL=(ALL) ALL如下图:
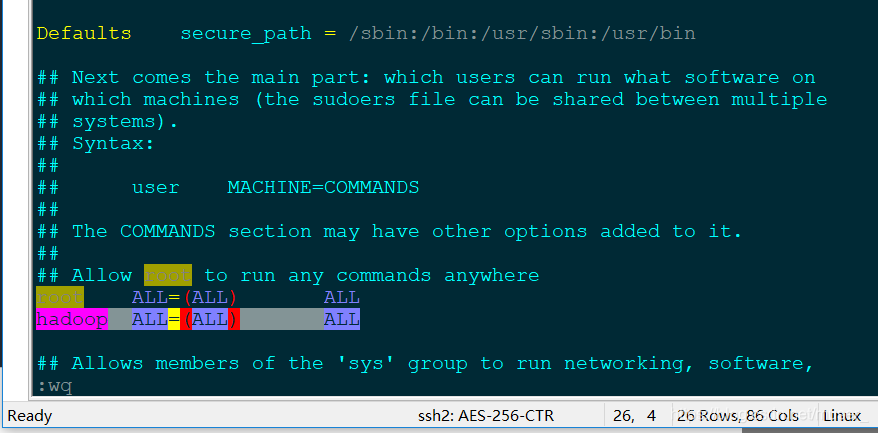
保存,退出!
5、关闭防火墙/关闭selinux
防火墙操作相关:
查看防火墙状态:service iptables status
关闭防火墙:service iptables stop
开启防火墙:service iptables start
重启防火墙:service iptables restart
关闭防火墙开机启动:chkconfig iptables off
开启防火墙开机启动:chkconfig iptables on

关闭防火墙自启动:
chkconfig iptables off关闭 Selinux:
vim /etc/selinux/config配置文件中的 SELINUX=disabled

6、更改系统启动级别为3
vim /etc/inittab按大写的G-->i-->id后面改为3(下次进入以后就没有图形化界面了(玩集群建议改为3),如果实在想要图形界面可以不改)
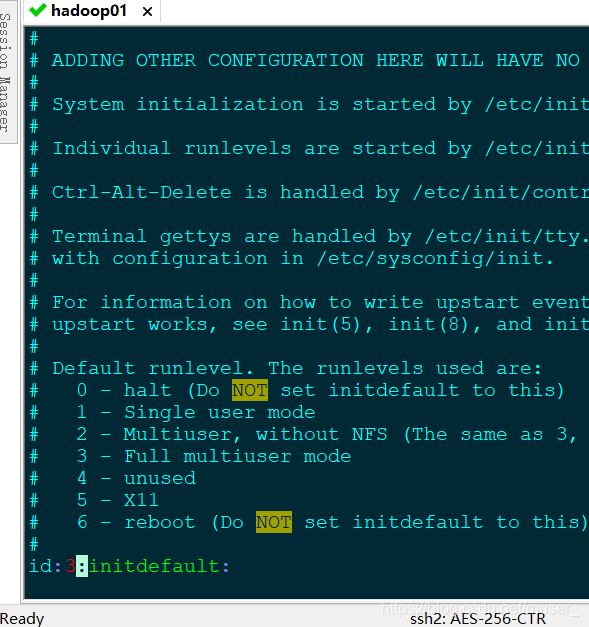
7、安装JDK
参见linuxJDK安装。最后的部分是关于linux安装JDK的,图文并茂的。
8.克隆虚拟机
1)在vmware上,先单击一下hadoop02
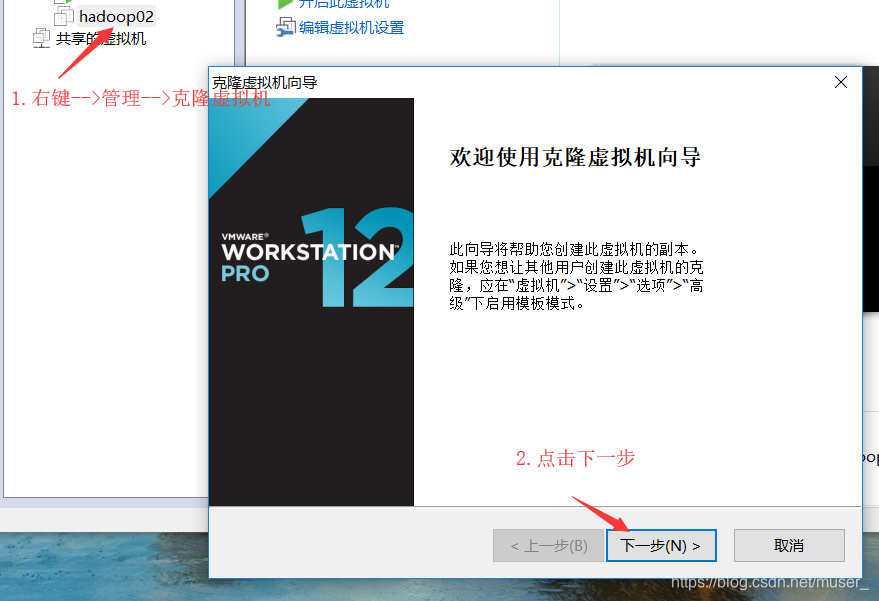
2)点击下一步
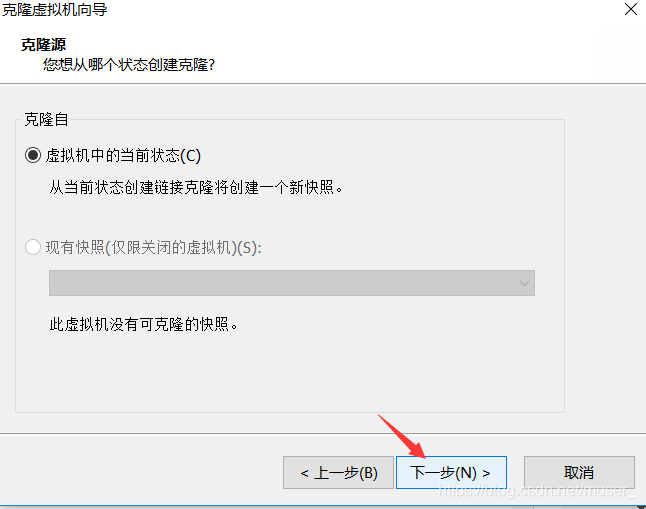
3)点击下一步
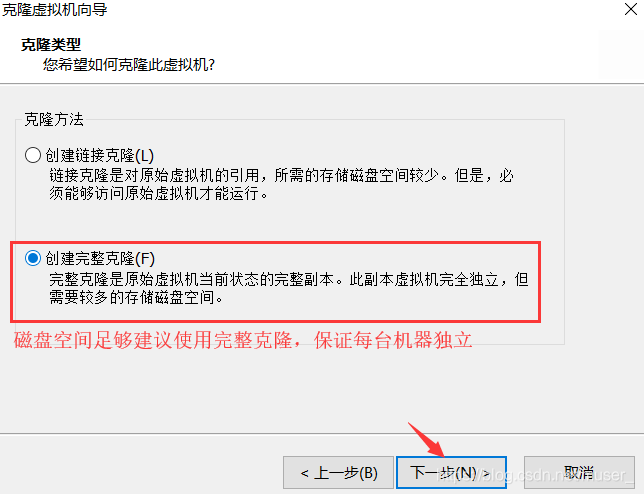
4)点击完成,静静等待……
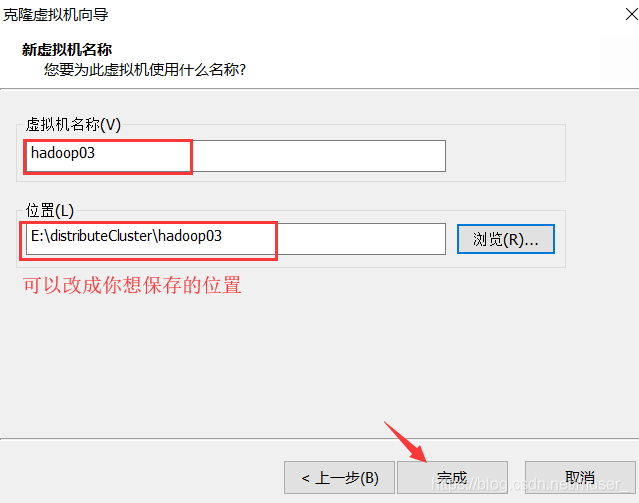
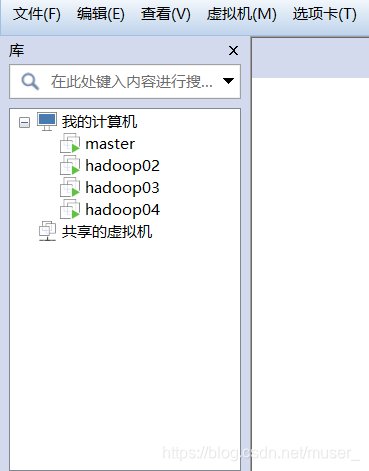
5)克隆完成。接下来启动hadoop02/03/04
1)修改主机名称
vim /etc/sysconfig/network2)修改硬件地址(网卡)
vim /etc/udev/rules.d/70-persistent-net.rules删除eth0对应的网卡信息,修改eth1的名称为eth0
3)修改Ip地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0IPADDR修改为你想要的同网段的IP,例如我克隆出来的两台分别修改为:
192.168.110.113
192.168.110.114
UUID和HWADDR对应的信息删除。如:
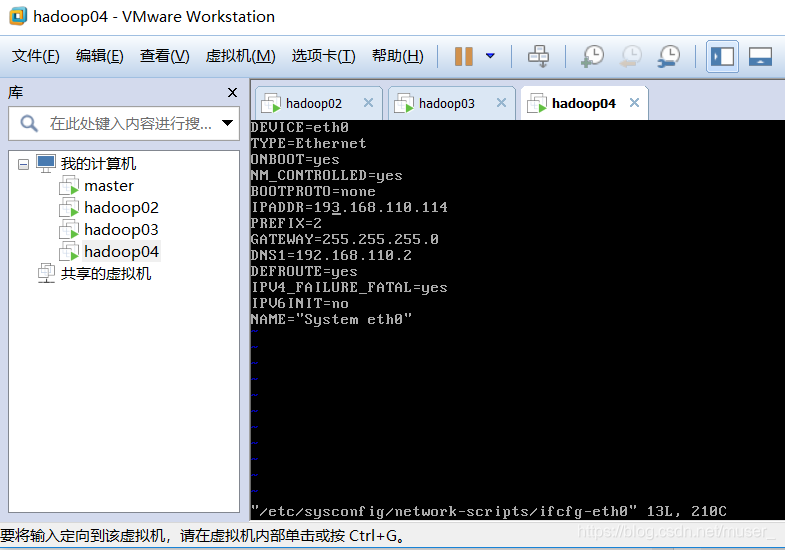
保存退出,重启机器即可。
如果还需要更详细的过程和理解原理,请点这里:这里有更详细的过程,包括复制虚拟机文件
8、三台服务器做时间同步
ntpdate pool.ntp.org可以在三台虚拟机一起设置下面的定时任务: 意思为:每十分钟执行一次,并将日志文件放到回收站中。
因为虚拟机中时间总是不对,免去手动更改时间的烦恼,适合强迫症患者,哈哈。。。
crontab -e*/10 * * * * /usr/sbin/ntpdate hadoop01 >> /dev/null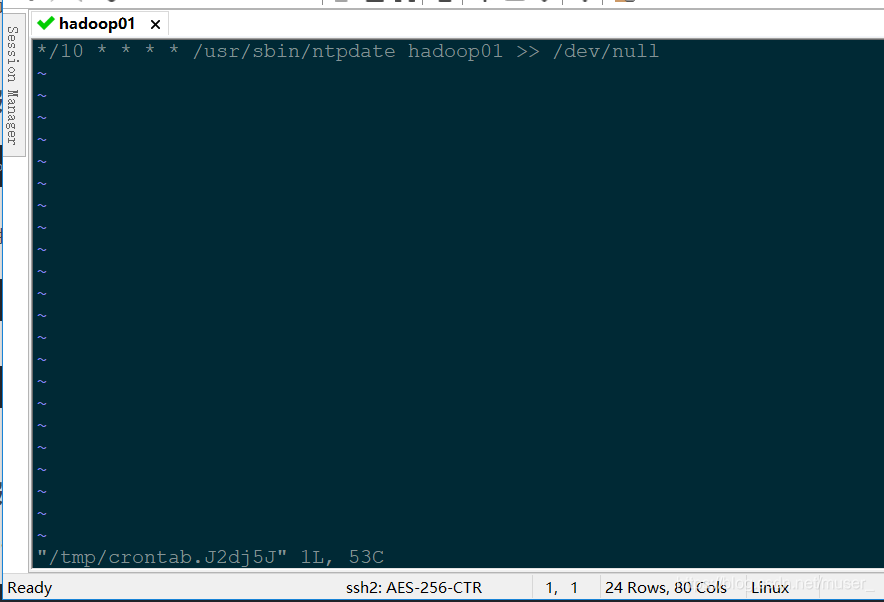
9、三台服务器配置SSH
注意:以下操作请到普通用户下执行
1)在/home/hadoop/.ssh 目录下生成公钥文件:
ssh-keygen然后按三下回车。出来类似下图的即可。
2)建立 hadoop01 到 hadoop02 的免密登录:
ssh-copy-id hadoop02然后输入yes-->输入密码。
分别在三台机器,每一台执行一次ssh-keygen。
然后到每一台机器分别执行ssh-copy-id hadoop01 / 02 / 03三个。
即可实现三台机器相互免密登录。
验证免密登录:
ssh hadoop02退出ssh登录:
exit
至此------恭喜你啦。
集群搭建的基础工作----完成。

















 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









