






针对DeepSeek-R1模型输出中缺失<think>标签的问题,以下是详细修改tokenizer_config.json文件的操作步骤及原理说明:

1. 定位模型目录
- 路径说明:
模型目录通常包含模型权重文件(如.bin或.safetensors)、分词器文件(如tokenizer.json)以及配置文件(如config.json和tokenizer_config.json)。
例如:/path/to/model/deepseek-r1/ ├── config.json ├── tokenizer.json ├── tokenizer_config.json └── pytorch_model.bin
2. 备份原始文件
- 操作目的:
防止修改导致分词器异常或模型无法加载。 - 命令示例:
cp /path/to/model/deepseek-r1/tokenizer_config.json /path/to/model/deepseek-r1/tokenizer_config.json.bak
3. 编辑tokenizer_config.json文件
-
工具推荐:
使用文本编辑器(如VS Code、Notepad++)或命令行工具(如vim、nano)打开文件。 -
关键字段定位:
查找包含<think>标签的字段,通常出现在以下位置:{ "additional_special_tokens": ["<think>\\n", "<other_token>"], "chat_template": "<|begin_of_text|>{% for message in messages %}...{% endfor %}" }- 重点检查:
additional_special_tokens:额外特殊标记列表,可能包含"<think>\\n"。chat_template:对话模板,可能强制插入特定格式。
- 重点检查:
-
修改操作:
- 删除
<think>\\n中的换行符:
将"<think>\\n"改为"<think>",避免分词器在生成时强制追加换行符。{ "additional_special_tokens": ["<think>", "<other_token>"] } - 彻底移除字段(我是直接删除):
如果模型未明确依赖此字段,可直接删除包含<think>\\n的条目。
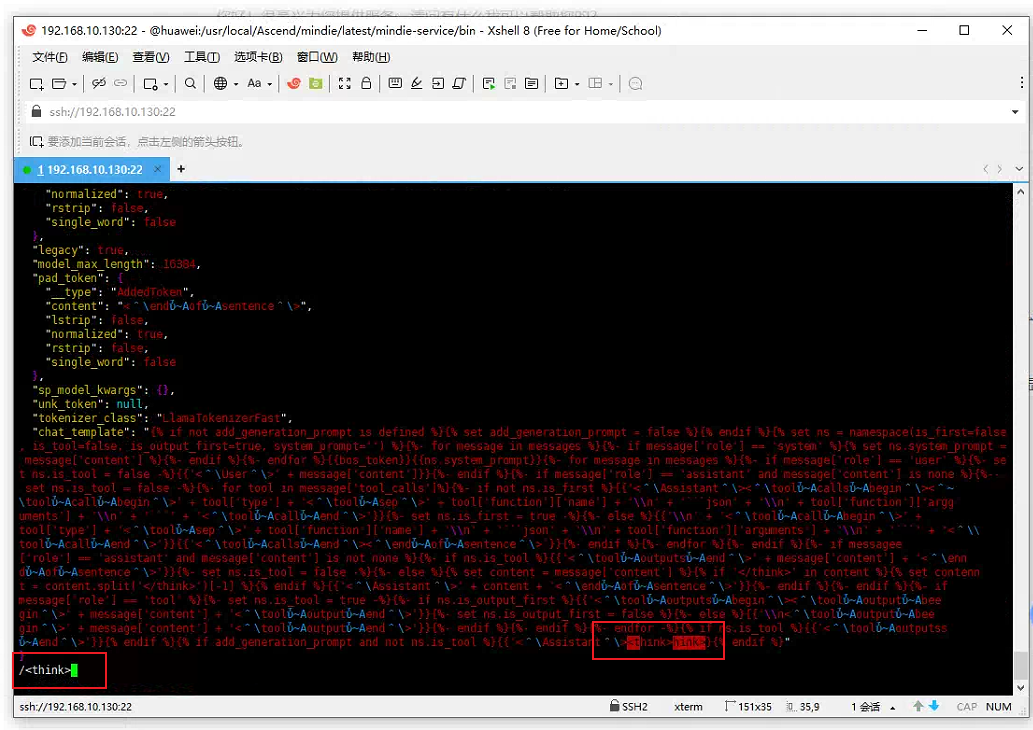
- 删除
4. 修改后的验证步骤
- 重启服务:
如果模型通过服务(如MindIE、vLLM、HuggingFace Transformers)运行,需重启服务以加载新配置。 - 测试生成结果:
输入以下提示词验证<think>标签是否正常输出:

这样就成功了


















 1612
1612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









