




 本文介绍了Hadoop、Hive和HBase的特点与应用场景。Hadoop是基础,Hive依赖它进行离线数据的分析,支持类SQL语句;HBase依赖Hadoop的HDFS模块,适用于实时计算。还对比了HDFS和HBase的优缺点,并通过实例说明二者在不同场景的应用。
本文介绍了Hadoop、Hive和HBase的特点与应用场景。Hadoop是基础,Hive依赖它进行离线数据的分析,支持类SQL语句;HBase依赖Hadoop的HDFS模块,适用于实时计算。还对比了HDFS和HBase的优缺点,并通过实例说明二者在不同场景的应用。
1、hadoop:它是一个分布式计算+分布式文件系统,前者其实就是MapReduce,后者是HDFS。后者可以独立运行,前者可以选择性使用,也可以不使用
2、hive:通俗的说是一个数据仓库,仓库中的数据是被hdfs管理的数据文件,它支持类似sql语句的功能,你可以通过该语句完成分布式环境下的计算功能,hive会把语句转换成MapReduce,然后交给hadoop执行。这里的计算,仅限于查找和分析,而不是更新、增加和删除。它的优势是对历史数据进行处理,用时下流行的说法是离线计算,因为它的底层是MapReduce,MapReduce在实时计算上性能很差。它的做法是把数据文件加载进来作为一个hive表(或者外部表),让你觉得你的sql操作的是传统的表。
3、hbase:通俗的说,hbase的作用类似于数据库,传统数据库管理的是集中的本地数据文件,而hbase基于hdfs实现对分布式数据文件的管理,比如增删改查。也就是说,hbase只是利用hadoop的hdfs帮助其管理数据的持久化文件(HFile),它跟MapReduce没任何关系。hbase的优势在于实时计算,所有实时数据都直接存入hbase中,客户端通过API直接访问hbase,实现实时计算。由于它使用的是nosql,或者说是列式结构,从而提高了查找性能,使其能运用于大数据场景,这是它跟MapReduce的区别。
总结:
hadoop是hive和hbase的基础,hive依赖hadoop,而hbase仅依赖hadoop的hdfs模块。
hive适用于离线数据的分析,操作的是通用格式的(如通用的日志文件)、被hadoop管理的数据文件,它支持类sql,比编写MapReduce的java代码来的更加方便,它的定位是数据仓库,存储和分析历史数据
hbase适用于实时计算,采用列式结构的nosql,操作的是自己生成的特殊格式的HFile、被hadoop管理的数据文件,它的定位是数据库,或者叫DBMS
最后补充一下:hive可以直接操作hdfs中的文件作为它的表的数据,也可以使用hbase数据库作为它的表
HDFS和Hbase究竟是什么?
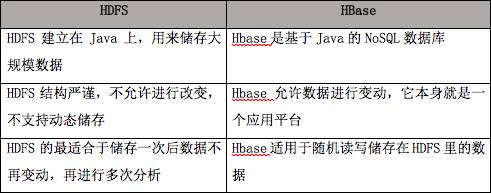
HDFS容错率很高,即便是在系统崩溃的情况下,也能够在节点之间快速传输数据。HBase是非关系数据库,是开源的Not-Only-SQL数据库,它的运行建立在Hadoop上。HBase依赖于CAP定理(Consistency, Availability, and Partition Tolerance)中的CP项。
HDFS最适于执行批次分析。然而,它最大的缺点是无法执行实时分析,而实时分析是信息科技行业的标配。HBase能够处理大规模数据,它不适于批次分析,但它可以向Hadoop实时地调用数据。
HDFS和HBase都可以处理结构、半结构和非结构数据。因为HDFS建立在旧的MapReduce框架上,所以它缺乏内存引擎,数据分析速度较慢。相反,HBase使用了内存引擎,大大提高了数据的读写速度。
HDFS执行的数据分析过程是透明的。HBase与之相反,因为其结构基于NoSQL,它通过在不同的关键字下进行排序而获取数据。
通过实例来加强对HDFS和HBase的理解
实例1
Cloudera对欧洲银行使用HBase的过程进行优化
HBase是实时数据处理环境的最佳典范。我们的一个客户是某欧洲著名银行,下面要举的就是这个客户的例子,恰到好处的说明了问题。我们同时使用了Apache Storm和Apache Hbase,来分析应用服务器和网页服务器上的日志数据,想以此得到一些新发现。因为单位时间内我们需要处理大量的数据,所以我们最终决定使用HBase而不是HDFS。HDFS不能处理高速流动的数据。结果令人震惊,搜索时间从3天变成了3分钟。
实例2
使用HDFS和MapReduce作为全球快速消费品巨头的分析方案
我们的一位客户是全球饮料业巨头,它要求我们做一些批次分析,这些分析必须精确到某一特定仓库的进出量。分析中需要使用一些迭代分析和序列分析。HDFS和MapReduce就很适应这种工作需求,表现要比建立在HBase上的Hive要好。MapReduce解决数据预处理,将数据准备好作下一步的分析。之后Hive接管任务,去做顾客分析。结果非常好,出顾客分析报告的时间由3天缩短为3小时。
HDFS 和 HBase 比较表格

















 2916
2916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









