




 港中文大学提出了一种无监督的3D人体姿态特征学习算法,通过特征分离实现视角和姿态的解耦,学习到的表征适用于姿态去噪、动作识别和3D姿态估计,展现出良好的泛化能力。
港中文大学提出了一种无监督的3D人体姿态特征学习算法,通过特征分离实现视角和姿态的解耦,学习到的表征适用于姿态去噪、动作识别和3D姿态估计,展现出良好的泛化能力。

本文将介绍一种基于特征分离的通用人类姿态特征的学习算法 Unsupervised Human 3D Pose Representation with Viewpoint and Pose Disentanglement。

该算法从无监督的特征分离过程中,习得了一个迁移性好、多用途的人类3D姿势的表征,从而有助于人工智能系统获取对人体姿态一个通用本质的理解。
实验证明,所习得的表征,能够用于姿态去噪、人体动作识别和人体3D姿态估计等多个不同的任务。这篇文章来自于香港中文大学,被ECCV 2020 收录。本文将言简意赅的分享这篇文章,希望对读者有所启示。
1、问题解析
在这篇文章中,作者首先对人类姿势表征学习这一问题进行了剖析,认为人体姿态表征应该考虑一下几个方面:
1)人体姿态的本质特征(inherent feature)是什么
作者认为,姿态表征应该首先能够表达人体姿态的本质特征,而该特征应该同时包括人体关节间运动学关系(kinematic dependency)和人体骨骼结构外观特性(geometric dependency)。
人体关节间运动学关系表述了运动在人体各部分间的传播关系,解释了人体姿态是如何生成的,以及决定着在某一动作中身体各个部分的作用。外观特性指人体骨骼结构特有的外观,比如说左右肢体的对称性。
2)本质特征的视角不变性(view-invariant)
数据记录中的人体姿态常常随着观测相机的视角变化而变化。但人体姿态的本质特征是不随视角而改变的。表征作为人体姿态的抽象理解,应该也具备这样的特性。
3)特征分离(feature disentanglement)
人体姿态的形成常常是多个因素互相作用的结果。例如,某一个人体姿态跟动作的执行者、动作本身、以及相机的记录角度是息息相关的。人工特征提取常常基于人类的先验知识,从物理学或统计学的角度去考虑某些因素。
这些考虑常常是不完善的,容易导致信息丢失。信息丢失也同样发生在单纯不变特征的学习过程中。
因而,以人工特征(hand-crafted feature)或者不变特征(view-invariant feature)为表征,常常只能用于特定任务,缺乏泛化性。作者引用图灵奖获得者Bengio的观点,认为特征分离是解决这一问题最有效方式。
现有的人体姿态表征方法因为对以上几点,没有做到一个全面地考量,所以导致泛化性和有效性受限。
2、学习算法思路
作者借鉴去噪自编码器(denoising autoencoder)的思想,设计了一个恢复破坏人体姿态的任务。但是不同于一般的去噪自编码器对输入添加高斯噪声,文中对人体3D姿态进行了随机严重的破坏。
作者认为,如果网络能够恢复那些被破坏关节的正确位置,那么它就应该学习到了人体3D姿态的本质特征。同时在潜空间中,作者将人体姿态特征分解为视角不变的姿态特征(pose-dependent feature)和随视角变化的视角特征(view-dependent feature)。
这一过程可以由下面式(1)表示。
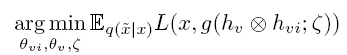 (
(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









