




文章目录
为什么GPU适合做ETL
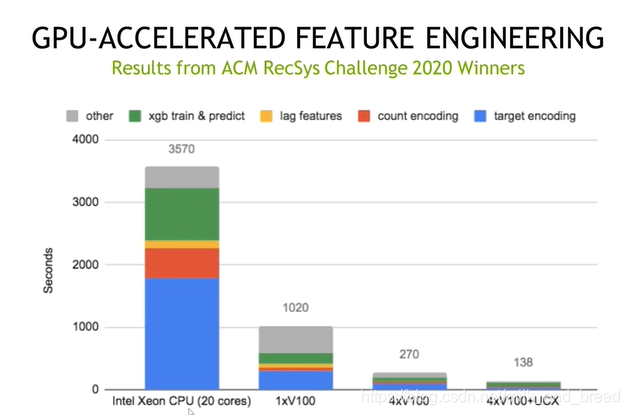
图为ACM特征工程比赛运行耗时比较:使用1块GPU(V100)大约比cpu(至强)提升3倍。4块GPU(V100)+UCX提升25倍。
RAPIDS(科学计算体系)
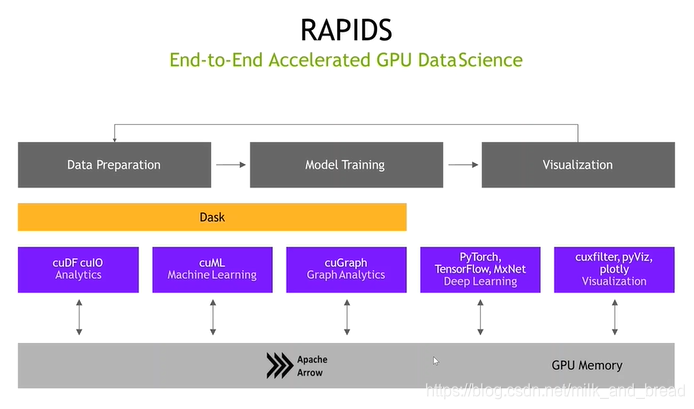
RAPIDS体系结构用于科学计算,应用层介绍如下:
RAPIDS提供cuDF cuIO(类似于pandas调用GPU)、cuML(回归与分类算法GPU计算)、cuGraph(计算图)、DeepLearning(GPU计算框架)、cuxfillter(可视化)五类应用方向。
ETL主要使用的也就是cuDF cuIO(GPU处理大数据。补充:Desk用于多台数据处理)。
cuDF技术栈
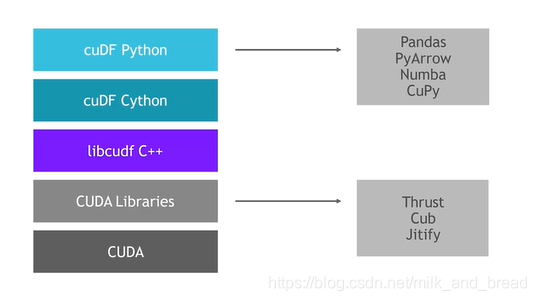
cuDF应用层级使用python主流的数据处理的包完成GPU加速。

cuDF使用用例,使用基本与pandas相似,底层调用Cuda加速处理。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









