




概述

Weismann数据集。来源
本文介绍了一种用于人类动作分类与识别的深度学习序列模型。
该深度学习模型通过从每个视频的特征中提取时空特征来工作,随后使用CNN模型将这些输入作为视频的空间特征图,并输出为特征序列。这些序列会按时间顺序输入到模型的MLP中,最终将视频分类为7种不同类别:弯曲(bend)、开合跳(jack)、跳跃(jump)、立定跳远(pjump)、行走(walk)、挥手1(wave1)和挥手2(wave2)。
模型的应用场景
- 医疗中心的人体动作识别,用于监测患者的活动状态
- 人体跌倒检测
- 飞机上乘客动作识别
- 监狱中人体动作识别,用于检测囚犯的可疑行为
实施步骤
这项工作的实施过程较长但操作简单。首先需要构建或重组数据集,我们拥有记录人物执行特定动作的视频,由于要使用可处理图像的CNN,因此首先需要提取视频帧并将其保存在以动作名称命名的文件夹中。
步骤1:安装依赖项并整理数据集
import pandas as pd
import joblib
import os
import numpy as np
from tqdm import tqdm
from sklearn.preprocessing import LabelBinarizer
# 获取所有图像文件夹路径
all_paths = os.listdir(r'C:/Users/abdul/Desktop/Research/work/data')
folder_paths = [x for x in all_paths if os.path.isdir('C:/Users/abdul/Desktop/Research/work/data/' + x)]
print(f"文件夹路径: {folder_paths}")
print(f"文件夹数量: {len(folder_paths)}")
输出:
文件夹路径: ['bend', 'jack', 'jump', 'pjump', 'walk', 'wave1', 'wave2']
文件夹数量: 7
步骤2:创建标签并加载数据集
# 我们将为以下标签创建数据
# 如需创建更多数据,可向列表中添加更多标签
create_labels = ['bend', 'jack', 'jump', 'pjump', 'walk', 'wave1', 'wave2']
# 创建DataFrame
data = pd.DataFrame()
image_formats = ['jpg', 'JPG', 'PNG', 'png'] # 仅处理这些格式的图像
labels = []
counter = 0
for i, folder_path in tqdm(enumerate(folder_paths), total=len(folder_paths)):
if folder_path not in create_labels:
continue
image_paths = os.listdir('C:/Users/abdul/Desktop/Research/work/data/'+folder_path)
label = folder_path
# 将图像路径保存到DataFrame中
for image_path in image_paths:
if image_path.split('.')[-1] in image_formats:
data.loc[counter, 'image_path'] = f"C:/Users/abdul/Desktop/Research/work/mhamad syrian/ziad/data/{folder_path}/{image_path}"
labels.append(label)
counter += 1
labels = np.array(labels)
# 对标签进行独热编码
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
if len(labels[0]) == 1:
for i in range(len(labels)):
index = labels[i]
data.loc[i, 'target'] = int(index)
elif len(labels[0]) > 1:
for i in range(len(labels)):
index = np.argmax(labels[i])
data.loc[i, 'target'] = int(index)
# 打乱数据集
data = data.sample(frac=1).reset_index(drop=True)
print(f"标签或类别的数量: {len(lb.classes_)}")
print(f"第一个独热编码标签: {labels[0]}")
print(f"第一个独热编码标签对应的类别: {lb.classes_[0]}")
print(f"总实例数: {len(data)}")
# 保存为CSV文件
data.to_csv('C:/Users/abdul/Desktop/Research/work/data.csv', index=False)
# 序列化二值化标签
print('正在保存二值化标签为序列化文件')
joblib.dump(lb, 'C:/Users/abdul/Desktop/Research/work/lb.pkl')
print(data.head(5))
输出:
标签或类别的数量: 7
第一个独热编码标签: [1 0 0 0 0 0 0]
第一个独热编码标签对应的类别: bend
总实例数: 3390
正在保存二值化标签为序列化文件
image_path target
0 C:/Users/abdul/Desktop/Research/work/mhamad sy... 6.0
1 C:/Users/abdul/Desktop/Research/work/mhamad sy... 1.0
2 C:/Users/abdul/Desktop/Research/work/mhamad sy... 4.0
3 C:/Users/abdul/Desktop/Research/work/mhamad sy... 0.0
4 C:/Users/abdul/Desktop/Research/work/mhamad sy... 5.0
步骤3:构建CNN模型
import torch
import torch.nn as nn
import torch.nn.functional as F
import joblib
# 加载二值化标签文件
lb = joblib.load('C:/Users/abdul/Desktop/Research/work/mhamad syrian/ziad/lb.pkl')
class CustomCNN(nn.Module):
def __init__(self):
super(CustomCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.conv2 = nn.Conv2d(16, 32, 5)
self.conv3 = nn.Conv2d(32, 64, 3)
self.conv4 = nn.Conv2d(64, 128, 5)
self.fc1 = nn.Linear(128, 256)
self.fc2 = nn.Linear(256, len(lb.classes_))
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
bs, _, _, _ = x.shape
x = F.adaptive_avg_pool2d(x, 1).reshape(bs, -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
步骤4:加载CSV文件并获取图像和标签
# 读取data.csv文件并获取图像路径和标签
df = pd.read_csv('C:/Users/abdul/Desktop/Research/work/mhamad syrian/ziad/data.csv')
X = df.image_path.values # 图像路径
y = df.target.values # 目标标签
(xtrain, xtest, ytrain, ytest) = train_test_split(X, y,
test_size=0.10, random_state=42)
print(f"训练实例数量: {len(xtrain)}")
print(f"验证实例数量: {len(xtest)}")
输出:
训练实例数量: 3051
验证实例数量: 339
# 自定义数据集类
class ImageDataset(Dataset):
def __init__(self, images, labels=None, tfms=None):
self.X = images
self.y = labels
# 应用数据增强
if tfms == 0: # 验证集
self.aug = albumentations.Compose([
albumentations.Resize(224, 224, always_apply=True),
])
else: # 训练集
self.aug = albumentations.Compose([
albumentations.Resize(224, 224, always_apply=True),
albumentations.HorizontalFlip(p=0.5),
albumentations.ShiftScaleRotate(
shift_limit=0.3,
scale_limit=0.3,
rotate_limit=15,
p=0.5
),
])
def __len__(self):
return len(self.X)
def __getitem__(self, i):
image = Image.open(self.X[i])
image = image.convert('RGB')
image = self.aug(image=np.array(image))['image']
image = np.transpose(image, (2, 0, 1)).astype(np.float32)
label = self.y[i]
return (torch.tensor(image, dtype=torch.float), torch.tensor(label, dtype=torch.long))
train_data = ImageDataset(xtrain, ytrain, tfms=1)
test_data = ImageDataset(xtest, ytest, tfms=0)
# 数据加载器
trainloader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
testloader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
步骤5:准备CNN进行训练
import torch
import argparse
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import joblib
import albumentations
import torch.optim as optim
import os
import matplotlib
import matplotlib.pyplot as plt
import time
import pandas as pd
matplotlib.style.use('ggplot')
from imutils import paths
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, Dataset
from tqdm import tqdm
from PIL import Image
# 学习参数
lr = 1e-3
epochs = 100
batch_size = 64
device = 'cuda:0'
print(f"计算设备: {device}\n")
model = CustomCNN().to(device)
print(model)
# 总参数和可训练参数统计
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} 总参数")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} 可训练参数")
输出:
CustomCNN(
(conv1): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(64, 128, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=128, out_features=256, bias=True)
(fc2): Linear(in_features=256, out_features=7, bias=True)
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
272,295 总参数
272,295 可训练参数
步骤6:优化器、训练和验证函数
# 优化器
optimizer = optim.Adam(model.parameters(), lr=lr)
# 损失函数
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min',
patience=5,
factor=0.5,
min_lr=1e-6,
verbose=True
)
# 训练函数
def fit(model, train_dataloader):
print('训练中')
model.train()
train_running_loss = 0.0
train_running_correct = 0
for i, data in tqdm(enumerate(train_dataloader), total=int(len(train_data)/train_dataloader.batch_size)):
data, target = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, target)
train_running_loss += loss.item()
_, preds = torch.max(outputs.data, 1)
train_running_correct += (preds == target).sum().item()
loss.backward()
optimizer.step()
train_loss = train_running_loss / len(train_dataloader.dataset)
train_accuracy = 100. * train_running_correct / len(train_dataloader.dataset)
print(f"训练损失: {train_loss:.4f}, 训练准确率: {train_accuracy:.2f}%")
return train_loss, train_accuracy
# 验证函数
def validate(model, test_dataloader):
print('验证中')
model.eval()
val_running_loss = 0.0
val_running_correct = 0
with torch.no_grad():
for i, data in tqdm(enumerate(test_dataloader), total=int(len(test_data)/test_dataloader.batch_size)):
data, target = data[0].to(device), data[1].to(device)
outputs = model(data)
loss = criterion(outputs, target)
val_running_loss += loss.item()
_, preds = torch.max(outputs.data, 1)
val_running_correct += (preds == target).sum().item()
val_loss = val_running_loss / len(test_dataloader.dataset)
val_accuracy = 100. * val_running_correct / len(test_dataloader.dataset)
print(f'验证损失: {val_loss:.4f}, 验证准确率: {val_accuracy:.2f}%')
return val_loss, val_accuracy
步骤7:开始训练
train_loss , train_accuracy = [], []
val_loss , val_accuracy = [], []
start = time.time()
for epoch in range(epochs):
print(f"Epoch {epoch+1}/{epochs}")
train_epoch_loss, train_epoch_accuracy = fit(model, trainloader)
val_epoch_loss, val_epoch_accuracy = validate(model, testloader)
train_loss.append(train_epoch_loss)
train_accuracy.append(train_epoch_accuracy)
val_loss.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
scheduler.step(val_epoch_loss)
end = time.time()
print(f"总训练时间: {(end-start)/60:.3f} 分钟")
输出:
Epoch 1/100
训练中
48it [00:07, 6.55it/s]
训练损失: 0.0308, 训练准确率: 19.70%
验证中
6it [00:00, 9.27it/s]
验证损失: 0.0335, 验证准确率: 27.43%
Epoch 2/100
训练中
48it [00:07, 6.63it/s]
训练损失: 0.0295, 训练准确率: 24.39%
验证中
6it [00:00, 9.10it/s]
验证损失: 0.0323, 验证准确率: 27.43%
...(中间训练过程省略)...
Epoch 100/100
训练中
48it [00:08, 5.74it/s]
训练损失: 0.0009, 训练准确率: 97.94%
验证中
6it [00:00, 8.32it/s]
验证损失: 0.0004, 验证准确率: 99.12%
总训练时间: 15.359 分钟
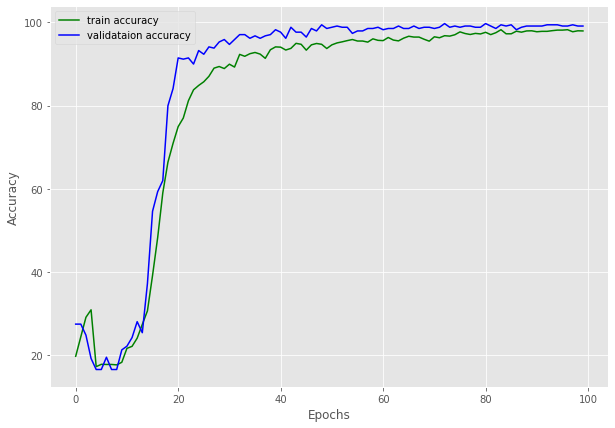
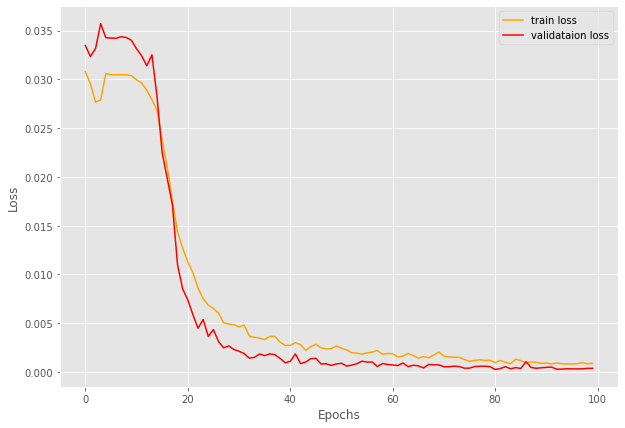
步骤8:绘制训练结果
# 准确率曲线图
plt.figure(figsize=(10, 7))
plt.plot(train_accuracy, color='green', label='训练准确率')
plt.plot(val_accuracy, color='blue', label='验证准确率')
plt.xlabel('Epochs')
plt.ylabel('准确率 (%)')
plt.legend()
plt.savefig(r'C:/Users/abdul/Desktop/Research/work/mhamad syrian/ziad/accuracy.png')
plt.show()
# 损失曲线图
plt.figure(figsize=(10, 7))
plt.plot(train_loss, color='orange', label='训练损失')
plt.plot(val_loss, color='red', label='验证损失')
plt.xlabel('Epochs')
plt.ylabel('损失值')
plt.legend()
plt.savefig(r'C:/Users/abdul/Desktop/Research/work/mhamad syrian/ziad/loss.png')
plt.show()
# 将模型序列化到磁盘
print('正在保存模型...')
torch.save(model.state_dict(), 'model.pth') # 补充文件扩展名
print('训练完成')
输出:
正在保存模型...
训练完成
步骤9:模型评估和真实视频测试
import torch
import numpy as np
import argparse
import joblib
import cv2
import torch.nn as nn
import torch.nn.functional as F
import time
import albumentations
from torchvision.transforms import transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
aug = albumentations.Compose([
albumentations.Resize(224, 224),
])
import cv2
cap = cv2.VideoCapture(r'C:/Users/abdul/De...') # 补充完整路径
备注
原文地址:https://medium.com/gitconnected/human-action-detection-using-cnn-4e292ca8ba5b


















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











