




 本文全面解析Redis作为高性能key-value数据库的特点,包括其应用场景如缓存、分布式锁等,深入探讨Redis为何快速,以及其数据类型、持久化策略、通讯协议、事务机制等内容。
本文全面解析Redis作为高性能key-value数据库的特点,包括其应用场景如缓存、分布式锁等,深入探讨Redis为何快速,以及其数据类型、持久化策略、通讯协议、事务机制等内容。
redis是什么
redis是一个高性能的key-value数据库(单机redis支持10W并发), 完全开源免费,且redis是一个NOSQL类型数据库
redis使用场景
缓存
持久化做数据库
分布式锁
管理分布式session
Dubbo的注册中心
消息队列
布隆过滤器
做高并发计数器
redis为什么快
1 基于内存操作,比传统关系型数据库IO操作,快指数级,存储结构是key-value形式,添加和查找操作时间复杂度是O(1),
2 采用单线程操作, 效率高(6.0版本引入多线程)
6.0版本以下redis是单线程的,复杂度不高, 不存在多线程或多进程间切换导致消耗时间和cpu的性能,也不用考虑加锁和锁释放问题, 不需考虑执行顺序不确定性问题。
6.0版本redis引入多线程做了优化
redis网络IO读写操作用到多线程, 但执行命令线程(worker工作线程)仍是单线程, 多线程IO读写操作利用CPU多核, 提高网络IO读写Socket的工作效率
3.底层基于IO多路复用, 采用epoll事件驱动,处理有效的事件请求。
redis支持5种常用和3种特殊数据类型
5种常用数据类型:
String(字符串)
List(列表)
Hash(哈希)
Set(集合)
ZSet(有序集合)
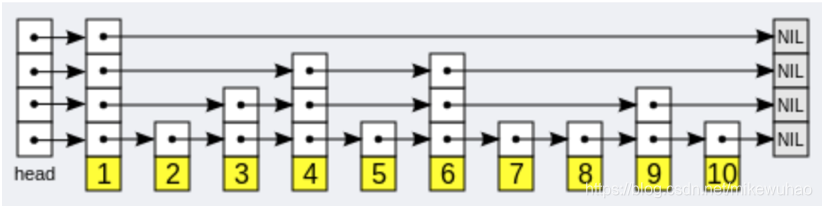
其中zset的数据结构是跳跃表
跳跃表的遍历总是从高层开始,然后随着元素值范围的缩小,慢慢降低到低层。
3种特殊数据类型:
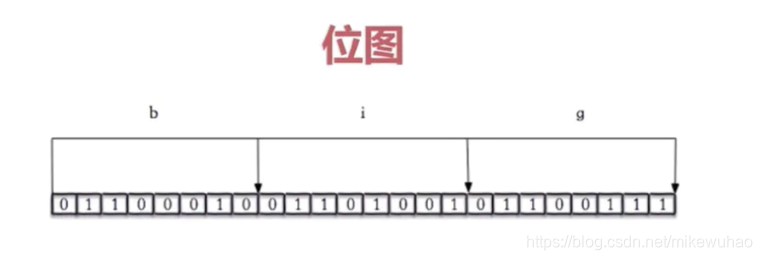
bitmap(位图)
用二进制表示的字节数组, 能够极大节省内存空间。可用于实现朋友圈点赞功能.
GEO
用于处理经纬度位置信息, 用于实现计算两个城市的距离操作
HyperLogLog
用于基数统计, 计数等, 比如统计用户在线人数, 但仅可以统计数量, 有一定误差值.
Redis的持久化策略
RDB (Redis Database)
rdb的持久化策略是生成当前全量数据的快照替换掉旧数据。
持久化时会新启一个进程去把当前数据生成快照, 周期性的保存到硬盘上生成rdb文件, 新的rdb会覆盖旧的rdb文件, 当redis重启时, 读取恢复rdb文件的内容到内存。
rdb操作的关键2个函数:
rdbSave和rdbLoad2个函数, 前者将redis的内存数据保存到硬盘上面, 后者会在redis重启时,rbd数据加载到内存里
rdb的触发条件:
触发的方法: 在redis的配置文件里自动触发, 默认设置了 3个策略, 比如15分钟内更改key, 按条件写入rbp文件到磁盘。

rdb的优点:
数据备份和恢复比AOF模式要快些, 重启单独的进程持久化, 主进程不会工作不会受影响,redis备份比较灵活, 可手动按周期定义备份策略.
rdb的劣势:
rdb是非实时保存数据, 一旦redis故障停机, 可能丢失前几分钟的数据, 如果数据量太大, 会造成服务器延迟卡顿现象.
AOF (Append-only file)
AOF的持久化策略是保存操作命令的增量数据
把操作redis的指令追加到redis的日志文件appendonly.aof里面。
AOF优点:
默认不开启, 若开启后, 把数据操作指令每秒同步追加到redis的日志中, 更安全可靠, 当AOF文件大小超过设置阈值时, 触发aof_rewrite函数, 把旧的AOF文件操作指令, 优化瘦身, 替换掉原来AOF文件。
(开启的AOF的流程 :在配置文件里面设置为 appendonly = true)
AOF缺点:
相同数量的数据, AOF的文件占用较大, 恢复速度较慢 , 对磁盘的负荷比较重 ,持久化效率较差
RDB与AOF的选择
做备份:当数据量大,且对恢复速度有要求,并且数据的一致性要求不高的话,可以只使用RDB
只做缓存:不用开启任何的持久化方式
两者都开启的建议:RDB数据不实时,同时使用两者时服务器只会找AOF文件,可不可以只使用AOF?建议不要,因为RDB更适合备份数据库(AOF在不断变化,不好备份),快速重启,而且不会又AOF可能潜在的BUG,留作万一的手段。
Redis的通讯协议
Redis服务器与客户端通过RESP(REdis Serialization Protocol)协议通信, 该协议简单实现, 解析快, 人类可读.
redis的事物机制
reids是支持事物的
在Redis中实现事务主要依靠以下几个命令来实现:

Redis事务从开始到结束通常会通过三个阶段: 事务开始、命令入队、事务执行
redis的哨兵模式
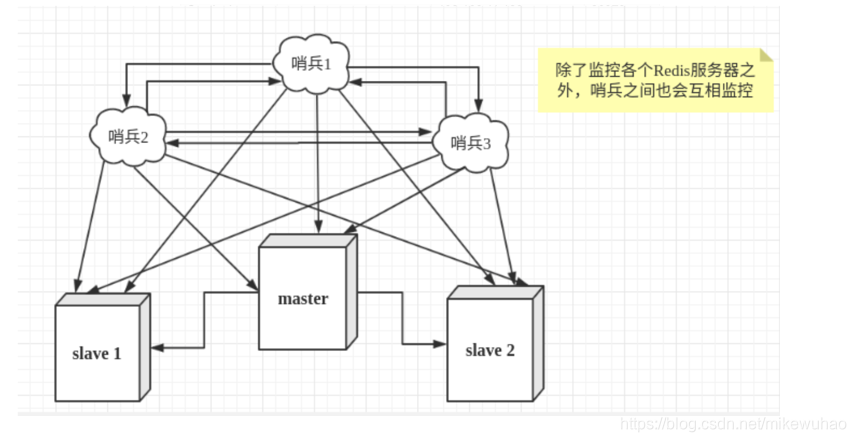
哨兵模式简介
用于监控redis集群中master主服务器的工作状态, 在Master主服务器发生故障的时候, 会自动故障迁移, 把其中的Slave替换失效的Master,以及redis.conf的配置文件也会发生改变
redis的选举
每个哨兵会向其他redis的节点每秒频率发送消息(ping命令)进行心跳检测, 确认对方是否活着. 如果指定时间内master节点没回复,认为master宕机, 投票选举新的master, 故障转移
选举过程:投票选举公式: 法人数+哨兵节点数/2, 当有slave达到这数值时会选举为master
Redis脑裂
脑裂原因
在正常redis集群下,通过master主节点写数据并同步到slave节点.
当网络发生问题时, 会产生2master个主节点, 共同写数据, 网络恢复后之前的master降为salve, 会导致数据不一致
脑裂解决方法
配置redis集群的参数
min-slaves-to-write 3,master的最少slave数量
min-slaves-max-lag 10,主从数据同步超时时间,10秒。
配置原来的master节点后, 如果出现脑裂, 是拒绝执行写操作的, 不会出现数据不一致情况
Redis缓存穿透
缓存穿透原因
redis中的key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
缓存穿透解决方案
简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
Redis缓存击穿
缓存击穿是什么
缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存击穿解决方法
1热点数据永不过期
2单独做个定时任务, 到快过期时刷新数据到缓存.(缺点:增加系统复杂度。比较适合那些 key 相对固定,cache 粒度较大的业务)
3查询redis当前key的剩余过期时间,如果小于一个阈值(比如1分钟),重新更新缓存.
4当缓存没有,查询数据库时,把查数据库的方法加个synchronized锁,避免同一时间多个线程查询DB
Redis缓存雪崩
缓存雪崩是什么
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时负载过高,压力过重.
缓存雪崩解决方法
1.尽量让缓存失效时间分散,防止某个时刻缓存集体失效(比如加个随机数)
2.加锁排队,在查询数据库的方法上面加上synchronized关键字,多余线程排队.
3.采用多级缓存
redis集群哈希槽
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。Redis 集群没有使用一致性hash, 而是引入了比较简单的哈希槽概念。

















 173万+
173万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









