






 本文介绍了一个使用TensorFlow搭建的卷积神经网络(CNN),包括网络结构定义、训练过程及性能评估等内容。通过实例展示了如何逐步添加卷积层与全连接层,并实现手写数字识别任务。
本文介绍了一个使用TensorFlow搭建的卷积神经网络(CNN),包括网络结构定义、训练过程及性能评估等内容。通过实例展示了如何逐步添加卷积层与全连接层,并实现手写数字识别任务。
dp.py 中定义了CNN网络
# 新的 refined api 不支持 Python2
import tensorflow as tf
from sklearn.metrics import confusion_matrix
import numpy as np
class Network():
def __init__(self, train_batch_size, test_batch_size, pooling_scale):
"""
@num_hidden: 隐藏层的节点数量
@batch_size:因为我们要节省内存,所以分批处理数据。每一批的数据量。
"""
self.train_batch_size = train_batch_size
self.test_batch_size = test_batch_size
# Hyper Parameters
self.conv_config = [] # list of dict
self.fc_config = [] # list of dict
self.conv_weights = []
self.conv_biases = []
self.fc_weights = []
self.fc_biases = []
self.pooling_scale = pooling_scale
self.pooling_stride = pooling_scale
# Graph Related
self.tf_train_samples = None
self.tf_train_labels = None
self.tf_test_samples = None
self.tf_test_labels = None
# 统计
self.merged = None
self.train_summaries = []
self.test_summaries = []
# 传入卷积层参数的函数
def add_conv(self, *, patch_size, in_depth, out_depth, activation='relu', pooling=False, name):
"""
This function does not define operations in the graph, but only store config in self.conv_layer_config
"""
"""
卷积层的参数有:卷积核的大小、输入的深度、输出的深度(也就是卷积核的个数同时也是feature map的个数)
激活函数的选择、是否pooling、卷积层的名字
"""
self.conv_config.append({
'patch_size': patch_size,
'in_depth': in_depth,
'out_depth': out_depth,
'activation': activation,
'pooling': pooling,
'name': name
})
"""
值得注意的是,上面的conv_config中存储的是卷积层的物理结构的配置,并没有存储卷积核的权重矩阵以及bias。
故卷积核的权重矩阵及bias用conv_weghts和conv_biases来存储
"""
with tf.name_scope(name):
weights = tf.Variable(
tf.truncated_normal([patch_size, patch_size, in_depth, out_depth], stddev=0.1), name=name + '_weights')
biases = tf.Variable(tf.constant(0.1, shape=[out_depth]), name=name + '_biases')
self.conv_weights.append(weights)
self.conv_biases.append(biases)
# 传入全连接层参数的函数
def add_fc(self, *, in_num_nodes, out_num_nodes, activation='relu', name):
"""
add fc layer config to slef.fc_layer_config
"""
"""
全连接层的参数有:输入的维度(也就是上一层输出的维度)、输出的维度、
激活函数的选择、还有名字
"""
self.fc_config.append({
'in_num_nodes': in_num_nodes,
'out_num_nodes': out_num_nodes,
'activation': activation,
'name': name
})
with tf.name_scope(name):
weights = tf.Variable(tf.truncated_normal([in_num_nodes, out_num_nodes], stddev=0.1))
biases = tf.Variable(tf.constant(0.1, shape=[out_num_nodes]))
self.fc_weights.append(weights)
self.fc_biases.append(biases)
self.train_summaries.append(tf.summary.histogram(str(len(self.fc_weights)) + '_weights', weights))
self.train_summaries.append(tf.summary.histogram(str(len(self.fc_biases)) + '_biases', biases))
# should make the definition as an exposed API, instead of implemented in the function
def define_inputs(self, *, train_samples_shape, train_labels_shape, test_samples_shape):
# 这里只是定义图谱中的各种变量
with tf.name_scope('inputs'):
self.tf_train_samples = tf.placeholder(tf.float32, shape=train_samples_shape, name='tf_train_samples')
self.tf_train_labels = tf.placeholder(tf.float32, shape=train_labels_shape, name='tf_train_labels')
self.tf_test_samples = tf.placeholder(tf.float32, shape=test_samples_shape, name='tf_test_samples')
def define_model(self):
"""
定义我的的计算图谱
"""
def model(data_flow, train=True):
"""
@data: original inputs
@return: logits
"""
# 定义卷积层的运算
for i, (weights, biases, config) in enumerate(zip(self.conv_weights, self.conv_biases, self.conv_config)):
with tf.name_scope(config['name'] + '_model'):
with tf.name_scope('convolution'):
# default 1,1,1,1 stride and SAME padding
data_flow = tf.nn.conv2d(data_flow, filter=weights, strides=[1, 1, 1, 1], padding='SAME')
data_flow = data_flow + biases
if not train:
self.visualize_filter_map(data_flow, how_many=config['out_depth'],
display_size=32 // (i // 2 + 1), name=config['name'] + '_conv')
if config['activation'] == 'relu':
data_flow = tf.nn.relu(data_flow)
if not train:
self.visualize_filter_map(data_flow, how_many=config['out_depth'],
display_size=32 // (i // 2 + 1), name=config['name'] + '_relu')
else:
raise Exception('Activation Func can only be Relu right now. You passed', config['activation'])
if config['pooling']:
data_flow = tf.nn.max_pool(
data_flow,
ksize=[1, self.pooling_scale, self.pooling_scale, 1],
strides=[1, self.pooling_stride, self.pooling_stride, 1],
padding='SAME')
if not train:
self.visualize_filter_map(data_flow, how_many=config['out_depth'],
display_size=32 // (i // 2 + 1) // 2,
name=config['name'] + '_pooling')
# 定义全连接层的运算
for i, (weights, biases, config) in enumerate(zip(self.fc_weights, self.fc_biases, self.fc_config)):
if i == 0: # 如果是全连接层1
shape = data_flow.get_shape().as_list()
data_flow = tf.reshape(data_flow, [shape[0], shape[1] * shape[2] * shape[3]])
with tf.name_scope(config['name'] + 'model'):
data_flow = tf.matmul(data_flow, weights) + biases
if config['activation'] == 'relu':
data_flow = tf.nn.relu(data_flow)
elif config['activation'] is None:
pass
else:
raise Exception('Activation Func can only be Relu or None right now. You passed',
config['activation'])
return data_flow
# Training computation.
logits = model(self.tf_train_samples)
with tf.name_scope('loss'):
self.loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=self.tf_train_labels))
self.train_summaries.append(tf.summary.scalar('Loss', self.loss))
# Optimizer.
with tf.name_scope('optimizer'):
self.optimizer = tf.train.GradientDescentOptimizer(0.0001).minimize(self.loss)
# Predictions for the training, validation, and test data.
with tf.name_scope('train'):
self.train_prediction = tf.nn.softmax(logits, name='train_prediction')
with tf.name_scope('test'):
self.test_prediction = tf.nn.softmax(model(self.tf_test_samples, train=False), name='test_prediction')
# 注意这里不能随便替换为merge_all
self.merged_train_summary = tf.summary.merge(self.train_summaries)
self.merged_test_summary = tf.summary.merge(self.test_summaries)
def run(self, data_iterator, train_samples, train_labels, test_samples, test_labels):
"""
用到Session
:data_iterator: a function that yields chuck of data
"""
# private function
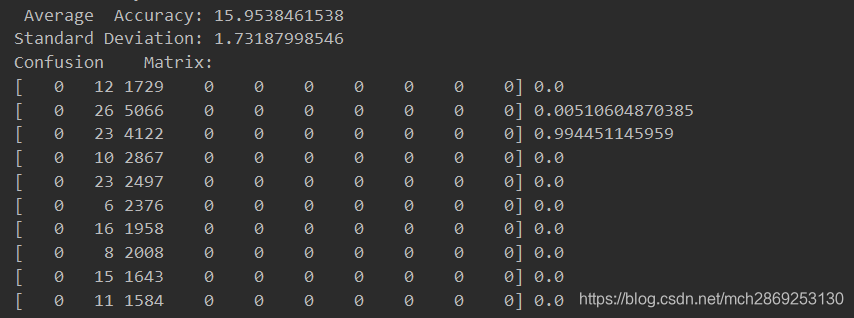
def print_confusion_matrix(confusionMatrix):
print('Confusion Matrix:')
for i, line in enumerate(confusionMatrix):
print(line, line[i] / np.sum(line))
a = 0
for i, column in enumerate(np.transpose(confusionMatrix, (1, 0))):
a += (column[i] / np.sum(column)) * (np.sum(column) / 26000)
print(column[i] / np.sum(column), )
print('\n', np.sum(confusionMatrix), a)
self.writer = tf.summary.FileWriter('./board', tf.get_default_graph())
with tf.Session(graph=tf.get_default_graph()) as session:
tf.initialize_all_variables().run()
# 训练
print('Start Training')
# batch 1000
for i, samples, labels in data_iterator(train_samples, train_labels, self.train_batch_size):
_, l, predictions, summary = session.run(
[self.optimizer, self.loss, self.train_prediction, self.merged_train_summary],
feed_dict={self.tf_train_samples: samples, self.tf_train_labels: labels}
)
self.writer.add_summary(summary, i)
# labels is True Labels
accuracy, _ = self.accuracy(predictions, labels)
if i % 50 == 0:
print('Minibatch loss at step %d: %f' % (i, l))
print('Minibatch accuracy: %.1f%%' % accuracy)
#
# 测试
accuracies = []
confusionMatrices = []
for i, samples, labels in data_iterator(test_samples, test_labels, self.test_batch_size):
print('samples shape', samples.shape)
result, summary = session.run(
[self.test_prediction, self.merged_test_summary],
feed_dict={self.tf_test_samples: samples}
)
# result = self.test_prediction.eval(feed_dict={self.tf_test_samples: samples})
self.writer.add_summary(summary, i)
accuracy, cm = self.accuracy(result, labels, need_confusion_matrix=True)
accuracies.append(accuracy)
confusionMatrices.append(cm)
print('Test Accuracy: %.1f%%' % accuracy)
print(' Average Accuracy:', np.average(accuracies))
print('Standard Deviation:', np.std(accuracies))
print_confusion_matrix(np.add.reduce(confusionMatrices))
#
def accuracy(self, predictions, labels, need_confusion_matrix=False):
"""
计算预测的正确率与召回率
@return: accuracy and confusionMatrix as a tuple
"""
_predictions = np.argmax(predictions, 1)
_labels = np.argmax(labels, 1)
cm = confusion_matrix(_labels, _predictions) if need_confusion_matrix else None
# == is overloaded for numpy array
accuracy = (100.0 * np.sum(_predictions == _labels) / predictions.shape[0])
return accuracy, cm
def visualize_filter_map(self, tensor, *, how_many, display_size, name):
print(tensor.get_shape)
filter_map = tensor[-1]
print(filter_map.get_shape())
filter_map = tf.transpose(filter_map, perm=[2, 0, 1])
print(filter_map.get_shape())
filter_map = tf.reshape(filter_map, (how_many, display_size, display_size, 1))
print(how_many)
self.test_summaries.append(tf.summary.image(name, tensor=filter_map, max_outputs=how_many))
main.py 中调用dp.py中的网络,并传入参数
if __name__ == '__main__':
import load
from dp import Network
train_samples, train_labels = load._train_samples, load._train_labels
test_samples, test_labels = load._test_samples, load._test_labels
print('Training set', train_samples.shape, train_labels.shape)
print(' Test set', test_samples.shape, test_labels.shape)
image_size = load.image_size
num_labels = load.num_labels
num_channels = load.num_channels
def get_chunk(samples, labels, chunk_size):
"""
Iterator/Generator: get a batch of data
这个函数是一个迭代器/生成器,用于每一次只得到 chunk_size 这么多的数据
用于 for loop, just like range() function
"""
if len(samples) != len(labels):
raise Exception('Length of samples and labels must equal')
stepStart = 0 # initial step
i = 0
while stepStart < len(samples):
stepEnd = stepStart + chunk_size
if stepEnd < len(samples):
yield i, samples[stepStart:stepEnd], labels[stepStart:stepEnd]
i += 1
stepStart = stepEnd
# 定义图
net = Network(train_batch_size=64, test_batch_size=500, pooling_scale=2)
# 定义图的输入
net.define_inputs(
train_samples_shape=(64, image_size, image_size, num_channels),
train_labels_shape=(64, num_labels),
test_samples_shape=(500, image_size, image_size, num_channels)
)
# 定义卷积层的网络结构, patch_size就是kernel_size,out_depth就是kernel的个数,也是feature map的个数
net.add_conv(patch_size=3, in_depth=num_channels, out_depth=16, activation='relu', pooling=False, name='conv1')
net.add_conv(patch_size=3, in_depth=16, out_depth=16, activation='relu', pooling=True, name='conv2')
net.add_conv(patch_size=3, in_depth=16, out_depth=16, activation='relu', pooling=False, name='conv3')
net.add_conv(patch_size=3, in_depth=16, out_depth=16, activation='relu', pooling=True, name='conv4')
# 定义全连接层的网络结构
# 4 = 两次 pooling, 每一次缩小为 1/2
# 16 = conv4的out_depth
net.add_fc(in_num_nodes=(image_size // 4) * (image_size // 4) * 16, out_num_nodes=16, activation='relu', name='fc1')
net.add_fc(in_num_nodes=16, out_num_nodes=10, activation=None, name='fc2')
net.define_model()
net.run(get_chunk, train_samples, train_labels, test_samples, test_labels)
else:
raise Exception('main.py: Should Not Be Imported!!! Must Run by "python main.py"')
正确率有了一点点提升

















 5488
5488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









