 Hadoop高可用与Hive入门详解
Hadoop高可用与Hive入门详解





 本文介绍了Hadoop实现高可用的机制,包括active和standby NameNode的设置,以及依赖Zookeeper的qjournal在高可用中的作用。接着,深入讲解了Hive的工作流程,包括CREATE语句如何创建元数据,以及查询语句如何被编译成Java jar包并执行。文章还提到了Hive只能执行查询,不能执行添加操作,并详细阐述了Hive导入数据、managed table和external table的区别,以及分区的本质。最后,讨论了Hive支持的数据类型,如数组和map,并说明了在shell环境下执行Hive语句的情况。
本文介绍了Hadoop实现高可用的机制,包括active和standby NameNode的设置,以及依赖Zookeeper的qjournal在高可用中的作用。接着,深入讲解了Hive的工作流程,包括CREATE语句如何创建元数据,以及查询语句如何被编译成Java jar包并执行。文章还提到了Hive只能执行查询,不能执行添加操作,并详细阐述了Hive导入数据、managed table和external table的区别,以及分区的本质。最后,讨论了Hive支持的数据类型,如数组和map,并说明了在shell环境下执行Hive语句的情况。
Hadoop 高可用
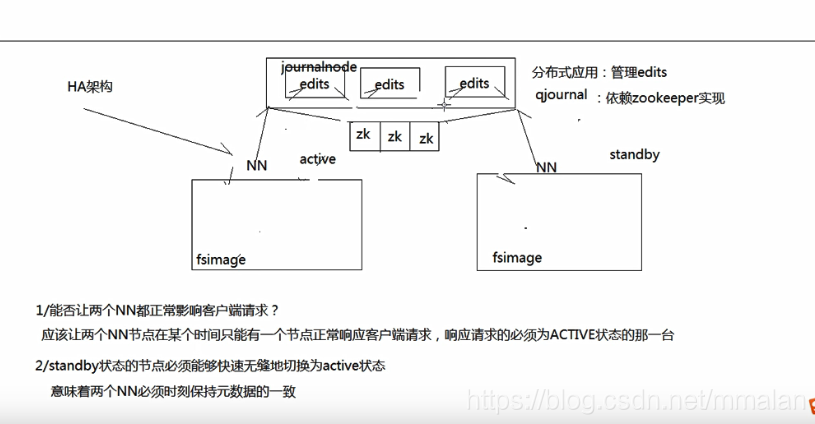
想要高可用 必须有两个namenode 一个active 一个standby namenode中的edits文件由第三方qjournal(依赖zookeeper)保存。
hive 流程
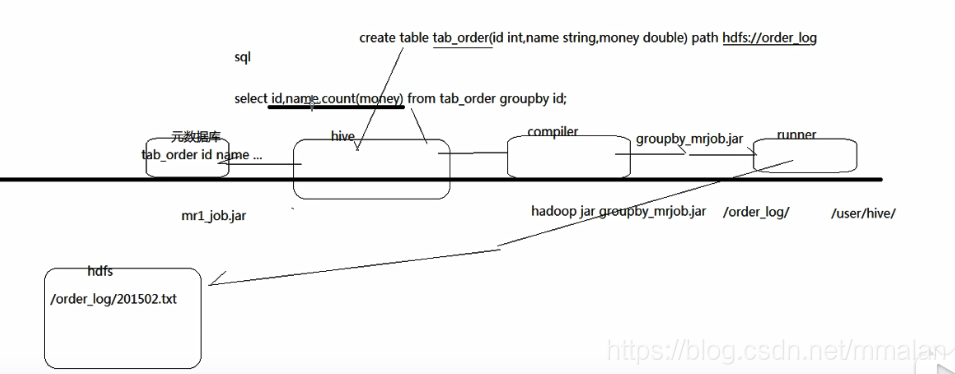
首先是create语句 会创建一些元信息存到元数据库 比如表名 创建时间
下次执行查询语句 先经过hive的compiler模块生成java jar包 然后经过runner模块提交jar包 运行程序。
hive 只能执行查询操作 不能进行进行添加操作
hive 导入本地数据到hive表里面 实际上数据是传到/user/hive/warehouse/数据库/表 里面
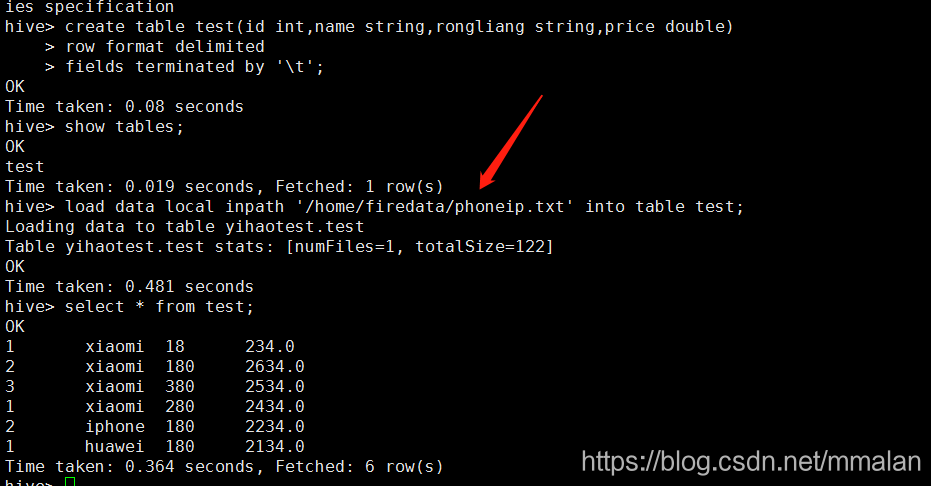
hive 里面表分为managed table 和external 表 managed的表 数据统一在./user/hive/warehouse 如果drop掉的话 元数据信息和数据都会删除。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









