




项目技术栈
- 游戏在微信中运行,使用
cocos开发。 - 后端部署在debian服务器,使用
goravel开发。
需求
- 本次预计5-10万用户,每个用户可玩多次游戏。
- 活动发布后会进入大量用户,瞬时并发较大,初步评估高峰qps可达1000左右。
- 游戏活动结束后 半月后下线。
部署方案
计算量分析
整个游戏过程只存储用户信息和用户游戏数据,无复杂计算,因为只需购买一个月,所以服务器购买了 8核16G。
带宽分析
接口流量分析
接口流量平均每个 0.5kB,达到1000qps那么流量峰值为:0.5kB*1000 = 500kB/s = 0.5M/s。

所以服务器理论带宽至少5M,实际上要购买10M以上的,留足可用带宽,因为高峰期可能更高翻几倍都是有可能的。
云服务器有一种按流量收费的类型,瞬时并发高的项目很适合使用这种类型的服务器
以下是不同带宽的价格差异
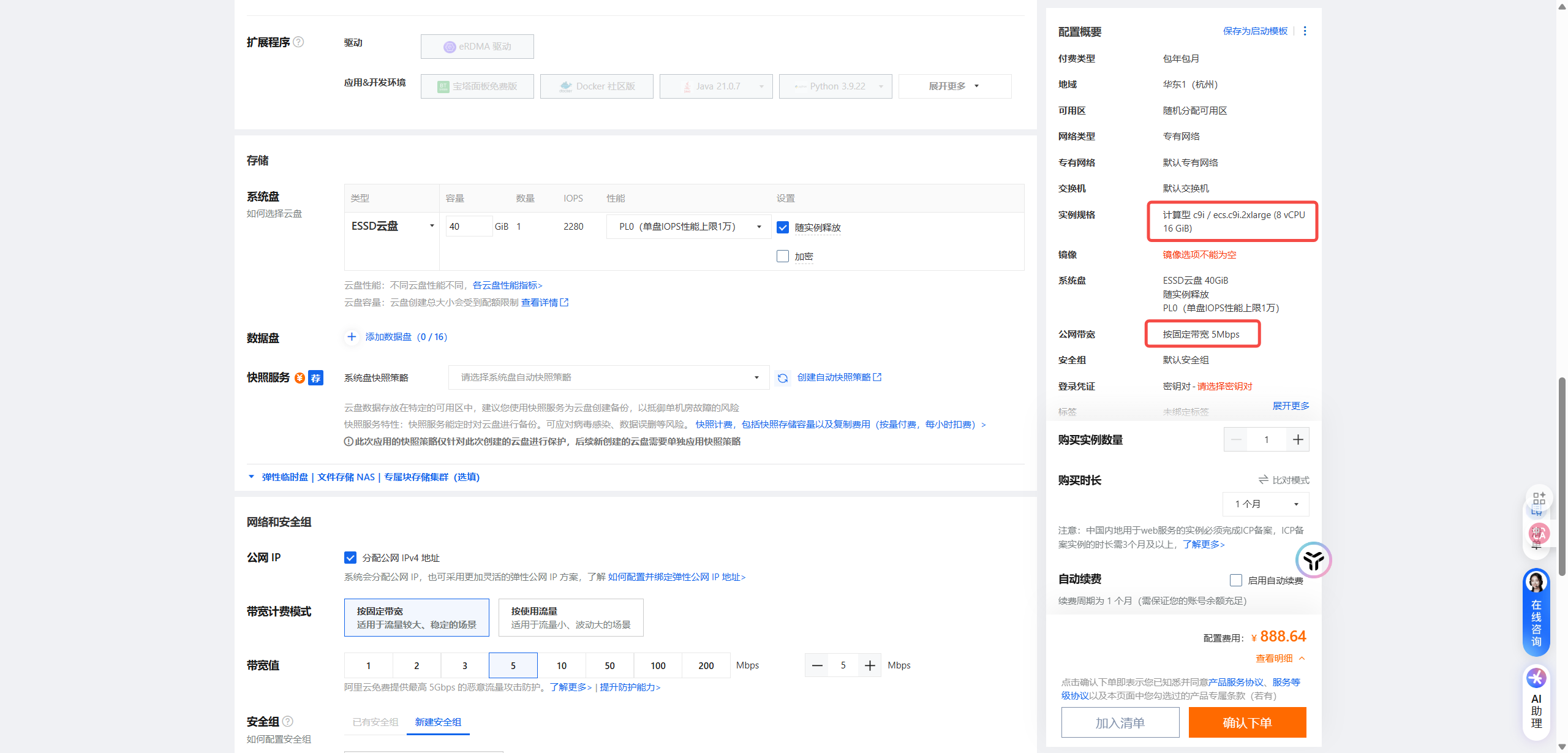
8核16G 5M带宽价格
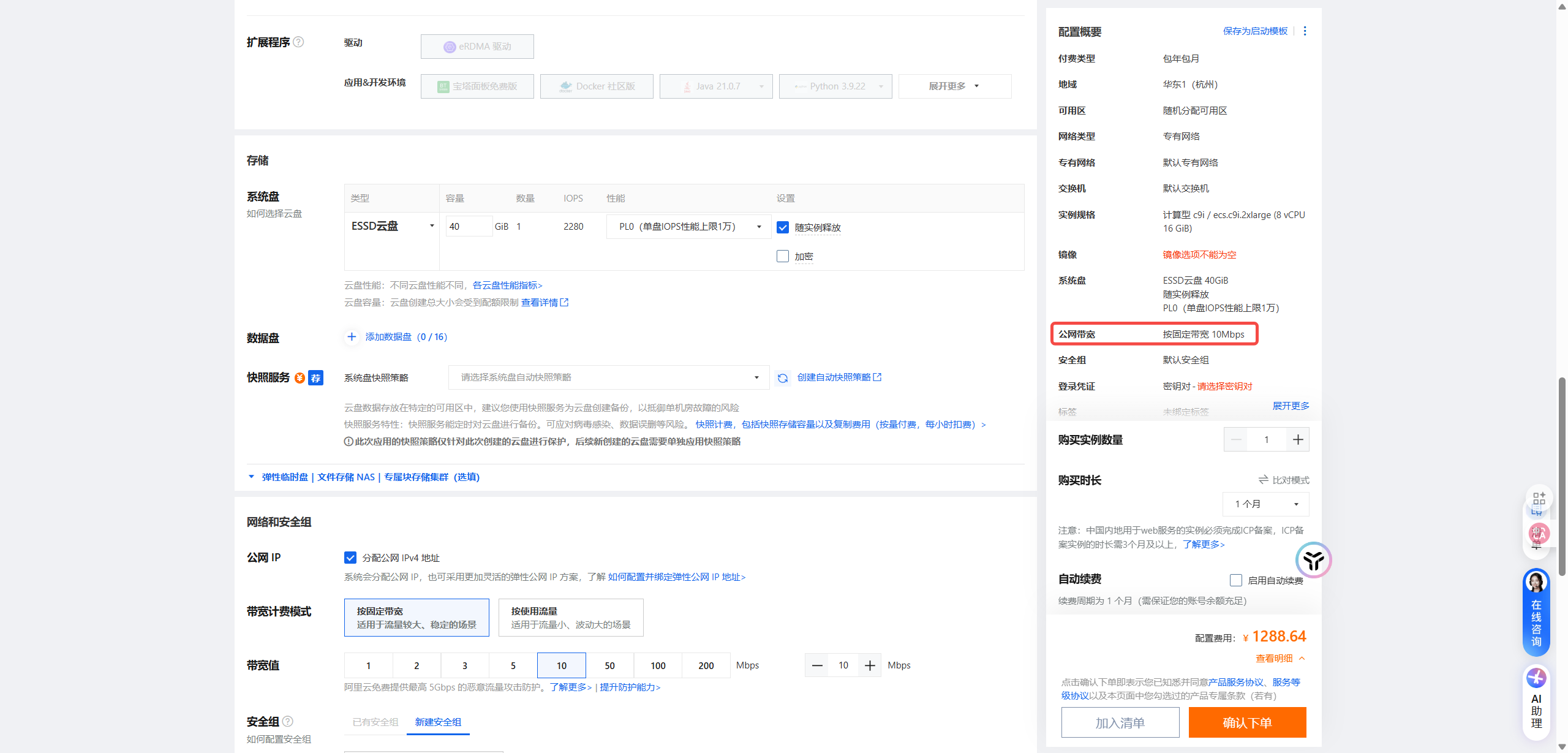
8核16G 10M带宽价格
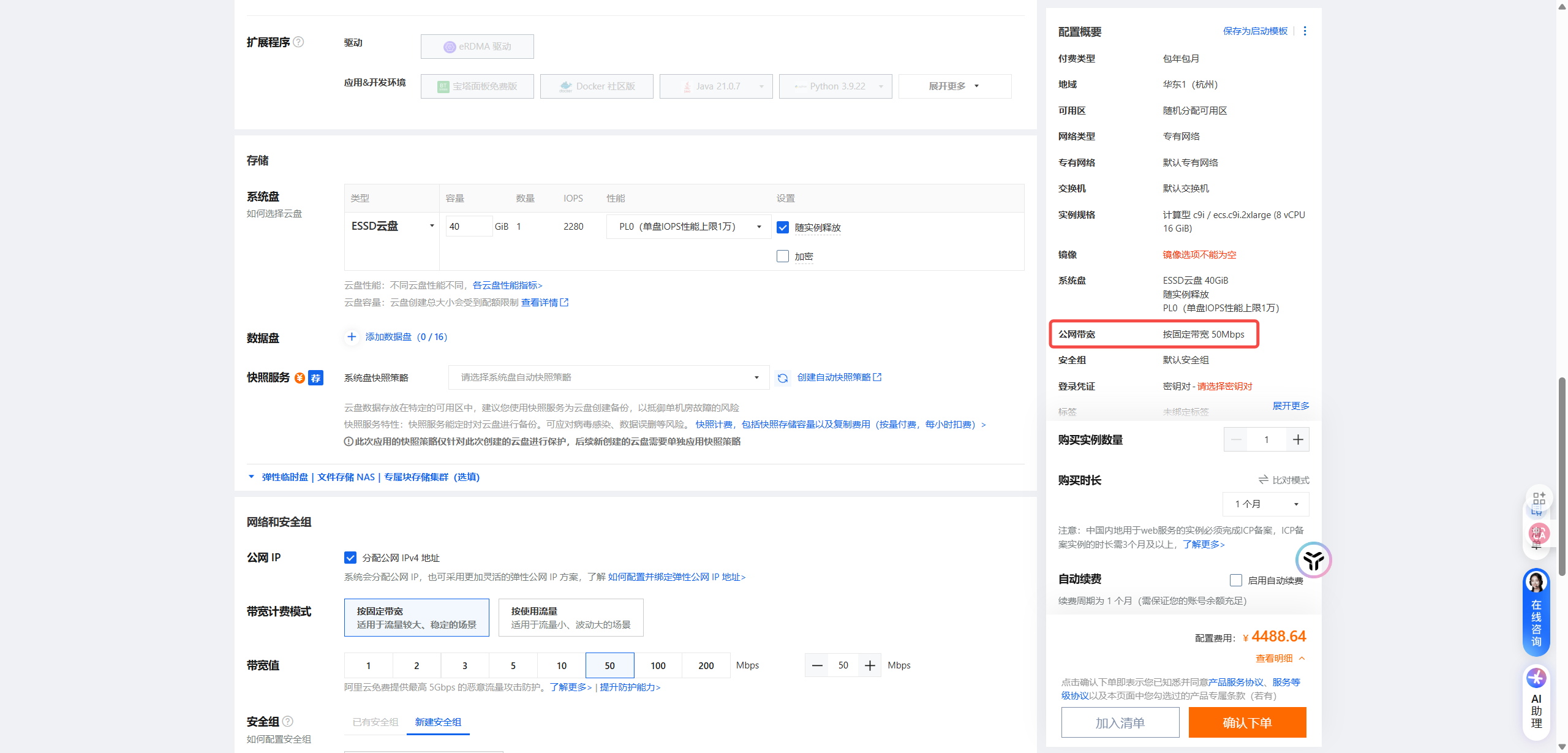
8核16G 50M带宽价格
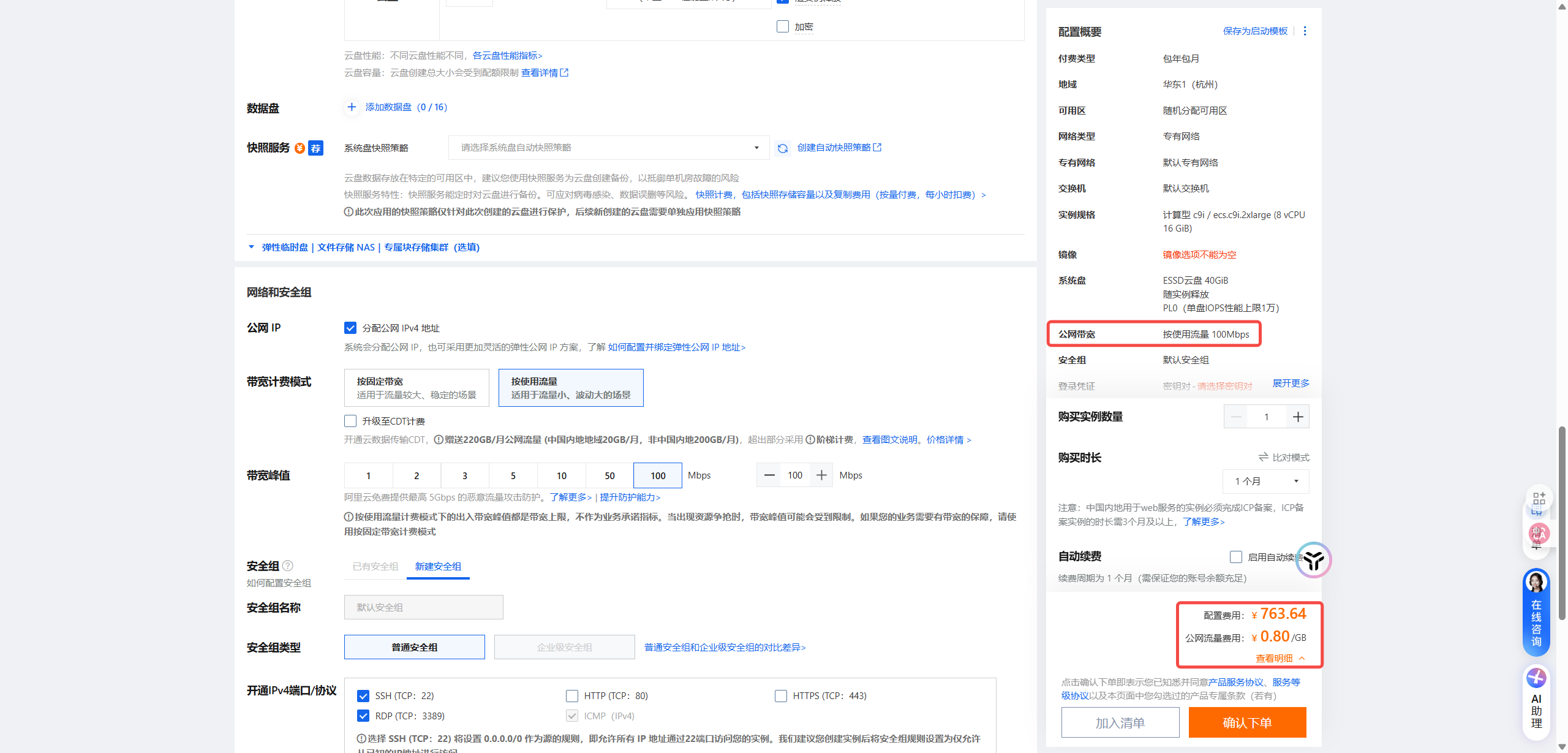
8核16G 按量收费上限100M
游戏加载流量分析

单次加载流量需要3M,那么如果千人同时访问那么游戏加载的流量高达:1000*3MB = 3000M/s,那么需要3WM带宽。
我们购买服务器时可以看到服务器的带宽最多是100M,达不到我们的要求,所以游戏资源文件肯定不能放在服务器上。
所以游戏资源我们放在对象存储上,开启对象存储的静态网站功能,绑定自己的域名。
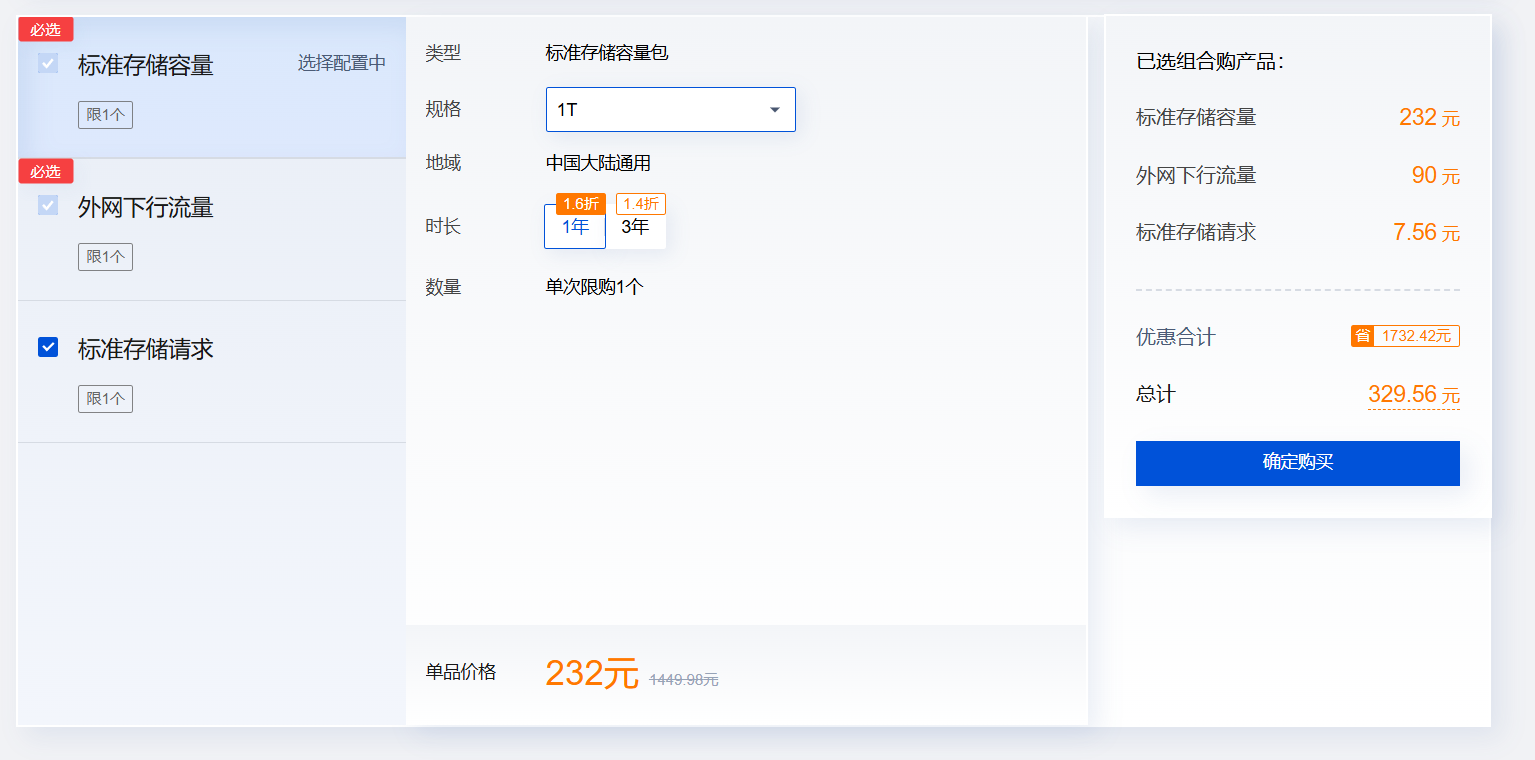
可以看到对象存储价格还是比较便宜,以下是带宽限制的描述
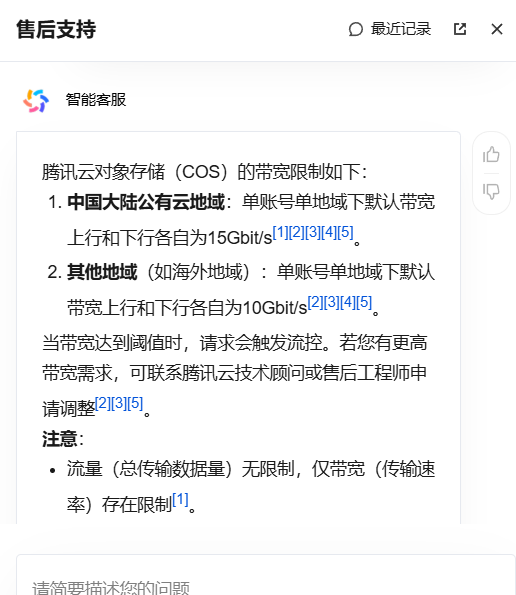
实际运行数据分析
nginx 访问日志分析
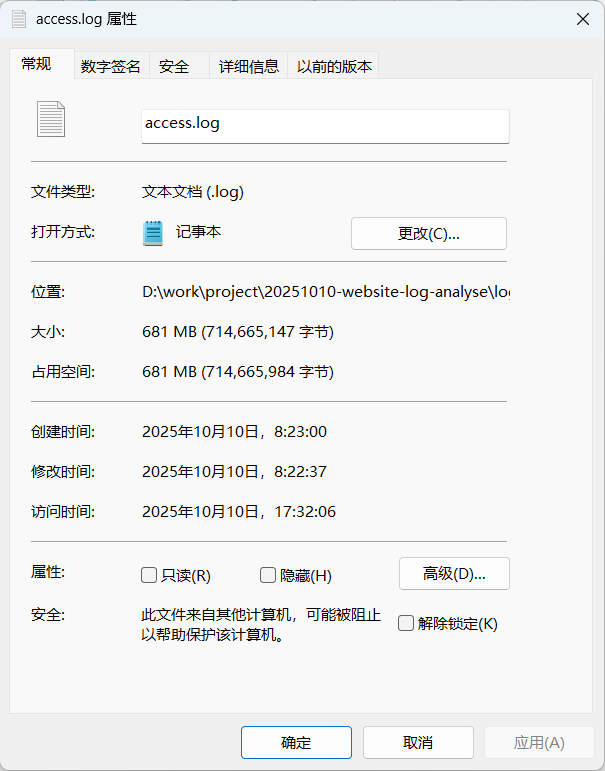
nginx 文件大小 680MB
数据分析脚本
#!/usr/bin/env python3
import re
import argparse
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from datetime import datetime, timedelta
from collections import defaultdict
import numpy as np
import pandas as pd
from matplotlib.ticker import MaxNLocator
import matplotlib.font_manager as fm
import os
import matplotlib
matplotlib.rc("font", family='YouYuan')
def parse_log_line(line):
"""解析单行 Nginx 日志"""
pattern = r'^(?P<ip>\S+) \S+ \S+ \[(?P<time>[\w:/]+\s[+\-]\d{4})\]'
match = re.match(pattern, line)
if not match:
return None, None
ip = match.group('ip')
time_str = match.group('time')
try:
dt = datetime.strptime(time_str, '%d/%b/%Y:%H:%M:%S %z')
return ip, dt
except ValueError:
return None, None
def analyze_log(log_file, top_ips=10):
"""分析日志文件并生成图表"""
# 初始化数据结构
per_second = defaultdict(int)
per_minute = defaultdict(int)
ip_activity = defaultdict(int)
timeline = []
# 设置筛选日期阈值(9月29日)
cutoff_date = datetime(2023, 9, 29, 0, 0, 0).replace(tzinfo=datetime.now().astimezone().tzinfo)
# 解析日志文件
with open(log_file, 'r') as f:
for line in f:
ip, dt = parse_log_line(line)
if not dt:
continue
# 转换为本地时区
dt = dt.astimezone()
# 只统计9月29日之后的数据
if dt < cutoff_date:
continue
# 时间点统计
sec_key = dt.replace(microsecond=0)
min_key = dt.replace(second=0, microsecond=0)
per_second[sec_key] += 1
per_minute[min_key] += 1
ip_activity[ip] += 1
timeline.append(dt)
if not timeline:
print("未找到有效的日志条目")
return
# 计算时间范围
min_time = min(timeline)
max_time = max(timeline)
time_range = max_time - min_time
# 创建单独的图表
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# 1. 每分钟请求数图表(单独保存)
plt.figure(figsize=(15, 6))
plt.suptitle('标题', fontsize=20, fontweight='bold', y=0.99)
minutes = sorted(per_minute.keys())
requests_per_minute = [per_minute[m] for m in minutes]
plt.plot(minutes, requests_per_minute, 'b-', linewidth=1.5)
title_rpm = '每分钟请求数 (RPM)'
plt.title(title_rpm)
plt.xlabel('时间')
plt.ylabel('请求数')
plt.grid(True, linestyle='--', alpha=0.7)
# 设置X轴格式
if time_range > timedelta(days=1):
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%m/%d %H:%M'))
else:
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%H:%M'))
plt.gcf().autofmt_xdate()
plt.setp(plt.gca().get_xticklabels(), visible=True, rotation=30, ha='right')
plt.tight_layout()
rpm_file = f"logs/rpm_chart_{timestamp}.png"
plt.savefig(rpm_file)
print(f"RPM图表已保存至: {rpm_file}")
plt.close()
# 2. 每秒请求数图表(峰值区域)(单独保存)
plt.figure(figsize=(15, 6))
# 找到峰值时间段(前5%的时间段)
peak_period = sorted(per_second.items(), key=lambda x: x[1], reverse=True)
peak_period = peak_period[:max(10, len(peak_period) // 20)]
peak_times = [t for t, _ in peak_period]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











