




 本文详细介绍TensorFlow基本函数及神经网络搭建,包括数学运算、数据处理、神经网络原理、优化器选择,以及使用Keras简化网络搭建流程,涵盖鸢尾花分类案例。
本文详细介绍TensorFlow基本函数及神经网络搭建,包括数学运算、数据处理、神经网络原理、优化器选择,以及使用Keras简化网络搭建流程,涵盖鸢尾花分类案例。
目录
TensorFlow
TensorFlow 基本函数
1、tf.cast(张量名,dtype = 数据类型):强制tensor转换为该数据类型;
2、tf.reduce_min(张量名):计算张量维度上元素最小值;
3、tf.reduce_max(张量名):计算张量维度上元素最大值;
3、理解axis:在二维张量或数组中,可以通过axis = 0(或1)控制执行维度。axis=0,代表按列,axis=1,代表了按行。如果不指定axis,则所有元素参与计算。
4、tf.reduce_mean(张量名,axis= ):计算张量沿着指定维度的平均值;
5、tf.reduce_sum(张量名,axis= ):计算张量沿着指定维度的和;
import tensorflow as tf
x1=tf.constant([[1,2,3],[3,4,5]],dtype = tf.float64)
print(x1)
x2=tf.cast(x1,dtype = tf.int32)
print(x2)
print(tf.reduce_min(x2),tf.reduce_max(x2))
print(tf.reduce_min(x2,axis=0),tf.reduce_max(x2,axis=1))
print(tf.reduce_mean(x2,axis=0),tf.reduce_sum(x2,axis=1))
运行结果:
tf.Tensor(
[[1. 2. 3.]
[3. 4. 5.]], shape=(2, 3), dtype=float64)
tf.Tensor(
[[1 2 3]
[3 4 5]], shape=(2, 3), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32)
tf.Tensor([1 2 3], shape=(3,), dtype=int32) tf.Tensor([3 5], shape=(2,), dtype=int32)
tf.Tensor([2 3 4], shape=(3,), dtype=int32) tf.Tensor([ 6 12], shape=(2,), dtype=int32)
6、TensorFlow中的数学运算:
a、对应四则运行:tf.add,tf.subtract , tf.multiply , tf.divide
b、平方、次方与开方:tf.square , tf.pow , tf.sqrt
c、矩阵乘:tf.matmul
7、特征与标签配对函数:tf.data.Dataset.from_tensor_slics((输入特征,标签))
import tensorflow as tf
features = tf.constant([12,23,10,17])
labels = tf.constant([0,1,1,0])
dataset = tf.data.Dataset.from_tensor_slices((features,labels))
print(dataset)
for element in dataset:
print(element)
输出结果:
<TensorSliceDataset shapes: ((), ()), types: (tf.int32, tf.int32)>
(<tf.Tensor: id=9, shape=(), dtype=int32, numpy=12>, <tf.Tensor: id=10, shape=(), dtype=int32, numpy=0>)
(<tf.Tensor: id=11, shape=(), dtype=int32, numpy=23>, <tf.Tensor: id=12, shape=(), dtype=int32, numpy=1>)
(<tf.Tensor: id=13, shape=(), dtype=int32, numpy=10>, <tf.Tensor: id=14, shape=(), dtype=int32, numpy=1>)
(<tf.Tensor: id=15, shape=(), dtype=int32, numpy=17>, <tf.Tensor: id=16, shape=(), dtype=int32, numpy=0>)
8、求导运算:可以在with as 结构中通过tf.GradientTape , 实现对某个参数的求导运算。如:求loss = w^2 函数在w=3时的导数。这里分别用了平方和次方函数,计算结果都一样。
import tensorflow as tf
with tf.GradientTape() as tape:
w = tf.Variable(tf.constant(3.0))
loss = tf.pow(w,2)
grad = tape.gradient(loss,w)
print(grad)
with tf.GradientTape() as tape:
w = tf.Variable(tf.constant(3.0))
loss = tf.square(w)
grad = tape.gradient(loss,w)
print(grad)
计算结果:
tf.Tensor(6.0, shape=(), dtype=float32)
tf.Tensor(6.0, shape=(), dtype=float32)
9、enumerate是Python的内建函数,它可以遍历每个元素(如列表、元组或字符串),组合为:索引 元素,常在for循环中使用
seq = ['我','爱','你','中','国']
for i,element in enumerate(seq):
print(i,element)
运行结果:
0 我
1 爱
2 你
3 中
4 国
10、tf.one_hot 独热编码,在分类为题中常用独热码做标签,标记类型为:1表示是,0表示非。
可参考:独热码(one-hot-enconding)的理解以及编码与解码
11、tf.nn.softmax()函数使输出符合概率分布,才能与独热码进行比较。
可参考:小白都能看懂的softmax详解
12、w.assign_sub(w要自减的内容):常用与参数的自更新。调用assign_sub前,先用tf.Variable定义变量w为可训练(可自更新)其实就是w = w-(w要自减的内容)。
13、tf.argmax(张量名,axis= 0(或1)),返回张量沿着指定维度最大值的索引(注意:索引是从零开始),区别于上文中的tf.reduce_max()函数(返回的最大值)。
TensorFlow原生代码搭建神经网络
以鸢尾花分类为例。从sklearn数据库中导入数据集,数据其中特征值有四种,分类标签有三种,程序构建了单层网络,为四输入,三输出,所以定义的w1,为一个4行3列的矩阵。
import tensorflow.compat.v1 as tf
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
np.random.seed(116)
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
x_train = tf.cast(x_train,tf.float32)
x_test = tf.cast(x_test,tf.float32)
train_db = tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test)).batch(32)
w1=tf.Variable(tf.random.truncated_normal([4,3],stddev=0.1,seed=1))
b1=tf.Variable(tf.random.truncated_normal([3],stddev=0.1,seed=1))
lr=0.1
train_loss_results = []
test_acc = []
epoch = 500
loss_all=0
total_correct=0
total_number=0
for epoch in range(epoch):
for step,(x_train,y_train) in enumerate(train_db):
with tf.GradientTape() as tape:
y=tf.matmul(x_train,w1)+b1
y=tf.nn.softmax(y)
y_=tf.one_hot(y_train,depth=3)
loss = tf.reduce_mean(tf.square(y-y_))
loss_all += loss.numpy()
grads=tape.gradient(loss,[w1,b1])
w1.assign_sub(lr*grads[0])
b1.assign_sub(lr*grads[1])
print('Epoch {} , loss {} '.format(epoch,loss_all/4))
train_loss_results.append(loss_all/4)
loss_all=0
for x_test,y_test in test_db:
y = tf.matmul(x_test,w1)+b1
y = tf.nn.softmax(y)
pred = tf.argmax(y,axis=1)
pred =tf.cast(pred,dtype=y_test.dtype)
corret = tf.cast(tf.equal(pred,y_test),dtype=tf.int32)
corret = tf.reduce_sum(corret)
total_correct +=int(corret)
total_number +=x_test.shape[0]
acc = total_correct / total_number
test_acc.append(acc)
print('test_acc:',acc)
print('----------------------------')
plt.title('Loss Function Curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.plot(train_loss_results,label='$loss$')
plt.legend()
plt.show()
plt.title('ACC Curve')
plt.xlabel('Epoch')
plt.ylabel('ACC')
plt.plot(test_acc,label='$Accuracy$')
plt.legend()
plt.show()
神经网络中的名词解释
先讲几个函数:
1、tf.where(条件语句,真时返回的,假时返回的);
2、np.random.RandomState.rand(维度):返回一个[0,1)之间的随机数,维度为空时,返回标量;
np.random.RandomState.rand(seed=常数):seed=常数时,每次生成的随机数相同;
3、np.vstack(数组1,数组2):将两个数组按垂直方向叠加;
4、np.mgrid[ ]、np.ravel()、np.c_[ ]这三个函数经常一起使用:
np.mgrid[起始值:结束值:步长, 起始值:结束值:步长,…]:返回维度相同的等差数组 ;
x.ravel() :将x变为一维数组,’‘把ravel()前的变量拉直’’;
np.c_[数组1,数组2,… ]:使返回的间隔数值点配对,也就是数组1于数组2中的元素对应位置进行配对,在使用前,需要用ravel()函数,将数组中的元素拉直;
学习率
训练的目的是为了求得满足loss最小值时的权重w。现在以一维为例,w为横坐标,loss为纵坐标。根据我们学过的导数,导数为零的位置是极值点,我们的目的就是为了找极值点。但是,在找的过程中遇到了问题,w未知。所以,只能向给w随机定一个初值,走一步看一步。loss函数中,当导数大于零时,说明曲线递增,执行w=w-lr*(loss对于w的导数)时,w相当于在原基础上向左移动;反之,当导数小于于零时,w相当于在原基础上向右移动了,经过多次移动后,最终会取到loss最小值。从w=w-lr*(loss对于w的导数)可以看出,每次移动的距离,与 lr 值有关,当lr取得小,每次移动的距离就小,达到最小值需要的时间就长,反之,当lr取得的,每次移动的距离就大,达到最小值需要的时间就短,这个 lr 就是学习率
在实际运用中,往往先用较大学习率,快速达到较优解,然后逐步减小学习率,使模型在训练后期稳定。所以会在原来学习率基础上进行更改,先增长快,在增长慢,这与指数函数很类似。所以将学习率改为:指数衰减学习率=初始学习率*学习衰减率^(当前轮数/多少轮衰减一次)
激活函数
1、Sigmoid函数:tf.nn.sigmoid(x),该函数的导函数取值范围(0,0.25],随着网络层数的增减,会有多个0~0.25之间的数相乘,会使得结果趋近于0,甚至等于,就会导致一些结果的消失,也就是梯度消失,所以,现在针对多层网络,基本上很少使用该函数。
2、Tanch函数,依旧存在梯度易失,幂运算复杂的问题
3、Relu函数,解决了梯度消失的问题,计算速度快,当送入激活函数的值为负数时,结果为零,反向传播求求梯度时也会造成梯度消失。导致一些神经元不工作,引起神经元死亡。
4、Leaky Relu函数,当输入值为负数时,导数为负数,实在Relu函数基础上的更新。是解决Relu函数导致神经元死亡提出的。尽管理论上讲Leaky Relu有Relu所有优点,但是在实际操作中,并没有完全证明Leaky Relu总是好与Relu
损失函数
损失函数loss:预测值(y)与已知答案(y_)的差距。有人会想,这个差距我直接相加不就行了吗?不行!因为差距有正有负,在相加的过程中会抵消一部分值,所以至少得加绝对值,加平方。
常用的有三种:均方差,交叉熵,自定义;
均方差函数(mse):loss_mse = tf.reduce_mean(tf.squre(y-y_))
交叉熵损失函数(Cross Entropy):loss_CE = tf.losses.categorical_crossentropy(y,y_) 可以标准两个概率分布之间的距离
欠拟合与过拟合
欠拟合:是模型不能有效模拟数据集,是对现有数据集学习的不够彻底;
过拟合:是模型对当前的数据拟合的太好了,对没有出现的数据难以做出有效的判断,具体表现为曲线不够平滑。
欠拟合的解决方法:1、增加输入特征项;2增加网络参数;3减少正则化参数;
过拟合的解决方法:1、数据清洗;2、增大训练集,3、采用正则化;4、增大正则化参数
在训练过程实际上就是找每个输入值权重w,所谓正则化就是再给w加上一个权重,这样可以弱化训练数据的噪声。
正则化的选择:
L1正则化大概率会使很多参数变为零,因此该方法可以通过稀疏矩阵(即减少参数的数量),降低复杂度。
L2正则化会使参数很接近零但不为零,因此该方法可以通过减小参数值的大小降低复杂度。
优化器更新网络参数
优化器就是引导神经网络更新参数的工具。
五中常用的优化器
1、SGD,常用的梯度下降法;
2、SGDM,在SGD的基础上增加了一阶动量;
3、Adagrad,在SGD的基础上增加了二阶动量(二阶动量是从开始到现在梯度平法的累计和);
4、RMSProp,在SGD的基础上增加了二阶动量(二阶动量使用指数滑动平局值计算);
5、Adam,同时结合SGDM一阶动量和RMSProp二阶动量;
以上不需要深度理解,只需要知道优化器是可以降低训练时间。针对不同的情况五中情况的优劣各有不同。
Keras 搭建神经网络
基本函数
1、model = tf.keras.models.Sequential( [网络结构] ) #描述各层网络
网络结构距离:
拉直层:tf.keras.layers.Flatten() #把输入特征拉直变成一维数组
全连接层:tf.keras.Dense( 神经元个数 , activation = ’ 激活函数 ’ , kernel_regularizer = 那种正则化 ) # activation 可选:relu , softmax , sigmoid , tanch ; kernel_regularizer 可选:tf.keras.regularizers.l1() , tf.keras.regularizer.l2() .
卷积层:tf.keras.layers.Conv2D( filters = 卷积核个数 , kernel_size = 卷积核尺寸 , strides = 卷积步长 , padding = ’ valid ’ or ’ same ’ )
LSTM层:tf.keras.layers.LSTM()
2、model.compile( optimizer = 优化器 , loss = 损失函数 , metrics = [ ’ 准确率 '] )
3、model,fit( 训练集的输入特征,训练集的标签,batch_size = , epoch = , validation_data = ( 训练集的输入特征,测试集的标签),validation_split = 从训练集划分多少比例给测试集, validation_freq = 多少次epoch测试一次)
4、model.summary() #打印出网络结构和参数统计
5、class Mymodel(Mode) model=MyModel #Sequential可以搭建出上层输出就是下层输入的顺序网络结构,但是无法写出一些跳连的非顺序网络结构,此时可以选择用类class,搭建神经网络结构。
Sequential搭建神经网络
六步法:
1、import
2、train,test 训练集与测试集
3、model = tf.keras.models.Sequential
4、model.compile
5、model.fit
6、model.summary
将鸢尾花分类的原生代码改为:
import tensorflow as tf
from sklearn import datasets
import numpy as np
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
np.random.seed(116)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3,activation='softmax',kernel_regularizer=tf.keras.regularizers.l2())])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train,y_train,batch_size=32,epochs=500,validation_split=0.2,validation_freq=20)
model.summary()
Class自定义函数搭建神经网络
由于Sequential构建的是一个顺序链接的函数,只能是这层的输出为下层的输入,所以为了改变这些中顺序结构,我们可以通过定义一个类,来搭建自己的网络,这里给了一个定义函数的入门级,还未涉及高级应用。
class IrisModel(Model):
def __init__(self):
super(IrisModel,self).__init__()
self.d1 = Dense(3,activation='sigmoid',kernel_regularizer=tf.keras.regularizers.l2())
def call(self,x):
y = self.d1(x)
return y
此时就可以采用自己定义的函数搭建神经网络,
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
from sklearn import datasets
import numpy as np
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
np.random.seed(116)
class IrisModel(Model):
def __init__(self):
super(IrisModel,self).__init__()
self.d1 = Dense(3,activation='sigmoid',kernel_regularizer=tf.keras.regularizers.l2())
def call(self,x):
y = self.d1(x)
return y
model=IrisModel()
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train,y_train,batch_size=32,epochs=500,validation_split=0.2,validation_freq=20)
model.summary()
卷积神经网络
卷积神经网络的主要模块:
卷积(Convolutional)——批标准化(BN)——激活(Activation)——池化(Pooling)——全连接(FC)
卷积是什么?卷积就是特征提取器,就是CBAPD(上面英文的缩写,其中 ‘D’ 是 ’ Dropout ')
卷积计算
卷积计算可认为是一种有效提取图像特征的方法。
一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长,卷积核会与输入特征图出现重合区域,重合域对应元素相乘、求和再加上偏执项得到输出特征的一个像素点。
输入特征图的深度(通道数),决定了当前卷积核的深度,由于每个卷积核在经过卷积计算后,会得到一个输出特征图,所以当前层使用了几个卷积核,就会有几个特征图输出。如果你觉得某层模型的特征提取能力不足,可以在这一层多用几个卷积核提高这一层的特征提取能力。
tensorflow中描述卷积:
tf.keras.layers.Conv2D( filters = 卷积核个数 ,kernel_size = 卷积核尺寸,#正方形写核长整数,或(核搞h,核款w),strideis = 滑动步长,#横纵向相同写步长整数,或(纵向长好,横向长w),padding = ‘ same ’ or ’ valid ’ #使用全零填充是‘same’,不使用是’valid’,activation = ’ relu ’ or ’ sigmoid ’ or ’ softmax ',input_shape = (高,宽,通道数) #输入特征图维度,可省略)
感受野
感受野是指:在输出特征图中的一个像素点,在原始输入图片上的映射区域的大小。
将5x5的输入图片,与3x3的卷积核作用,会得到一个3x3的特征图,这个输出特征图上的每个像素点映射到输入图像上是一个3x3的区域,所以这个像素点的感受野就是3,如果再对这个3x3的特征图与一个3x3的卷积核作用,会输出一个1x1的特征图,那么这个1x1的输出特征图的像素点映射到原始图像的区域就是5x5,所以可以说这个经过两次卷积得到11特征图的像素点感受野就为5x5
同样,将5x5的输入图片,与5x5的卷积核作用,会直接得到1x1的特征图。此时特征图一个像素感受野就是5
比较上面两种方法,都起到了提取特征的做作用,在实际运用中要采用那种方法呢?这时我们就需要考虑计算中所承载的带训练的参数和计算量了。对于上述第一种方法,带训练参数有18个,对于第二种方法,带训练参数就有25个。假设输入特征宽和高都是x,卷积计算步长为1,对于第一种方法的计算量为18x^2 -180x+180;对于第二种方法计算量为25x^2-200x+400。
**当输入图片边长x>10时,两次33卷积核比一次5*5卷积核性能要好**
批标准化
神经网络对0附近的数据更敏感,但是随着网络层数的增加,特征数据会出现偏离0均值的情况,标准化可以使数据符合以0位均值,1位标准差的正态分布,把偏移的特征值的数据重新拉回到0附近。
批标准化是对一个batch的数据做标准化处理使数据回归正态分布,常用在卷积操作和激活操作之间。
TensorFlow描述标准化:
tf.keras.layers.BatchNormalization(),可以参考以下代码,把BN层加到卷积层与激活函数之间。
model = tf.keras.models,Sequential([
Conv2D(filter=6,kernel_size=(5,5),padding='same'),
BatchNormalization(),#BN层
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Dropout(0.2),
])
池化
池化操作用于减少卷积神经网络中特征数据量,池化的主要方法有最大值池化和均值池化。
最大池化可以提取图片纹理,均值池化可以保留背景特征。
最大值池化:
tf.keras.layers.MaxPooling2D( pool_size = 池化核尺寸,#正方形写核长,或(核高h,核宽w),strides = 池化步长,#步长整数,或(纵向步长h,横向步长w),padding = ’ valid ’ or ’ same ’ #使用全零填充是’same’,不使用是’valid’ )
均值池化:
tf.keras.layers.AveragePooling2D( pool_size = 池化核尺寸,#正方形写核长,或(核高h,核宽w),strides = 池化步长,#步长整数,或(纵向步长h,横向步长w),padding = ’ valid ’ or ’ same ’ #使用全零填充是’same’,不使用是’valid’)
舍弃
为了缓解神经网络过拟合,常把隐藏层的部分神经元按照一定比例从神经网络中零时舍弃。在使用神经网络时再把神经元恢复到神经网络中。
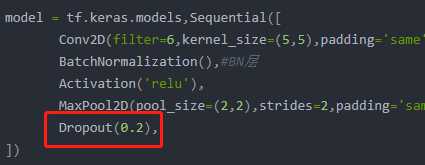
这里的Dropout(0.2)表示的是随机舍弃掉20%的神经元。


















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









