



 本文介绍了人脸检测的几种方法,重点讲解了OpenCV中使用的基于AdaBoost的Haar特征方法。内容包括AdaBoost的基本原理、核心思想、算法流程以及Haar特征的介绍,强调了积分图在快速计算中的作用。通过级联分类器,将多个弱分类器优化为强分类器,实现高效的人脸检测。
本文介绍了人脸检测的几种方法,重点讲解了OpenCV中使用的基于AdaBoost的Haar特征方法。内容包括AdaBoost的基本原理、核心思想、算法流程以及Haar特征的介绍,强调了积分图在快速计算中的作用。通过级联分类器,将多个弱分类器优化为强分类器,实现高效的人脸检测。
一、人脸检测的几种方法
1.基于人脸几何特征的方法
1)基于先验知识
2)基于模板
2.基于肤色的方法
3.基于人脸统计理论的方法
1)概述:将人脸检测的问题转化为统计学上的模式识别问题,即通过采用统计分析以及机器学习的方法,对人脸样本以及非人脸样本进行训练,得到各自的特征,从而构建一个人脸分类器。
2)效果:得到人脸的绝对坐标和大小
3)现有的主要方法:
#1基于特征空间的方法
#2基于人工神经网络的方法
#3基于支持向量机的方法
#4基于隐马尔科夫模型的方法
#5Boosting方法(OpenCV采用的方法)
二、AdaBoost(Adaptive Boost 自适应增强)
1.BOOSTING
基于PAC学习模型的理论分析,Valiant提出了Boosting算法,涉及软学习和强学习
弱学习(弱分类器 Weak Classifier):一个学习算法对一组概念的识别率只比随机识别好一点
强学习(强分类器 Strong Classifier):一个学习算法对一组概念的识别率很高
Kearns和Valiant提出了弱学习和强学习等价的问题并证明了只要有足够的数据,弱学习算法就可能通过继承的方式生成任意高精度的强学习方法。
这一理论是Boosting算法的基础,Boosting算法成了一个提升分类器精确性的一般方法。
1996年,Freund和Schapire提出了一个实际可用的自适应Boosting算法——AdaBoost。
2.adaboost的核心思想
adaboost是一种迭代算法,它针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
3.adaboost算法流程
输入图像->图像预处理->提取特征->训练分类器(二分类)->得到训练好的模型
接着给出测试过程
输入图像->图像预处理->提取特征->导入模型->二分类(是不是所要检测的物体)。
4.HAAR特征(HAAR-LIKE FEATURES)
Adaboost是一种算法(解决问题的架构),应用于人脸检测时就要用到HAAR特征(对问题的刻画)。
--------------------------------------------------(以下段落摘自wikipedia)-------------------------------------------------
是用于物体识别的一种数字图像特征。它们因为与哈尔小波转换 极为相似而得名,是第一种即时的人脸检测运算。
历史上,直接使用图像的强度(就是图像每一个像素点的RGB值)使得特征的计算强度很大。帕帕乔治奥等人提出可以使用基于哈尔小波的特征而不是图像强度[1] 。维奥拉和琼斯[2]进而提出了哈尔特征。哈尔特征使用检测窗口中指定位置的相邻矩形,计算每一个矩形的像素和并取其差值。然后用这些差值来对图像的子区域进行分类。
例如,当前有一个人脸图像集合。通过观察可以发现,眼睛的颜色要比两颊的深。因此,用于人脸检测的哈尔特征是分别放置在眼睛和脸颊的两个相邻矩形。这些矩形的位置则通过类似于人脸图像的外接矩形的检测窗口进行定义。
在维奥拉-琼斯目标检测框架的检测阶段,一个与目标物体同样尺寸的检测窗口将在输入图像上滑动,在图像的每一个子区域都计算一个哈尔特征。然后这个差值会与一个预先计算好的阈值进行比较,将目标和非目标区分开来。因为这样的一个哈尔特征是一个弱分类器(它的检测正确率仅仅比随机猜测强一点点),为了达到一个可信的判断,就需要一大群这样的特征。在维奥拉-琼斯目标检测框架中,就会将这些哈尔特征组合成一个级联分类器,最终形成一个强分类群。
哈尔特征最主要的优势是它的计算非常快速。使用一个称为积分图的结构,任意尺寸的哈尔特征可以在常数时间内进行计算。
------------------------------------------------------------------------------------------------------------------------------------------
5.积分图
积分图用于快速求矩形和,在一遍预处理后可以做到O(1)计算,极大的加速了计算过程,是HaarLikeFeature成功应用的关键,可以达到实时的要求(比如自拍相机)
6.adaboost路线图
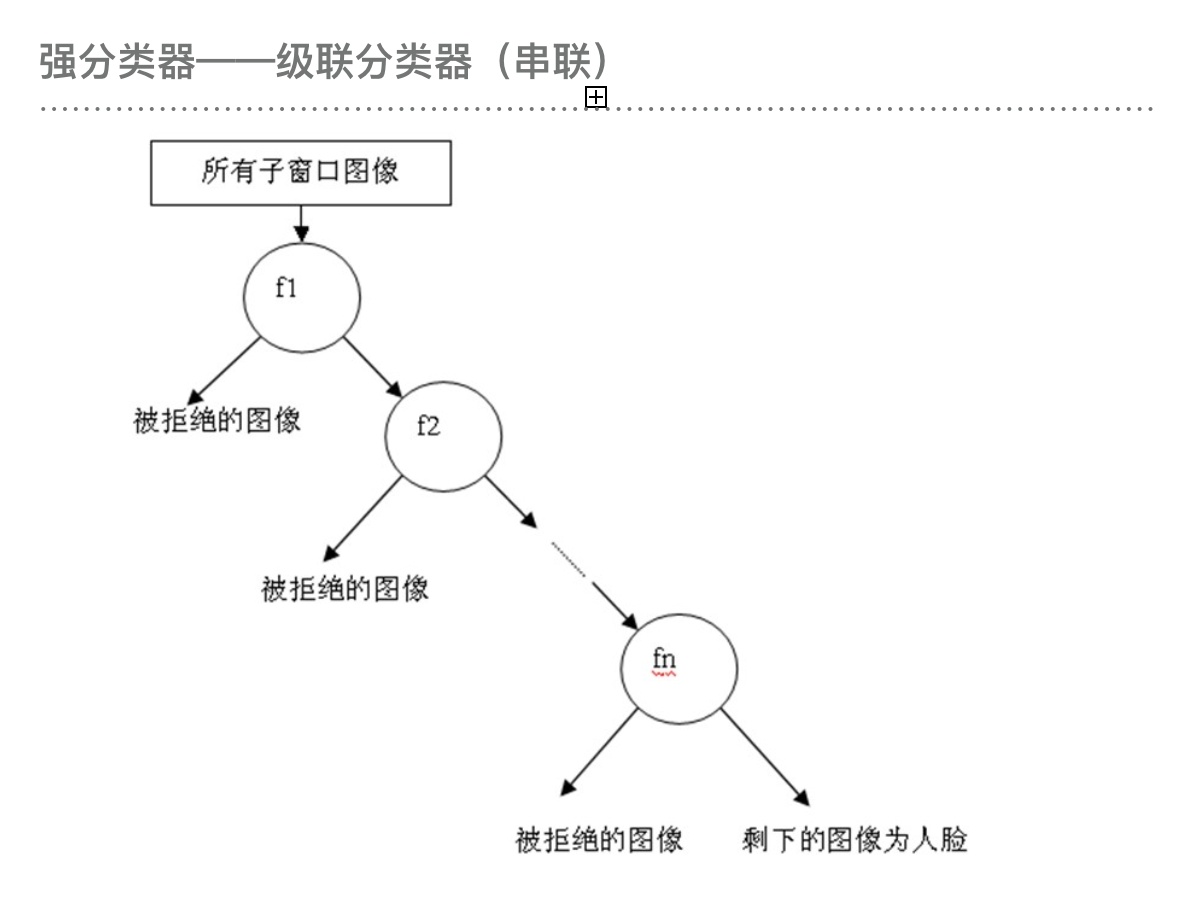
弱分类器->优化弱分类器->强分类器->级联分类器
1)弱分类器->优化弱分类器
弱分类器长什么样?
h(x,f,p, θ )=1(当pf(x)<pθ) or =0(其他)
x:子窗口图像
f:特征
p:指示不等号方向
θ:阈值
训练弱分类器的实质是寻找合适的阈值θ,使该分类器对所有样本的判读误差最低
2)优化弱分类器->强分类器(投票)
强分类器的诞生需要T轮迭代
#1给定训练样本集S,共M个样本(每次训练时取N个),其中X和Y分别对应于正样本和负样本;T为训练的最大循环次数。
#2初始化样本权重为1/N,即为训练样本的初始概率分布;
#3第一次迭代训练N个样本,得到第一个最优弱分类器(即利用N个样本给弱分类器设置合理的阈值)
#4提高上一轮中被优化弱分类器误判的样本的权重
#5将新的样本和上次优化弱分类器分错的样本放在一起进行新一轮的训练
#6循环执行4-5步骤,T轮后得到T个优化弱分类器。
#7组合T个最优弱分类器得到强分类器,组合方式如下:

3)强分类器->级联分类器


















 1952
1952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









