




 本文探讨了2018年cvpr会议上提出的一种深度网络技术——细节保留池化(Detail-Preserving Pooling),该技术旨在在特征提取过程中保持图像的细节信息,以提高模型的识别精度。
本文探讨了2018年cvpr会议上提出的一种深度网络技术——细节保留池化(Detail-Preserving Pooling),该技术旨在在特征提取过程中保持图像的细节信息,以提高模型的识别精度。
Detail-Preserving Pooling in Deep Networks (2018 cvpr)
作者:Faraz Saeedan,Nicolas Weber,Michael Goesele,Stefan Roth
该文章提出的Detail-Preserving Pooling(DPP)使得max pooling,average pooling成为其特例,并且在池化过程中结合了卷积操作,其保留细节的探究令人愉悦,与max pooling(averag pooling)在池化核中直接提取最显著特征(平均特征)而放弃其他特征的做法
(Hinton提出的capsule部分基于这点)形成对比。
本文作为小博主研读该文章的结果。受博主知识上界限制,文中理解不充分之处在所难免,恭请批评指教。
摘要直译:
大部分卷积神经网络都用某种方法来逐渐缩减隐含层的规模。这种方法通常被称为池化,可以用来降低参数的规模,增强对某些扭曲的不变性,同时增大感受野。因为池化本身就是一个有损耗的过程,所以这样的层是非常重要的,它保持对网络的判别力非常重要的那部分激活。然而,在块上简单的取最大值或者平均值,也就是最大值池化或者均值池化,或者是以步长卷积的形式来朴素的下采样,都是标准操作。在这篇paper中,我们的目标是在深度学习上展示image downscaling的最近结果。 受人类视觉系统聚焦于局部空间变化的启发,该文作者们提出detail-perserving pooling (DPP), 一种自适应的池化方法,这种方法能够放大空间变化并保留重要的结构细节。同样重要的是,它的参数可以和网络的其余部分共同学习。该文作者们分析了该理论的特性并在几个数据集和网络上展示它可实证的好处,即DPP始终比之前的池化方法优越。
核心分析:
考虑到上下文的连贯性和一致性,本部分将分析该文章中第三,四,五部分, 分别为detail-preserving image downscaling, detail-preserving pooling和analysis and discussion。
# Detail-Preserving Image Downscaling (DPID)
在文献[2]中,作者们的目标是保留输入图片的细小细节,因为细节往往对准确的视觉印象非常关键。他们的直觉是细微的细节比相同颜色的大块区域带有更多的信息。因此使用逆双边滤波器(inverse bilateral filter)强调不同而不是惩罚不同。给定一张输入图片
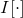 ,用DPID可计算出缩减尺度的输出
,用DPID可计算出缩减尺度的输出
,用DPID可计算出缩减尺度的输出
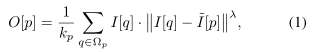
其中线性缩减尺度图片
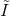 由下式给定
由下式给定
由下式给定
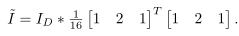
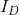 是在输入图片上进行盒式滤波之后再下采样的结果,接着用近似2D高斯滤波器来平滑
,就得到结果
。
是在输入图片上进行盒式滤波之后再下采样的结果,接着用近似2D高斯滤波器来平滑
,就得到结果
。
在第一个公式中,可以看到归一化因子
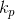 ,
,
,
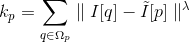
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









