




 本文介绍了如何在服务器上使用QuestEval(NAACL2021论文)进行摘要事实一致性检测,包括创建conda虚拟环境、本地加载HuggingFace模型、以及针对服务器无法访问HuggingFace时的适配。重点在于QuestEvalMetric的本地化使用和BERTScore库的修改。
本文介绍了如何在服务器上使用QuestEval(NAACL2021论文)进行摘要事实一致性检测,包括创建conda虚拟环境、本地加载HuggingFace模型、以及针对服务器无法访问HuggingFace时的适配。重点在于QuestEvalMetric的本地化使用和BERTScore库的修改。
以下是复现论文《QuestEval: Summarization Asks for Fact-based Evaluation》(NAACL 2021)代码https://github.com/ThomasScialom/QuestEval/的流程记录:
-
在服务器上conda创建虚拟环境questeval(python版本于readme保持一致,為3.9)
conda create -n questeval python=3.9 -
git clone下载项目代码于本地,用pycharm打开并远程连接到服务器的该环境中。
-
服务器上进入该项目目录,安裝本项目需要的库。
pip install -e . -
这个项目作者开源的其实是功能包,真正的主程序要自己创建,不过作者封装得很漂亮,只需要在项目根目录下新建一个python文件,如
run.py,然后拷贝以下内容:(大体作者都在README.md中给出了,这里我是想用QuestEval模型去做摘要事实一致性检测)from questeval.questeval_metric import QuestEval questeval = QuestEval(no_cuda=False, task="summarization", do_weighter=True) source_1 = "Since 2000, the recipient of the Kate Greenaway medal has also been presented with the Colin Mears award to the value of 35000." prediction_1 = "Since 2000, the winner of the Kate Greenaway medal has also been given to the Colin Mears award of the Kate Greenaway medal." references_1 = [ "Since 2000, the recipient of the Kate Greenaway Medal will also receive the Colin Mears Awad which worth 5000 pounds", "Since 2000, the recipient of the Kate Greenaway Medal has also been given the Colin Mears Award." ] source_2 = "He is also a member of another Jungiery boyband 183 Club." prediction_2 = "He also has another Jungiery Boyband 183 club." references_2 = [ "He's also a member of another Jungiery boyband, 183 Club.", "He belonged to the Jungiery boyband 183 Club." ] if __name__ == "__main__": score = questeval.corpus_questeval( hypothesis=[prediction_1, prediction_2], sources=[source_1, source_2], list_references=[references_1, references_2] ) print(score) -
如果服务器能够顺利连接huggingface,那么直接执行就跑通了,作者的代码没有任何bug。然而对于服务器访问不了huggingface的朋友们(比如我qwq),那么就需要把所有涉及远程加载模型的代码修改成本地加载的逻辑。
-
先在huggingface把需要的模型给传进服务器里。我个人把下载好的模型文件会放在
/dev_data_2/zkyao/pretrain_model/下。这里需要下载的模型有:t5-qa_squad2neg-en,t5-qg_squad1-en,t5-weighter_cnndm-en,bert-base-multilingual-cased。 -
首先修改
questeval/questeval_metric.py。作者把加载QuestEval框架所涉及到的模型的逻辑全部写在了_load_all_models()方法中。修改这几个部分:# models['hyp']['QA'] = f'{HF_ORGANIZATION}/t5-qa_squad2neg-en' models['hyp']['QA'] = "/dev_data_2/zkyao/pretrain_model/t5-qa_squad2neg-en" # models['hyp']['QG'] = f'{HF_ORGANIZATION}/t5-qg_squad1-en' models['hyp']['QG'] = "/dev_data_2/zkyao/pretrain_model/t5-qg_squad1-en"# models['Weighter'] = self.get_model(model_name=f'{HF_ORGANIZATION}/t5-weighter_cnndm-en') models['Weighter'] = self.get_model(model_name="/dev_data_2/zkyao/pretrain_model/t5-weighter_cnndm-en") -
接下來就是特别隐蔽的库源码了,因为huggingface提供的
metrics组件内部实现逻辑,是要加载模型的。然而正不巧的是,这里用到的metric——bert_score,源码的开发者显然不会考虑到服务器访问不了huggingface的我们。bert_score库的scorer.py代码的这部分,将模型类型和模型路径同时用self.model_type属性指代,导致把逻辑写死了必须远程加载模型。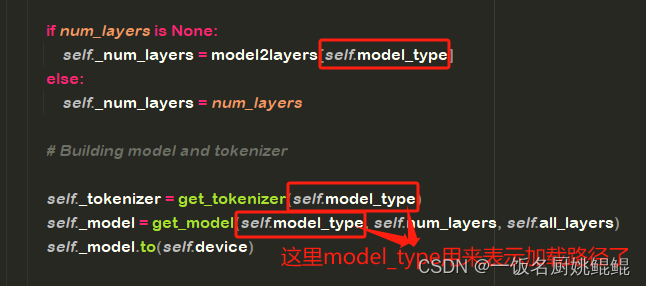
为了能本地加载模型,不得不这样了。打开
/{path_to_your_env}/lib/python3.9/site-packages/bert_score/scorer.py,作出如下修改:
-
-
接下来整个测试程序就能顺利执行了!


















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









