




 本文介绍了如何使用全卷积网络(FCN)进行语义分割,通过跳跃连接和叠加利用深层和浅层特征图,解决语义信息和位置信息的结合问题。FCN通过将全连接层转换为卷积层,实现对任意大小输入的输出,并探讨了Adapting classifiers for dense prediction、Shift-and-stitch技术以及Patchwise training在语义分割中的作用。
本文介绍了如何使用全卷积网络(FCN)进行语义分割,通过跳跃连接和叠加利用深层和浅层特征图,解决语义信息和位置信息的结合问题。FCN通过将全连接层转换为卷积层,实现对任意大小输入的输出,并探讨了Adapting classifiers for dense prediction、Shift-and-stitch技术以及Patchwise training在语义分割中的作用。
- 论文链接:https://arxiv.org/pdf/1605.06211.pdf
- 论文题目:Fully Convolutional Networks for Semantic Segmentation
FCN
1 INTRODUCTION
语义分割有一个一直存在的矛盾是关于语义信息和位置信息的:全局信息解决what ,局部信息解决where。那么怎么做才可以使得语义信息和位置信息的结合呢?
本文通过跳跃连接和叠加来充分利用所有的特征图(这个想法和FPN类似),使得深层,像素粗糙但是语义强的特征图和浅层,像素精细,位置信息准确的特征图融合。
3 FULLY CONVOLUTIONAL NETWORKS
一个一般的网络其实就是在计算一个一般非线性方程。如果一个网络只有卷积操作来计算一个非线性滤波器,那么这个网络我们就叫做全卷积网络(FCN),全卷积网络接受任意大小的输入,生成对应大小的输出。
如果损失函数的结果是最后层的特征图维度求和的话
l
(
x
;
θ
)
=
∑
i
j
l
′
(
x
i
j
;
θ
)
l(\mathbf x;\theta)=\sum_{ij}l'(\mathbf x_{ij};\theta)
l(x;θ)=∑ijl′(xij;θ),那么参数的梯度同样也是特征图每个单元的参数梯度相加。因此在整个图像上计算
l
l
l的随机梯度下降和将最后一层感受野作为一个minibatch来计算
l
′
l'
l′的随机梯度是一样的。
当感受野重合很大的时候,对整张图像进行前后向传播比按patch来会更加有效。
3.1 Adapting classifiers for dense prediction
对于识别任务来说,我们会固定输入大小,且生成非空间维度的结果,这都是因为全连接层拥有固定的维度,且会将空间信息丢掉。其实全连接层可以视为对整个输入做卷积。那么自然将全连接层替换为卷积层就能对任意大小的输入输出空间特征图,如图2,而且比较下来,这种方法效率很高。
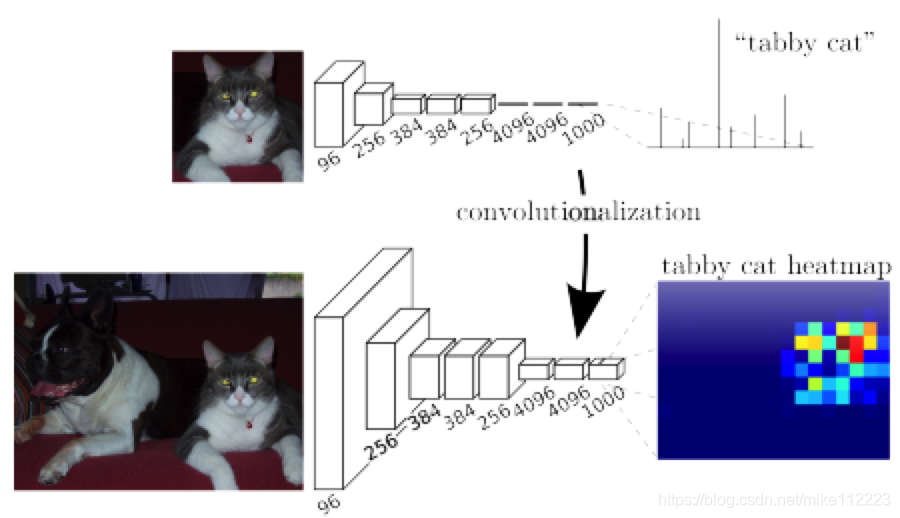
图2. 将全连接层转换为卷积层就能使得识别网络输出一个空间特征图。加入可微分的插值层以及一个空间loss就能得到一个有效的end-to-end的像素级学习machine。
3.2 Shift-and-stitch is filter dilation
shift-and-stitch,平移再缝合。这个概念参考下面这篇博文,写的比较清楚,不重复了。
https://www.jianshu.com/p/e534e2be5d7d
那么为了实现dense prediction,我们可以引入shift-and-stitich的思路。
那么现在我们考虑一个层(卷积或者池化),它的输入是带有s步长的,然后后续还跟着有个卷积核
f
i
j
f_{ij}
fij的卷积层。通过以s上采样它的输出来将前面层的输出的步长调整1(这个时候的特征图就和原图一样大了,按理说,我们直接使用带padding的conv就能够实现dense prediction)。然而,单纯使用原始的conv
f
i
j
f_{ij}
fij来卷积这个经过upsampled的特征图并不能得到和shift-and-stitich同样的结果,原因很简单,同样大小的kernel在upsampled的输入上看到的区域只是原来的一部分了。为了达到同样的效果,就需要构建一个新的卷积核(dilate conv):
f
i
j
′
=
{
f
i
/
s
,
j
/
s
if
s
divides both
i
and
j
;
0
otherwise
,
f'_{ij} = \begin{cases} f_{i/s,j/s} & \text{if} \ s \ \text{divides both} \ i \ \text{and} \ j; \\ 0 & \text{otherwise}, \end{cases}
fij′={fi/s,j/s0if s divides both i and j;otherwise,
也就是卷积核变大了,变空洞了,是原来的
s
×
s
s\times s
s×s倍。那么只要在网络中反复使用这个结构把所有的下采样效果都移除了,那么dense prediction就完成了。
简单的减少降采样次数是一个tradeoff:卷积核就能得到更加精细的信息,但是感受野变小,计算量变大。上面提到的膨胀操作也是一个tradeoff:在没有减少卷积核感受野的情况下使得输出denser,但是卷积核无法跟之前的卷积核一样,在一个finer的尺度上提取信息。
本文并没有使用dilation的方法,而是使用了带学习的上采样。
3.4 Patchwise training is loss sampling
这部分,我翻译一下下面链接中的回答,有助于对本段的理解。
https://stackoverflow.com/questions/42636685/patch-wise-training-and-fully-convolutional-training-in-fcn
术语“Patchwise training”,是为了避免全图训练带来的冗余。在语义分割中,任务是要对图像的每个像素进行分类,使用全图训练的话,输入会引入大量冗余(这里冗余个人理解为,在大致相同场景下,背景像素基本不变,且经常出现)。一个标准的解决方法就是从训练集中随机采样一组patch输入网络学习(这里patch表示,对于感兴趣的目标,取它周围小范围的图像)。这个“patchwise training”就保证了输入有足够的方差,并且它能代表训练集的真实分布(mini-batch应该跟训练集有同样或者相似的数据分布)。这个技巧还能够帮助训练收敛更快,且解决类不平衡问题(就一般背景点都是远大于实例像素的)。本文提出没有必要使用patchwise training,如果你想要平衡类,可以对loss进行分配权重或者对loss进行采样。另一个角度来说,对于逐像素分割来说,全图训练还有一个问题,就是输入图像带有太多的空间相关性。为了解决这个问题,要么采样patch训练,要么对于全图训练采样loss。这也印证了标题“Patchwise training is loss sampling”。采样loss的方法就是随机忽视掉最后层的一些神经元,这样它的loss就不会被计算。
4 SEGMENTATION ARCHITECTURE
4.3 Combining what and where
我们定义了一种新的FCN来进行语义分割,如下图。
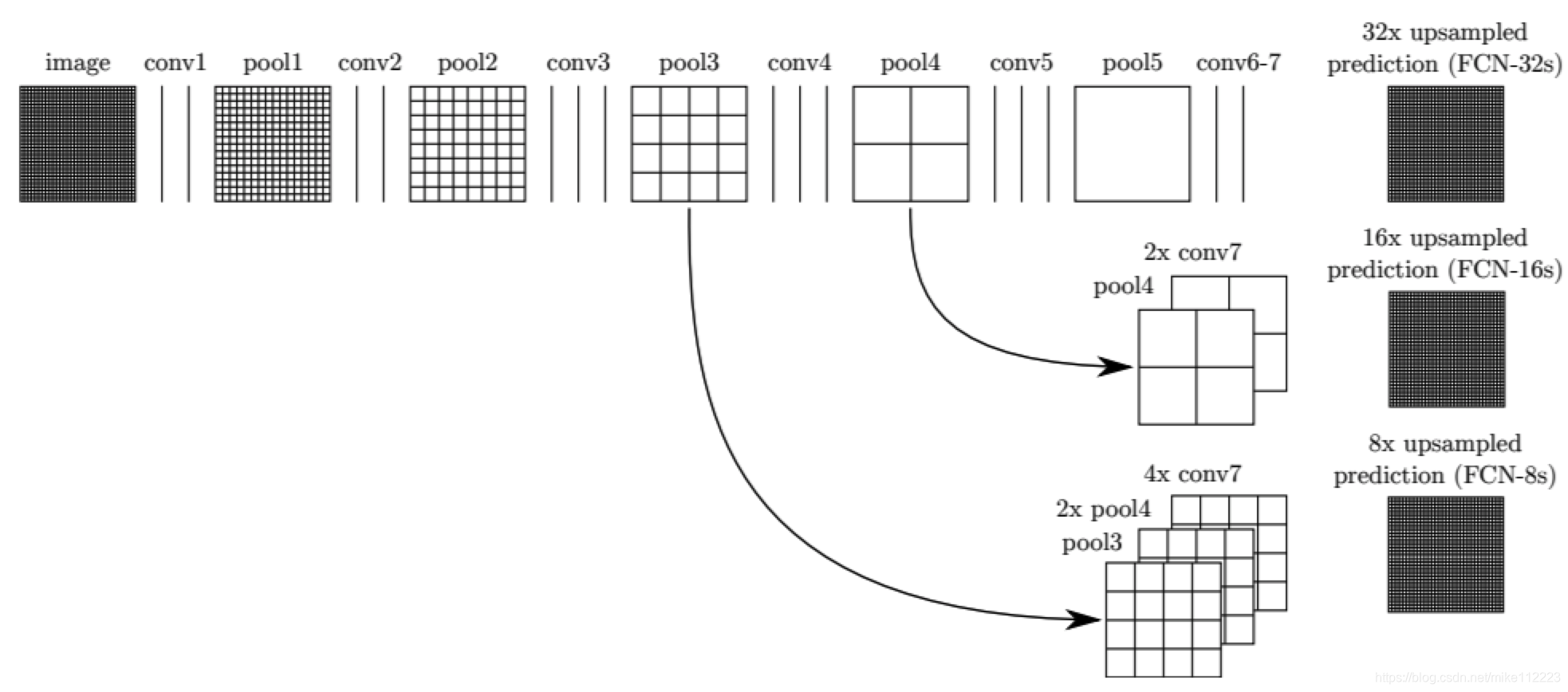
图3. 有向无环图网络,结合低像素高语义信息和高像素低语义信息。
这部分我就不赘述了,看过FPN的朋友应该很快就理解了,只不过FPN用的是upsample,FCN用的是反卷积,也就是带学习参数,然后都是用的element-wise sum。
Conclusion
这篇没有全文翻译,本质上就是将用于识别的网络的全连接层替换成卷积层来进行语义分割,同时类似于FPN引入不同语义层的叠加来得到更好的语义分割效果。

















 1151
1151




 到【灌水乐园】发言
到【灌水乐园】发言







