



数据库中数据量过多,表太大的时候,不仅可以做分库分表,还可以做表分区,分区和分表类似,都是按照一定的规则将一张大表进行分解。
听上去好像也差不多,不就是将表拆分吗?那具体有什么差别呢?
分区和分表的区别
主要是分区和分表后数据的数据存储方式有变化。
1.分区
在Innodb中(8.0之前),表存储主要依赖两个文件,分别是.frm文件和.ibd文件。.frm文件用于存储表结构定义信息,而.ibd文件则用于存储表数据。
假如我们有一张users表,想要对他进行分区和分表,区别如下:
MySQL InnoDB存储引擎在分区表时,会将每一个分区分别存放在一个单独的 .ibd 文件中,所有的 .ibd 文件组合构成表的物理结构,即 Table Space。
对于上面分区的 users表,存储时会在 MySQL 的 data 目录下创建一个用户名+表名+分区名.ibd 的文件(如:users_p1.ibd),用来存储 users 表中第一个分区的数据,同样会有 users_p2.ibd 和 users_p3.ibd 来存储第二和第三个分区的数据:
users_p1.ibd
users_p2.ibd
users_p3.ibd
users_p4.ibd
users.frm
2、分表
MySQL InnoDB存储引擎在分表时,会将每一个分表分别存放在一个单独的 .frm 文件中,所有的 .frm 文件组合构成表的逻辑结构,即 Table Definition。
对于上面分表的users表,存储时会在 MySQL 的data目录下创建后缀名为“users_1.frm”的表格文件,存储 users 表中第一个分表的数据,同样会有 users_2.frm 和 users_3.frm 来存储第二和第三个分表的数据:
users_1.ibd
users_1.frm
users_2.ibd
users_2.frm
users_3.ibd
users_3.frm
users_4.ibd
users_4.frm
在做了分区后,表面是还是只有一张表,只不过数据保存在不同的位置上了(同一个.frm文件),在做数据读取的时候操作的表名还是users表,数据库会自己去组织各个分区的数据。
而在做了分表之后,不管是表面上,还是实际上,都已经是不同的表了(多个.frm文件),数据库操作的时候,需要去指定具体的表名。
一般来说,数据量变大时,我们应该先考虑分区,分区搞不定再考虑分表。
因为分表可以在分区的基础上,进一步减少查询时的系统开销。因为分表后,单表数据量小,页缓存率更高,I/O读写性能更优,另外分表也能降低了锁带来的阻塞,也可以提高事务处理效率。还有就是小的表可以提升备份和恢复的速度、并且具有更好的横向扩展性。
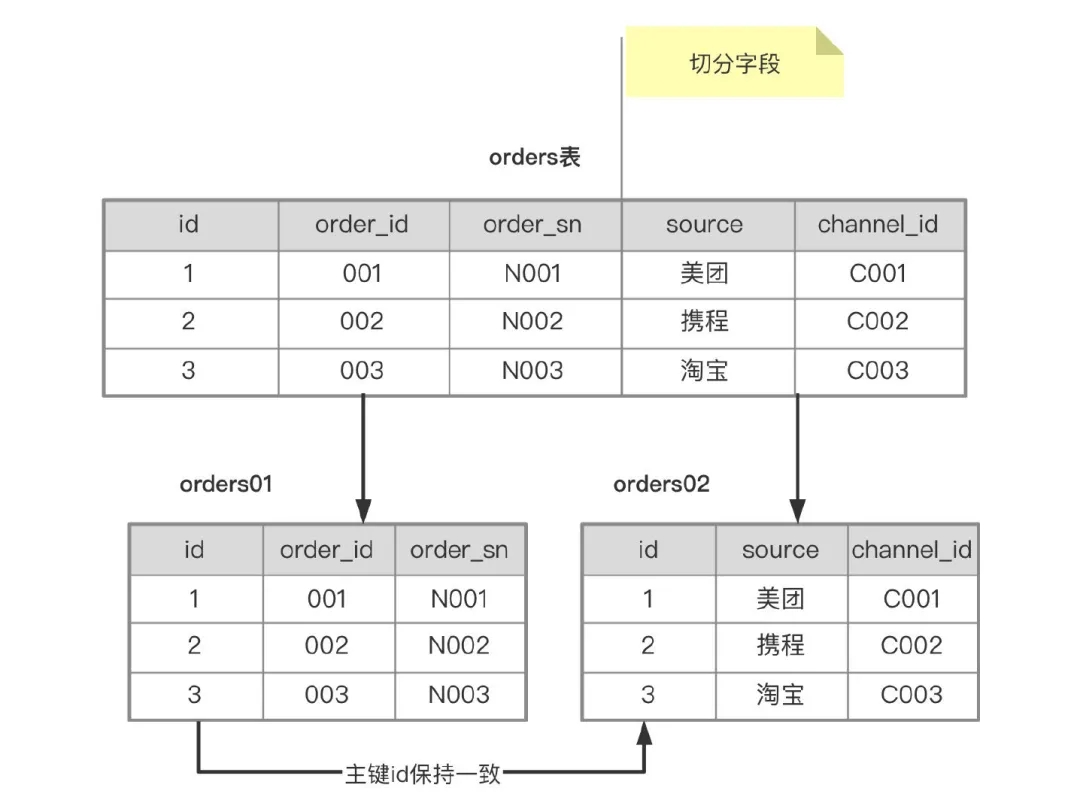
垂直分表
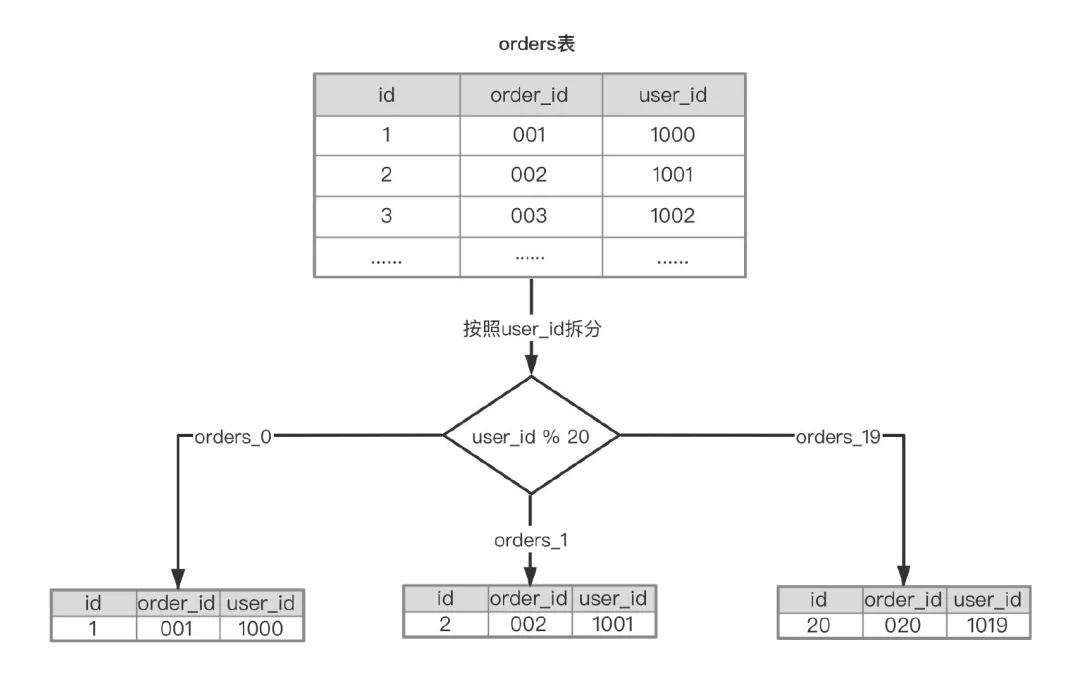
水平分表:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









