




 本文探讨了Python中字典的使用,包括字典的定义、数据存储案例、异常处理、统计排序及删除操作。通过具体案例展示了如何利用字典进行高效的数据管理和统计分析。
本文探讨了Python中字典的使用,包括字典的定义、数据存储案例、异常处理、统计排序及删除操作。通过具体案例展示了如何利用字典进行高效的数据管理和统计分析。
字典
字典定义
字典相当于关联数组,由key-value键值对组成。
用字典存储数据(案例)
给出以下数据:
saasdf sd,2002-6-17,2:28,2.58,2:39,2-25,2.58
存入字典中,分别为名字,日期,时间;时间需要格式化处理。
# lit = ["sdfs","2002-6-17","2:58","2.58","2.18"]
#对时间字符串进行处理,格式的统一化
def sanitize(time_string):
if '-' in time_string:
splitter = "-"
elif ':' in time_string:
splitter = ":"
else:
return (time_string)
(mins,secs) = time_string.split(splitter)
return (mins + '.' + secs)
# 字典存储数据
def get_coach_data(filename):
try:
with open(filename) as f:
data = f.readline()#saasdf sd,2002-6-17,2:28,2.58,2:39,2-25,2.58
print(type(data)) #读取文件的类型为str
sarah = data.strip().split(',')
print(type(sarah)) #字符串分割后的类型为list
#list对象pop函数弹出第一个对象,并赋值,这里按字典对象返回
return ({'Name': sarah.pop(0),
'DOB' : sarah.pop(0),
'Times' : sarah})
except IOError as ioerr:
print("File error :"+ str(ioerr))
return (None)
sarah_data = get_coach_data("aa")
if sarah_data != None:
#从右往左读,for循环依次去除时间字符串,
#每个一个字符串经过sanitize(),对时间进行格式化
#所有字符串格式化完毕后,放到集合对象中,保证时间字符串没有重复
#从小到大排序
print(sarah_data['Name'] +"`s fastest times are: "+ str(sorted(set([sanitize(t) for t in sarah_data['Times']])) ))
运行结果如下:
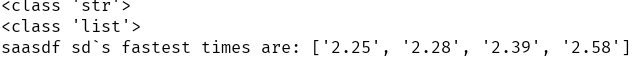
补充
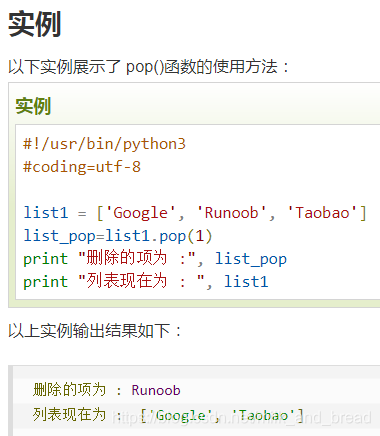
1、list对象的pop函数
2、异常处理的作用
当删除文件aa.txt,程序不会因错误而终止,而是继续运行。并返回错误信息。
try:
except IOError as ioerr:
print("File error :"+ str(ioerr))
文件丢失报错如下:
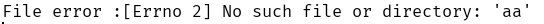
3、用字典统计前k个数出现的个数并按统计的个数排序(案例)
sortedDistIndicies= [2 3 1 0] #存储下标的列表
labels = ['A', 'A', 'B', 'B'] #类别
#按下标列表(sortedDistIndicies)找前k个类别(labels)出现的个数
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
#字典的get()方法:查找字典中的‘键’是否存在,不存在采用0,存在返回键对应的值
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#sorted:参数1:可迭代的对象,参数2:key:按第几列排序,参数3:reverse:是否按逆序排序
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
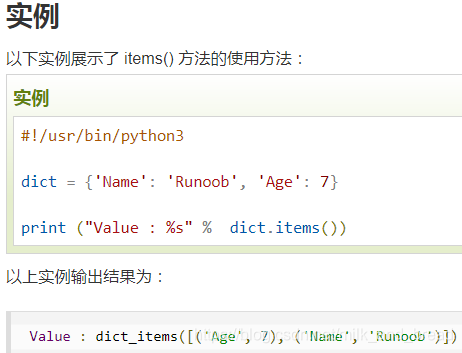
items()作用将字典键值对,变为元组的形式,并用列表存储
operator.itemgetter()用于取第几个位置的值,对于字典中的值来说,传入的参数为1

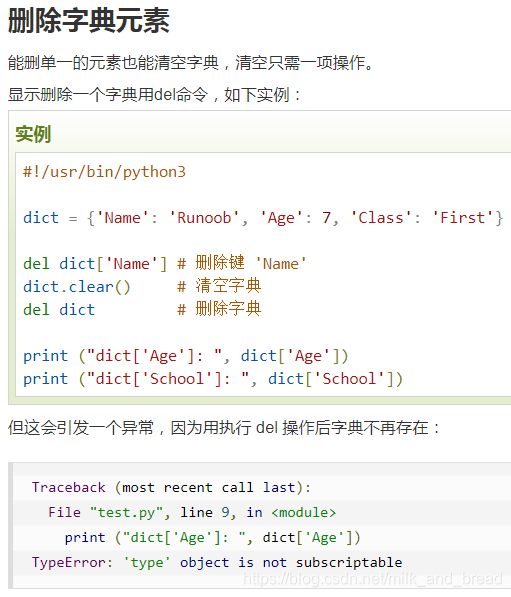
4、字典的删除操作

















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









