




 本文介绍了针对广告检索场景设计的内核,强调纯内存存储、无锁化并发读写、空间碎片管理以及范式检索语义。内核分为底层存储、空间管理、数据结构等层次,支持Java和C++客户端,旨在实现高性能、高并发和灵活性。
本文介绍了针对广告检索场景设计的内核,强调纯内存存储、无锁化并发读写、空间碎片管理以及范式检索语义。内核分为底层存储、空间管理、数据结构等层次,支持Java和C++客户端,旨在实现高性能、高并发和灵活性。
一 设计思路
广告检索具有数据量较小、数据结构复杂、检索性能要求高、更新实时性要求高等特点。这要求设计者在进行内核整体设计时,需要做出倾向性的考量。
本文介绍的检索内核在设计思路上的主要前提如下:
- 纯内存存储
对比于文档搜索动辄TB量级的数据量来说,广告场景的数据量一般在10GB至100GB量级。当前业界主流的资源划分方式均可以提供10G至100GB大小的内存,因此为了追求高性能,广告索引大都采用纯内存存储方案。本文设计的内核使用Linux提供的mmap进行文件映射,对索引文件进行类似于内存的直接操作,目前并未对传统磁盘和SSD硬盘进行深入优化。
- 数据schema + 标准化数据接入协议
为了提高检索内核的通用性,同时降低业务方的开发成本,内核提供了通用的数据schema描述方式和标准化的数据接入协议。业务方可以根据业务自行定义复杂的数据结构,包括元组类型数据(支持嵌套)和表间关联(支持多级关联)结构。
- 无锁化并发读写
广告业务区别于搜索、推荐业务的另一大特征是有广告主行为的干预,如何及时响应广告主的各种操作是在广告系统设计初期就必须考虑的问题。为了同时保证读写的性能,业内通常利用轻量级原子操作实现无锁化并发读写。
- 空间碎片管理
实时数据更新过程中会无法避免的出现空间碎片,随着更新行为的持续,碎片会导致存储空间利用率降低,直至危及服务稳定性。一些开源的检索技术选型(如LevelDB、RocketDB、ElasticSearch等)采用本地数据定期合并的方式来进行空间碎片回收。但是这种方式会带来两个问题:一是会不定期出现写放大,影响检索性能;二是集群中同一份数据的多个副本机器会同时进行相同的合并计算,造成CPU的无畏开销。
本文介绍的内核通过两种方式的结合来解决空间碎片问题:一是在内核中实现了空间管理,通过复用的方式最大程度的减少空间碎片;二是通过定期切换全量数据的方式消除空间碎片。
- 范式检索语义
为了进一步降低业务方的使用成本,内核还提供了范式检索语义,可以快捷的指定检索表、检索键,同时可以声明筛选条件。
- Java/C++客户端
结合目前外卖广告业务发展现状、数据相关技术的生态、各语言特性以及团队成员技术栈分布,内核须提供Java和C++两种开发语言的客户端。
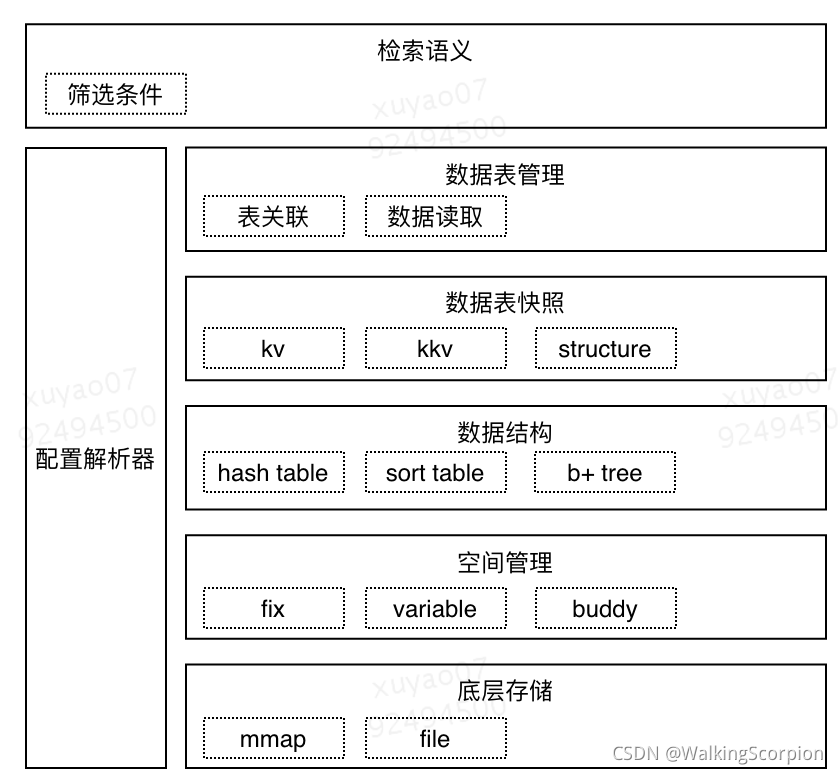
二 内核能力分层
为了内核代码 长期可维护 且 灵活可配置,在设计初期就对内核进行了清晰的分层定义。内核能力按照由底层向应用层的顺序分为如下几层:底层存储、空间管理、数据结构、数据表快照、数据表管理、检索语义。
- 长期可维护
每一层都有自己的职责范围,并定义了调用接口,开发同学通过开发插件的形式提供具体的功能实现。高层通过调用并组装底层的基础能力,实现更复杂的逻辑。
- 灵活可配置
每一层选用的具体插件支持通过配置接口暴露给业务方,这样业务方就可以通过配置的形式灵活选择每一层的具体实现插件。内核实现了配置解析器,除检索语义层外,其余各层的插件均可以通过配置文件自由选择。
2.1 底层存储
底层存储层管理数据与硬件存储设备之间的IO交互,负责对操作系统文件系统的读写操作。内核可在这一层实现对磁盘、SSD、AEP等存储介质的定制优化。
2.2 空间管理
空间管理层管理由于更新或删除产生的空间碎片,提高空间利用率。可以根据数据的实际使用场景选择适合的管理器,目前支持定长数据管理、变长数据线性管理和伙伴算法等管理方式。
2.3 数据结构
数据结构层实现了索引功能中使用的各种索引结构,并提供增删改查接口。常用的索引数据结构如Hash Table、顺序存储、B+树、跳表等。上层可以根据需要选择对应的数据结构。
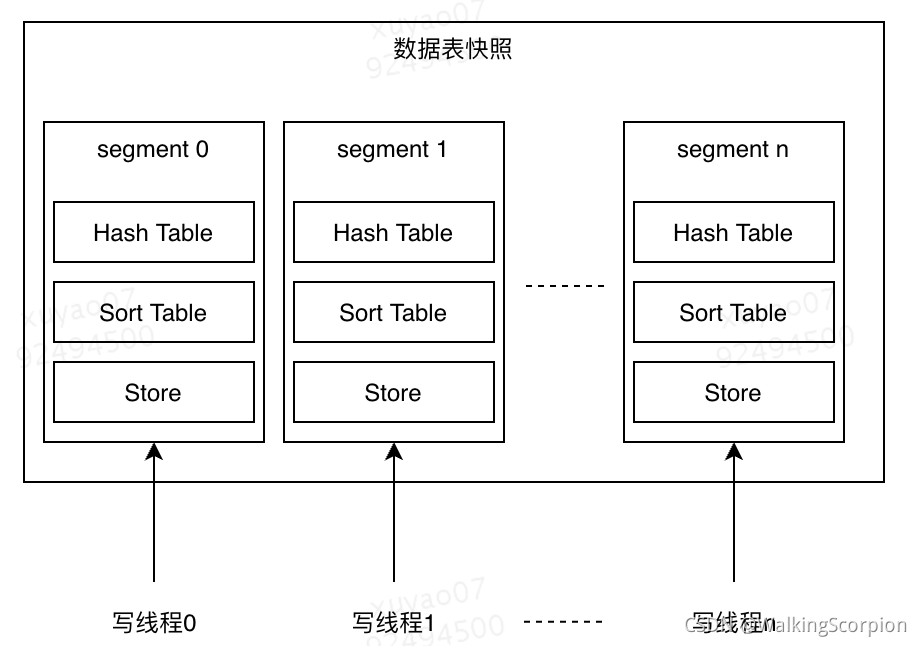
2.4 数据表快照
数据表快照层主要实现了如下功能:
组织并管理多个数据结构,对外提供数据表维度的检索/更新接口。
支持表内分段,每一个分段内部单线程更新,各分段之间可并行更新。分段数量可通过配置文件进行配置。
目前数据表按照类型分为kv、kkv和structure(结构化表)三种。
2.5 数据表管理
数据表管理层实现了多表统一数据版本管理以及表间关联查询逻辑。
多个表共同构成了一个数据版本,数据表管理实现了表名到表的路由。
若在schema中定义Unit表存在外键poiId关联至Poi表,则可以直接通过检索出的Unit表doc查询对应Poi表中的数据。关联关系支持嵌套。
2.6 检索语义
检索语义层实现了范式条件筛选,方便业务方进行定制化规则过滤。
三 数据存储
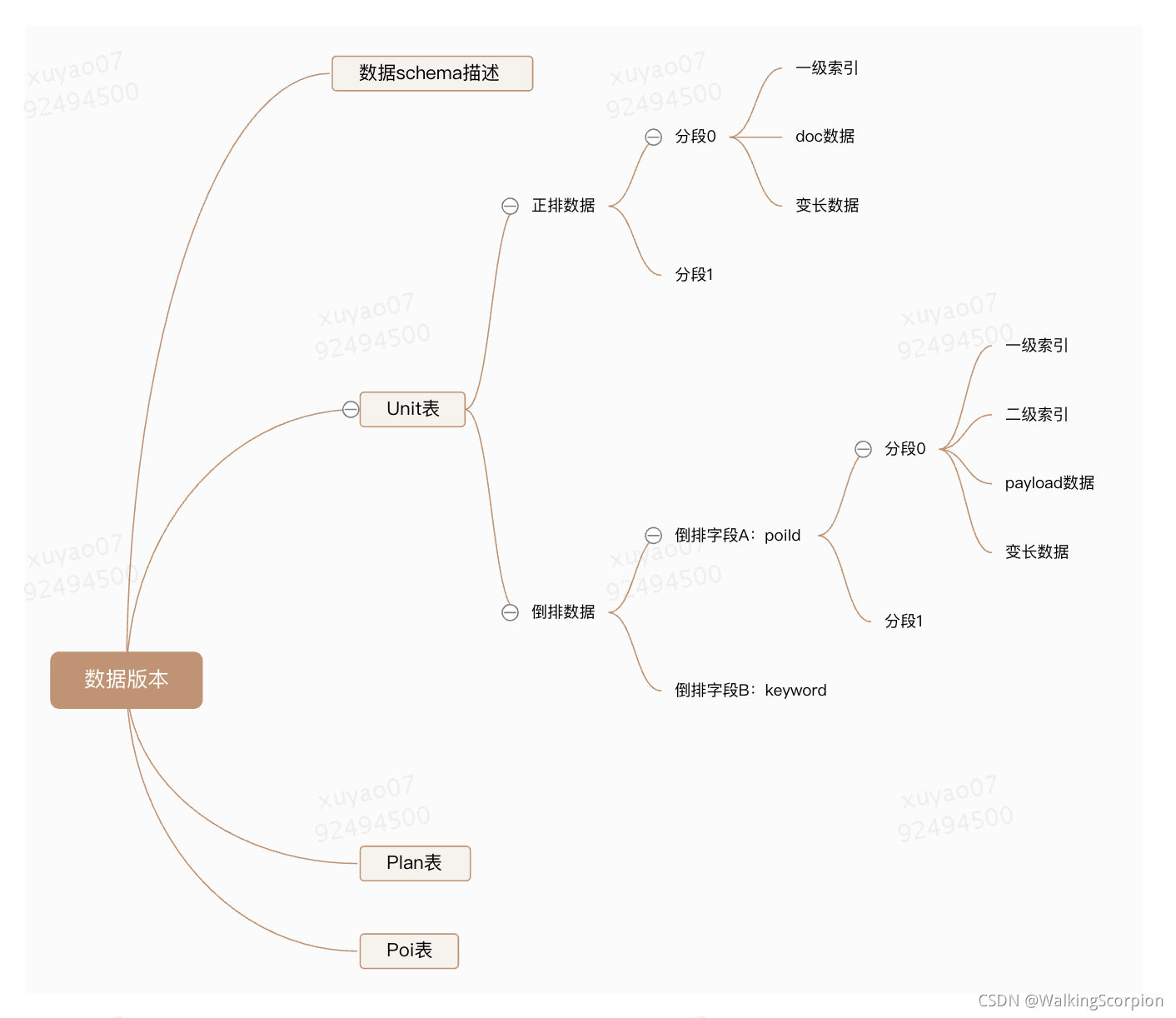
3.1 组织形式
3.2 正排检索
-
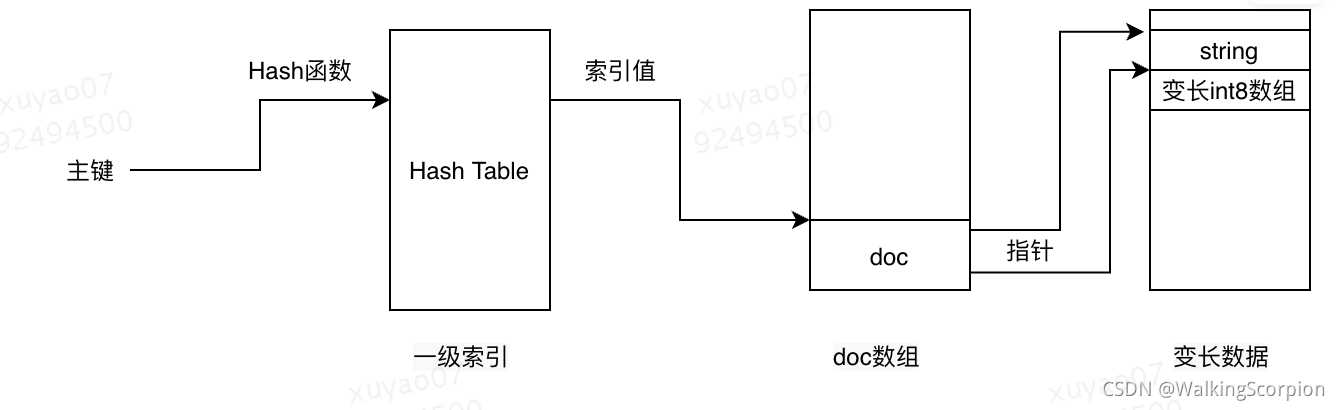
正排索引一级索引默认由一个Hash Table实现,数据分为doc数组区和变长数据区两个部分。
-
检索时将主键hash为一个散列值,该值取模后做为偏移地址查询Hash Table,得到索引值。索引值即为doc在doc数组中的偏移位置。
通过偏移位置获取doc信息,doc中存放了所有定长字段。对于doc中变长字段,doc中存放8字节偏移地址,实际数据存放在偏移地址指向的变长数据区中。
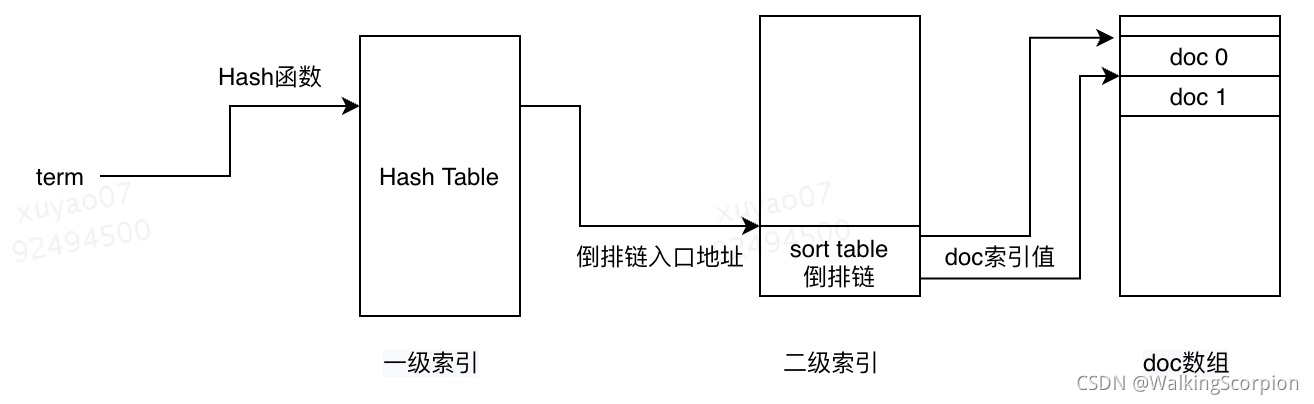
3.3 倒排检索
倒排索引分为一级索引和二级索引,一级索引通过term检索倒排链入口地址,二级索引通过倒排链获取doc正排索引地址。一级索引默认由Hash Table实现,二级索引默认由顺序存储实现。
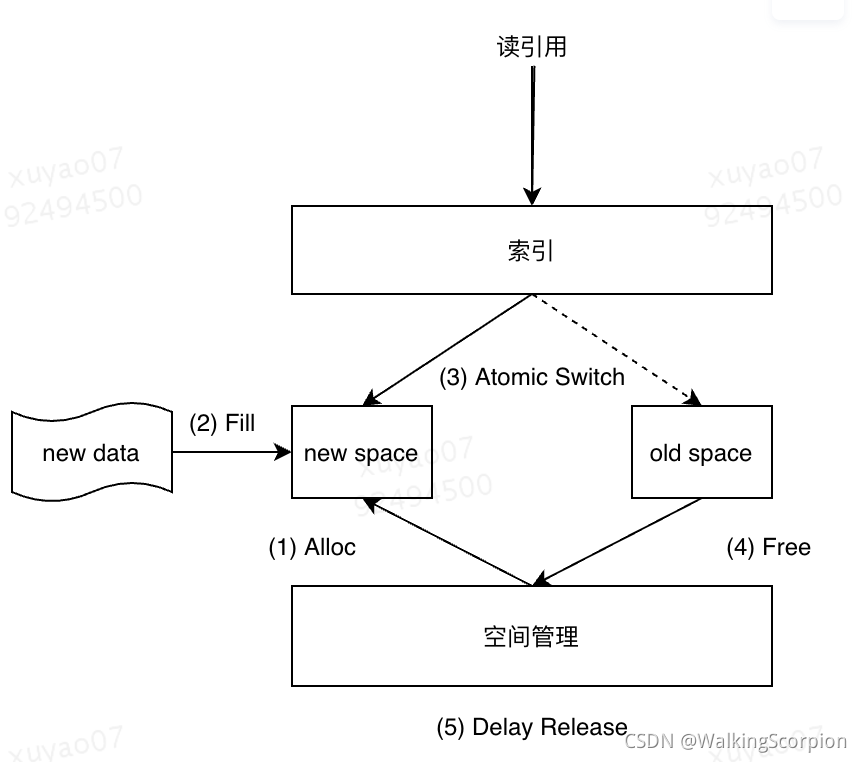
3.4 无锁并发读写
为了保证无锁并发读写,内核基于gcc编译器提供的原子操作进行数据写入,同时使用延迟释放技术确保读线程不会访问到失效地址。
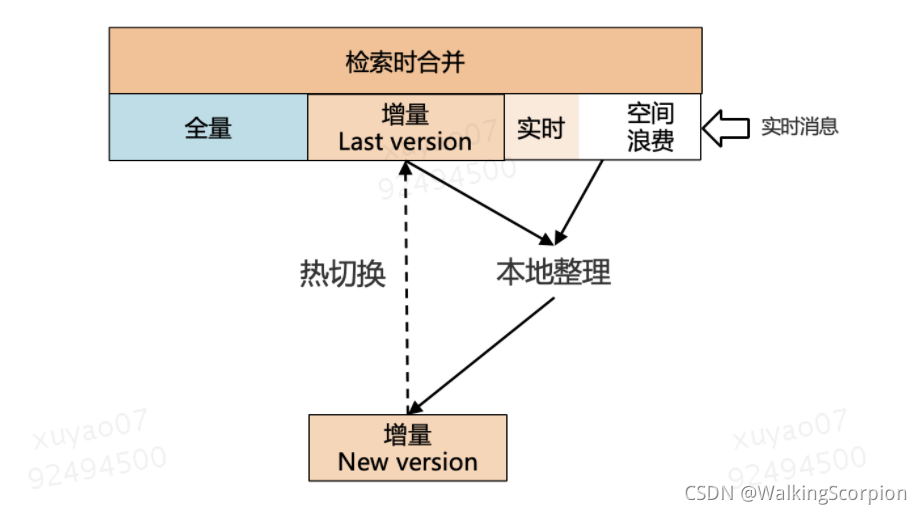
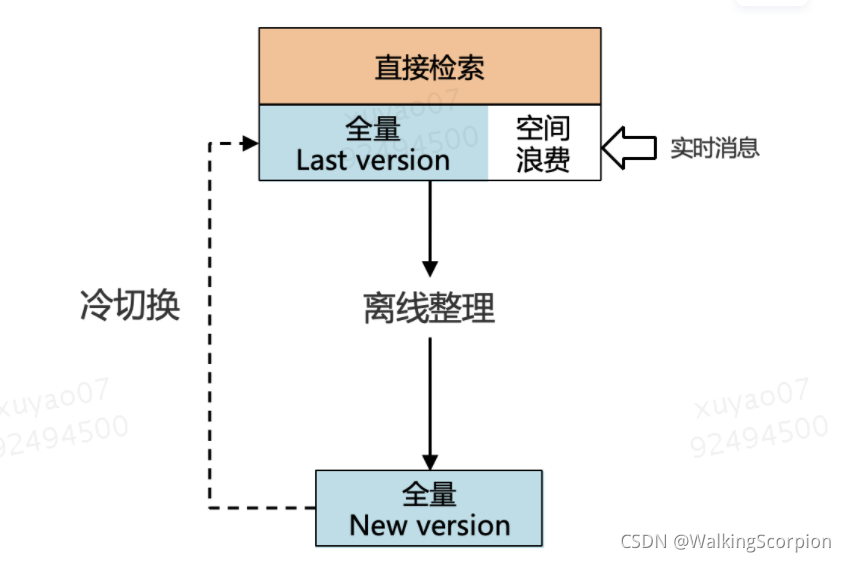
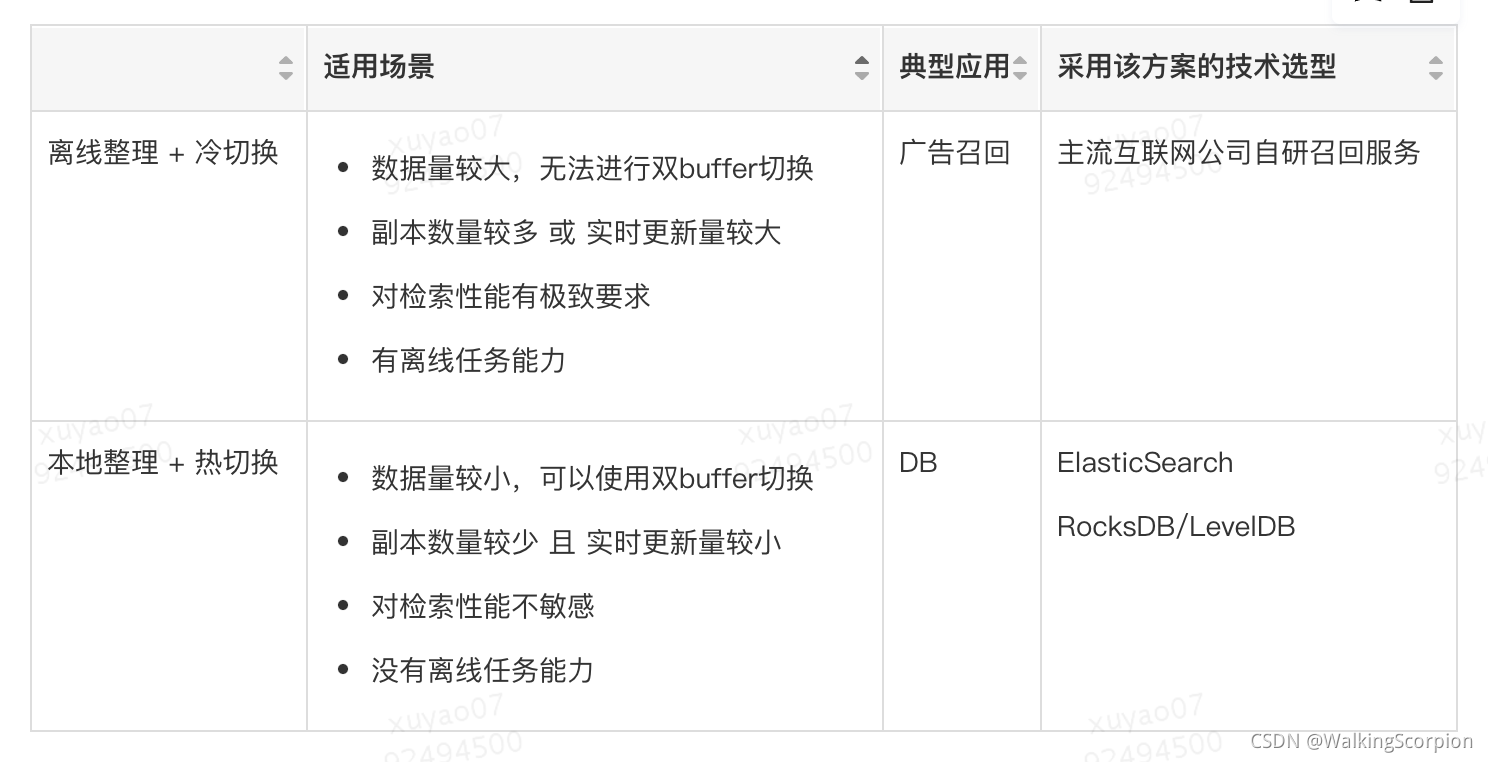
3.5 数据整理
目前业界有两种主流的数据整理方案,具体如下:
-
本地整理 + 热切换
-
离线整理 + 冷切换
四 Java接口
为了适应更多的业务场景,方便与主流数据处理成熟技术选型结合,内核通过JNI的方式实现了Java客户端,透出了检索和更新所需的主要能力。
需要注意的是,由于JNI会引入额外的性能开销,在一些相对复杂的场景下,使用Java客户端可能会导致性能问题。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









