




一、理论介绍
今天我们来实验 Deployment 控制器(也叫工作负载)。官网描述如下:

1、是什么?
Deployment 是一个非常重要的资源对象,它为 Pod 和 ReplicaSet 提供了声明式的更新能力,常用于管理无状态应用程序的部署和更新。
2、为什么需要?
为 Pod 和 ReplicaSet 提供了声明式的更新能力。
所谓声明式更新指的是用户只需描述期望的资源最终状态,比如定义 Deployment、Service 等资源的 YAML 文件,详细说明资源的属性、副本数量、使用的镜像等信息。Kubernetes 系统会自动对比当前资源的实际状态和期望状态,然后采取必要的操作,使实际状态逐渐趋近并最终达到期望状态。
声明式更新最常用的命令,就是 kubectl apply -f <directory>
3、缺点
无法部署有状态应用。


1.1、基础信息
kubectl explain deploy
# deploy 是 deployment 的缩写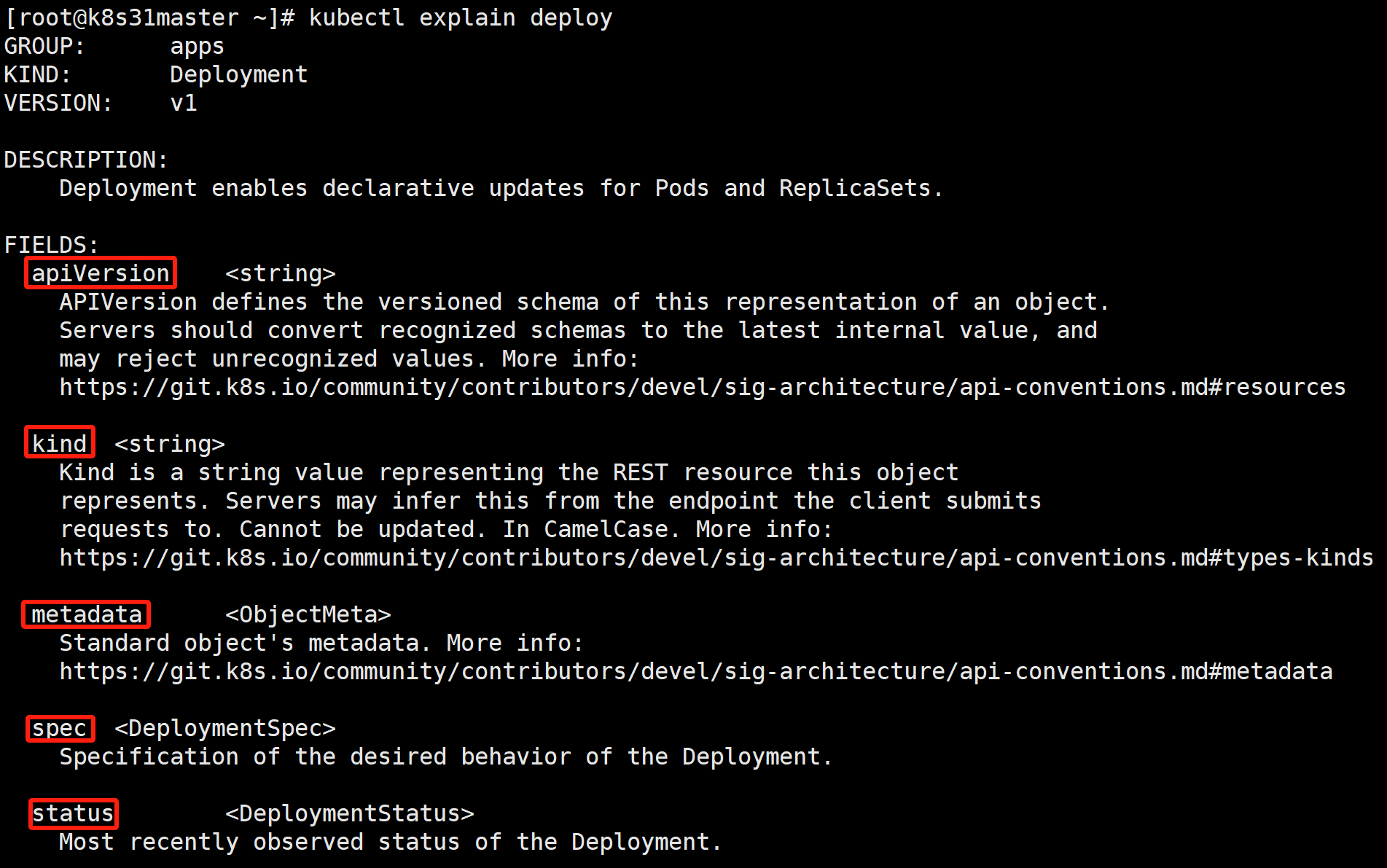
apiVersion:当前资源使用的 api 版本,是 GROUP/VERSION 的组合。
kind:资源类型,跟 KIND 保持一致。
metadata:元数据。定义资源名称、标签、注解等。
spec:规范、规约。定义 Pod 副本数、Pod 标签选择器、Pod 模板。
status:状态信息,只读,一般不会去修改。

1.2、DeplymentSpec 规约
kubectl explain deploy.spec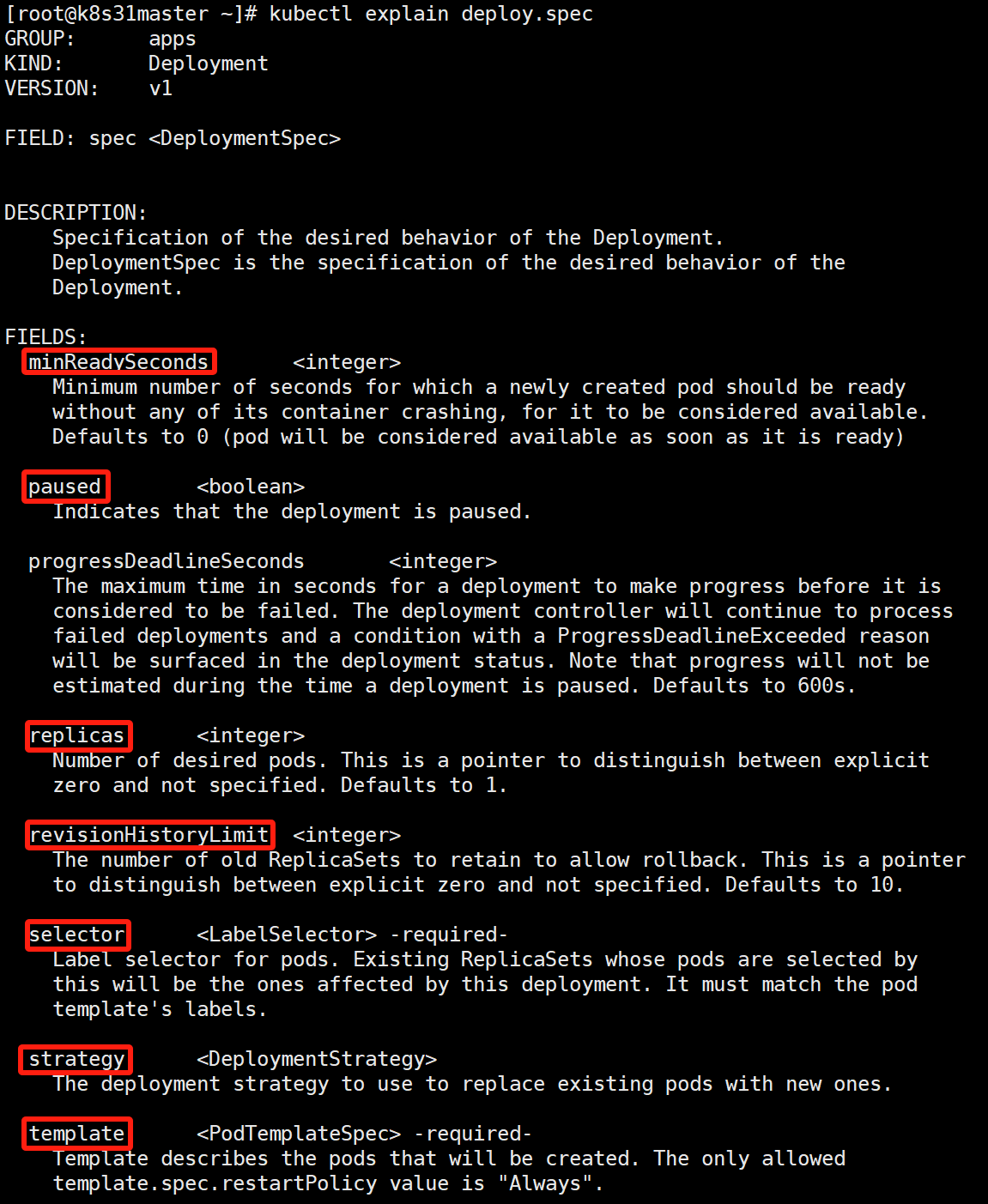
minReadySeconds:pod 变为就绪状态之后,还⾄少需要保持多少秒,才能被视为真正可⽤的,以继续后续部署过程。一般配合就绪探针使用。
paused:指示 deployment 是否被暂停。执行 kubectl rollout pause 后会被设置为 true。详细参考下文金丝雀发布。
replicas:Pod 副本数。
revisionHistoryLimit:保留的旧的 ReplicaSet 历史版本数。默认是 10。
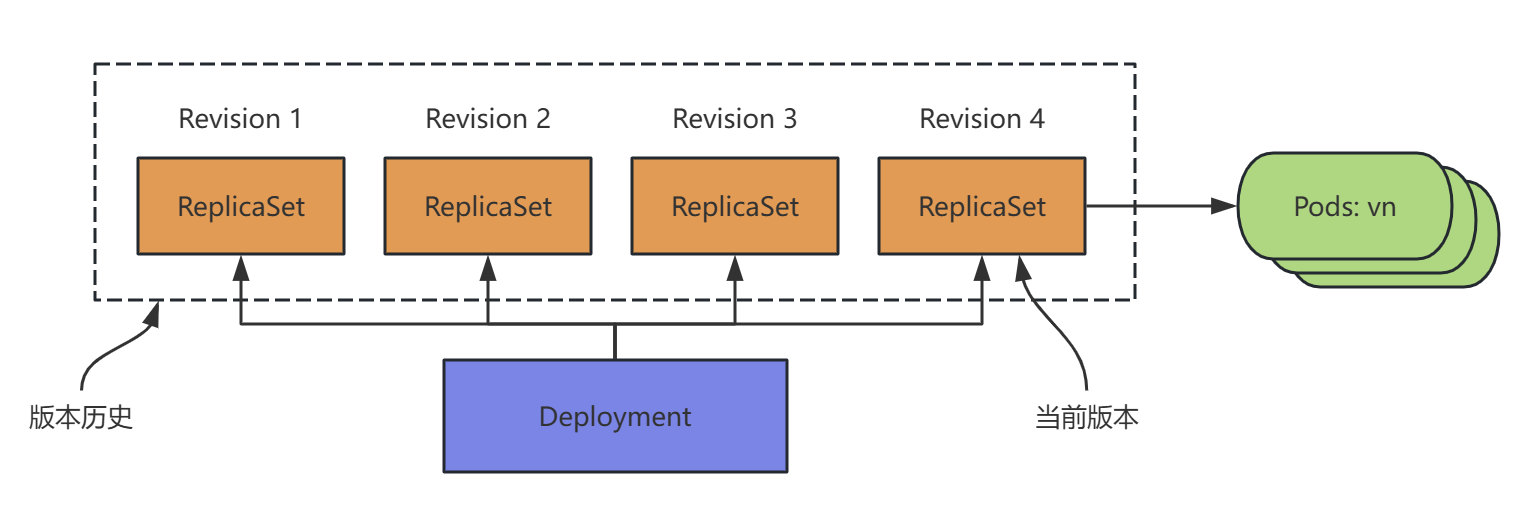
Deployment 通过创建 ReplicaSet 来间接管理 Pod。
Deployment 控制器是建立在 rs 之上的一个控制器,可以管理多个 rs,每次更新镜像版本,都会生成一个新的 rs,把旧的 rs 替换掉,多个 rs 同时存在,但是只有一个 rs 运行。
Deployment 通过回滚 ReplicaSet 来回滚镜像版本。
selector:标签选择器。用于查找它所要管理的 Pod。它必须跟 Pod 模板的标签(template.metadata.labels)相匹配。
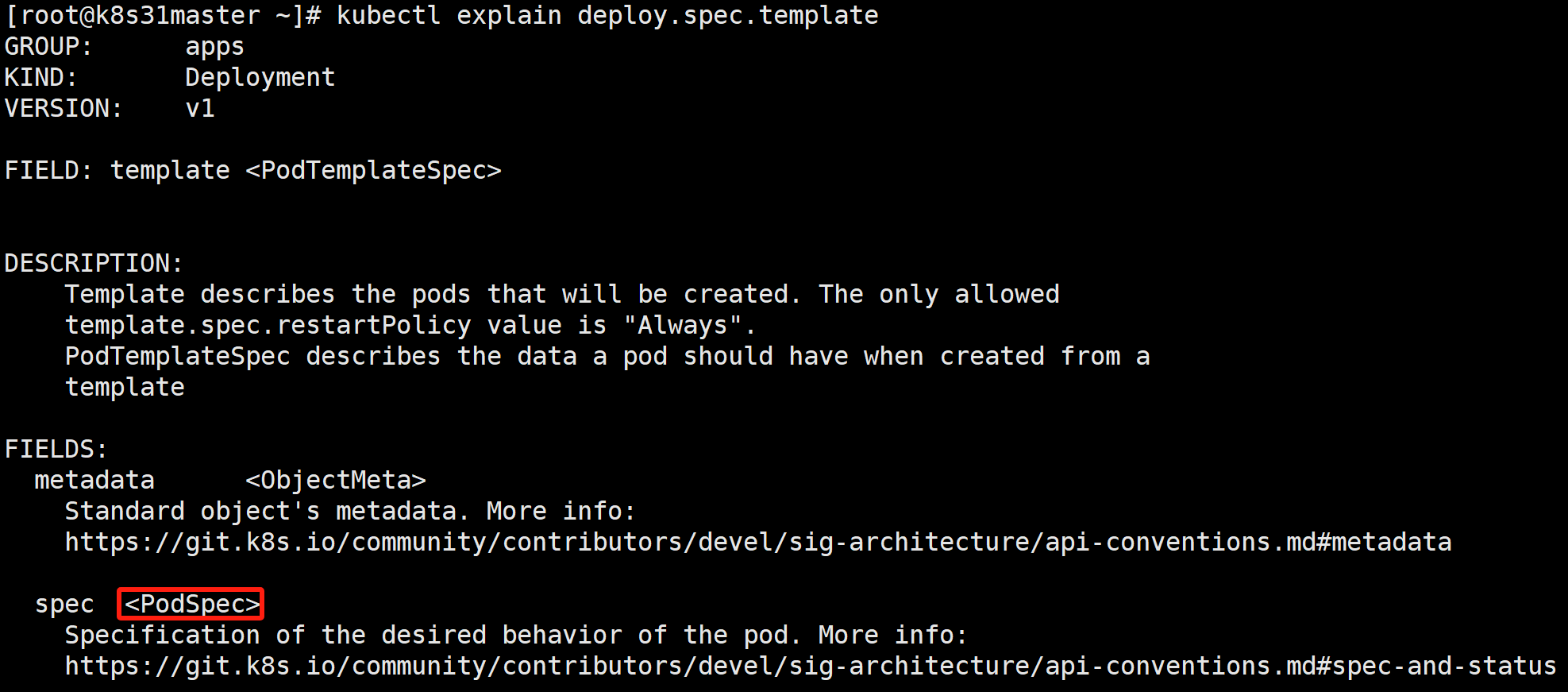
template:Pod 模板。定义 Pod 的模板。
可以看到 template 内部主要就是定义 Pod 的规范(PodSpec)它跟 Pod 定义里的规范(Pod.spec)是同一个类型。
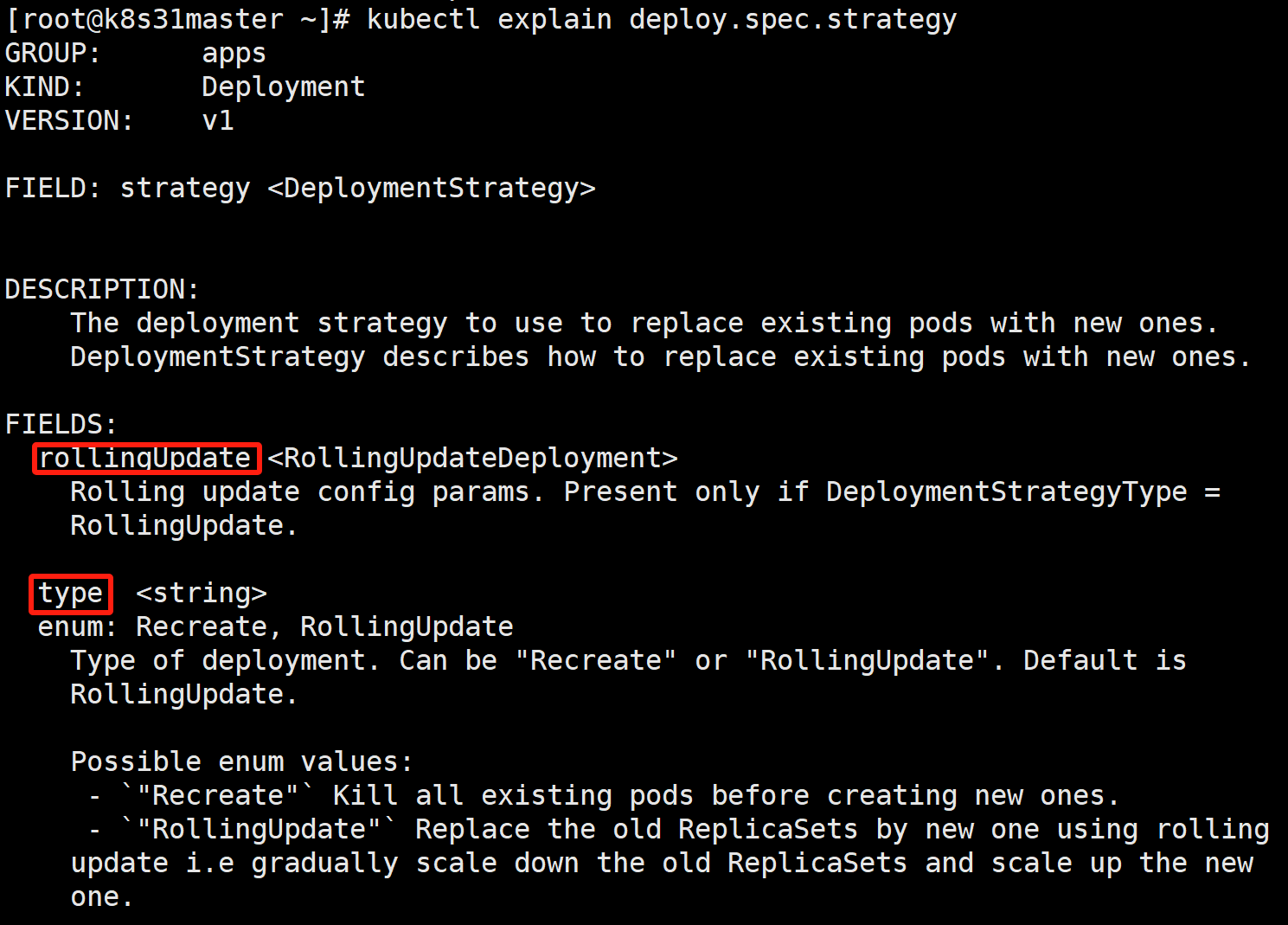
strategy:pod 更新策略。
- type:有两种取值 Recreate, RollingUpdate(默认)。
○ Recreate:重建式。删除所有已经存在的 Pod,再重新创建新的 Pod。
○ RollingUpdate:滚动更新式。以配置的速率来控制 pod 的增加和减少。
配置详见 rollingUpdate 字段。
- rollingUpdate:当 type=RollingUpdate 时,这个字段才起作用。
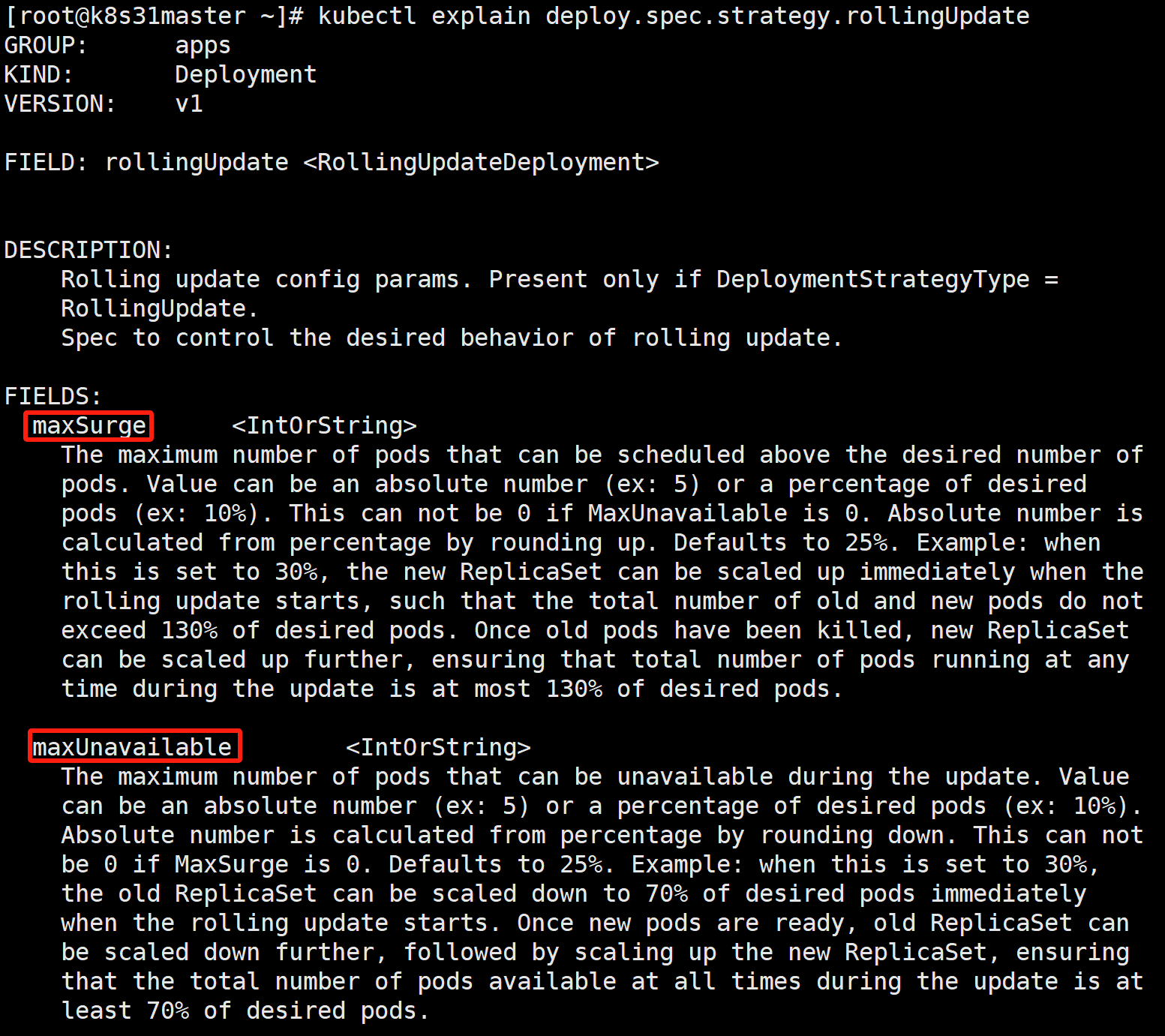
○ maxSurge:决定了在滚动升级期间,除了 replicas 配置的期望的副本数之外, 最多允许超出的 pod 实例的数量。它有两种取值方式,
第一种是绝对值,第二种是根据百分比。
默认值为 25%。
绝对值按百分比向上取整(rounding up)。
○ maxUnavailable:决定了在滚动升级期间,
最多允许几个不可用(相对于replicas)。它有两种取值方式,
第一种是绝对值,第二种是根据百分比。
默认值为 25%。
绝对值按百分比向下取整(rounding down)。
○ 就比如 replicas=5,maxSurge=25%,maxUnavailable=25%,那么在滚动升级 期间,最多可以超出 5*25%=1.25 --> 2个。最多的时候,可以有 5+2=7 个 pod 在运行(不保证全部可用)。
最多可以有 5*25%=1.25 --> 1个不可用。则最少有 5-1=4 个 pod 可 以提供服务。
1.3、滚动更新过程
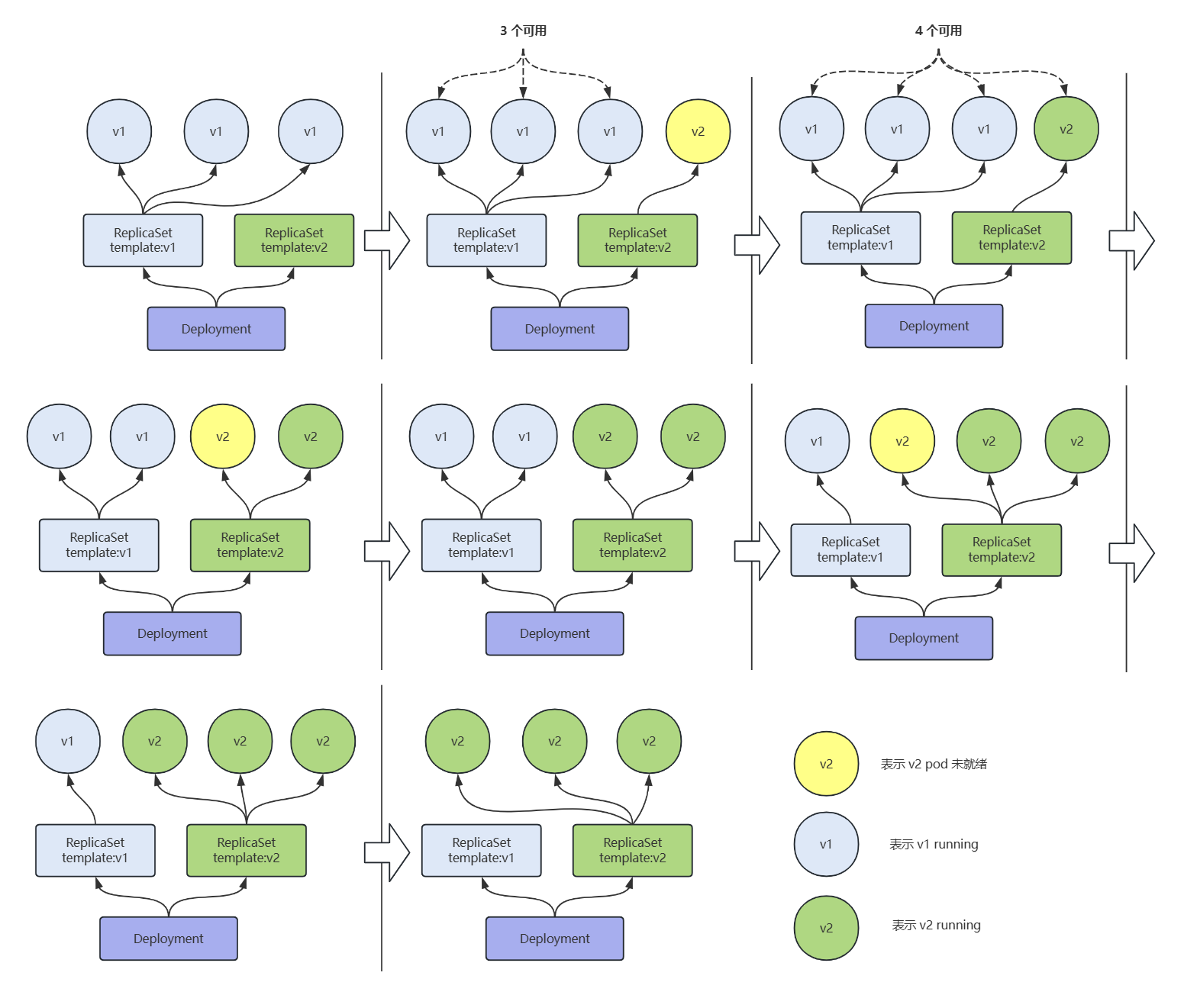
- 当 replicas=3,maxSurge=1,maxUnavailable=0 时,滚动更新的过程如下图。
rs1 控制三个 v1 pod,滚动更新开始后,先在 rs2 上新建一个 v2 pod,待该 pod 就绪后,在 rs1 上删除一个 v1 pod 的同时,又在 rs2 上新建一个 v2 pod。依次类推,直到全部都是由 rs2 控制。
- 当 replicas=3,maxSurge=1,maxUnavailable=1 时,滚动更新的过程如下图。
rs1 控制三个 v1 pod,滚动更新开始后,先在 rs2 上新建两个 v2 pod 并在 rs1 上删除一个 v1 pod,待该两个 v2 pod 就绪后,马上又在 rs1 上删除两个 v1 pod 并新建一个 v2 pod。待这最后一个 pod 就绪后,所有的 pod 就全部都是由 rs2 控制。
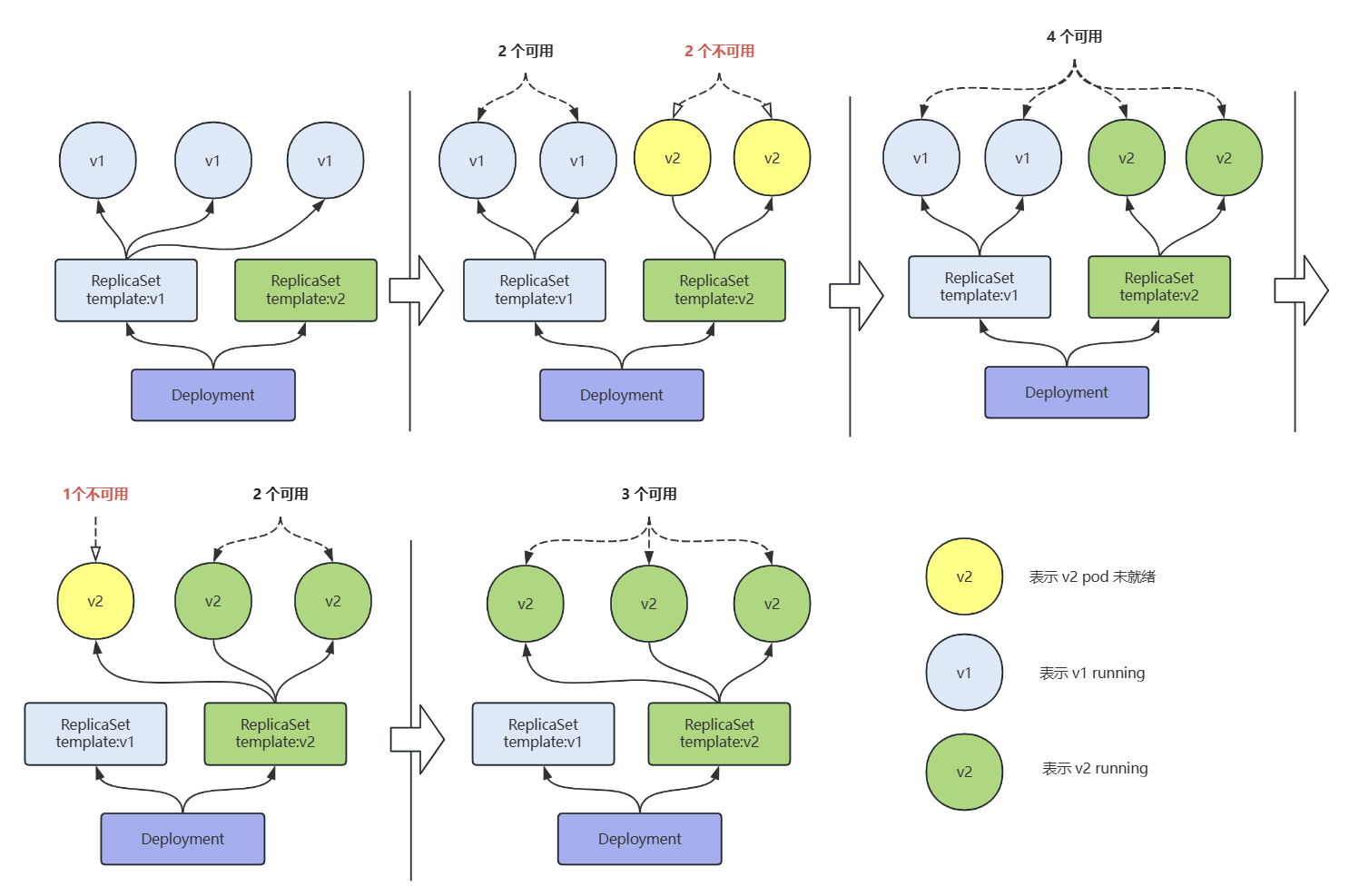
分析上图会发现,当 maxUnavailable=1,在更新过程中有一段时间会出现,可用的 pod 数,少于 replicas=3 期望的副本数(3-maxUnavailable=2)的情况,这在高可用系统中是不允许的。
比如,我有一个应用,它需要3个 pod 才能稳定提供服务。现在在更新的过程中,有一段时间,它有1个 pod 不可用,那势必造成另外两个 pod 流量短时间内激增。
- 最佳实践:maxUnavailable 设置为 非0 的话,在滚动升级期间会有可用 pod 数少于期望副本数的情况。从高可用的角度来讲,这个值最好设置为 0。
二、镜像准备
假设有如下三个节点的 K8S 集群:

k8s31master 是控制节点
k8s31node1、k8s31node2 是工作节点
容器运行时是 containerd
使用 springboot 打包两个镜像 hellok8s-1.0.jar.gz 和 hellok8s-2.0.jar.gz。
hellok8s:1.0
@RestController
public class HelloController {
@GetMapping("/sayHello")
@ResponseBody
public String sayHello() {
# 蓝
return "Hello,I am Blue";
}
}hellok8s:2.0
@RestController
public class HelloController {
@GetMapping("/sayHello")
@ResponseBody
public String sayHello() {
# 绿
return "Hello,I am Green";
}
}它们的区别仅在输出的问候信息不同,一个 Blue、一个 Green.
- 导入镜像
# node1 执行
[root@k8s31node1 ~]# ctr -n=k8s.io images import hellok8s-1.0.jar.gz
[root@k8s31node1 ~]# ctr -n=k8s.io images import hellok8s-2.0.jar.gz
# node2 执行
[root@k8s31node2 ~]# ctr -n=k8s.io images import hellok8s-1.0.jar.gz
[root@k8s31node2 ~]# ctr -n=k8s.io images import hellok8s-2.0.jar.gz

三、Deployment 自动化部署
- 资源文件编写
deploy-first.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
replicas: 2
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- name: hellok8s
image: hellok8s:1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
startupProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
readinessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
- replicas=2,期望副本数是 2。
- selector.matchLabels 要与 template.metadata.labels 相匹配。
- startupProbe 是启动探针、readinessProbe 是继续探针、livenessProbe 是存活探针。
○ httpGet 是探测模式,以 http 请求方式探测。
○ initialDelaySeconds 初始探测延迟时间,表示容器启动后多少秒开始探测。
○ periodSeconds 表示两次探测的时间间隔是多少秒。
- 执行并查看
kubectl apply -f deploy-first.yaml
kubectl get deploy[root@k8s31master deploy]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
my-deploy 0/2 2 0 3s
[root@k8s31master deploy]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
my-deploy 2/2 2 2 12s
- NAME :deployment 的名称。
- READY:显示 deployment 有多少副本数。它遵循 ready/desired的模式。
- UP-TO-DATE: 显示已更新到所需状态的副本数。
- AVAILABLE:已就绪的副本数。
- AGE :显示应用程序已运行的时间。
- 查看 ReplicaSet
kubectl get rs
创建 deploy 的时候也会创建一个 rs(ReplicaSet)。
- NAME: ReplicaSet 的名称。命名规范为 [deployment-name]-[pod-template-hash]。
- DESIRED:期望的副本数。
- CURRENT:当前正在运行的副本数。
- READY: 已就绪的副本数。
- AGE :显示应用程序已运行的时间。
kubectl describe rs my-deploy-569b69f85d
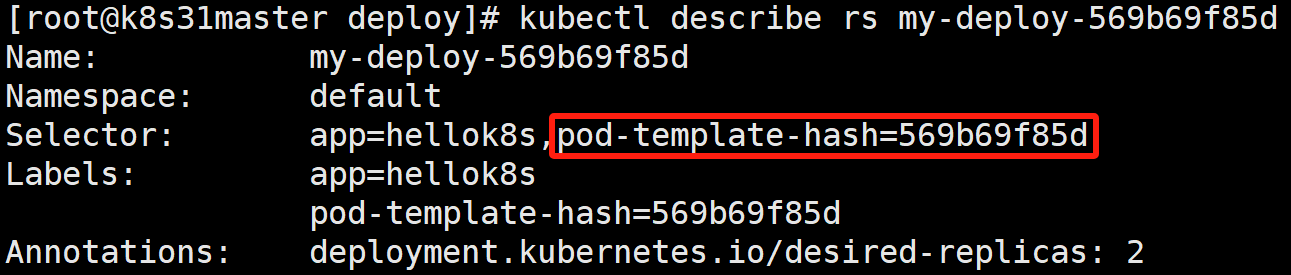
- 查看 Pod
kubectl get pod
四、Deployment 实现 Pod 的动态扩容
修改 deploy-first.yaml,replicas: 2 改为 3
replicas: 3
- 重新运行并查看
kubectl apply -f deploy-first.yaml
kubectl get pod -owide
可以看到 新创建了一个 pod,名称是 my-deploy-569b69f85d-hzfzg
- 访问接口

可以看到,三个 pod 的服务是一样的,返回的都是 Blue。
五、Deployment 实现 Pod 的滚动更新
修改 deploy-first.yaml,image: hellok8s:1.0 改为 2.0
image: hellok8s:2.0
- 重新运行并监控
kubectl apply -f deploy-first.yaml
kubectl get pod -owide -w| NAME | READY | STATUS | AGE | IP | NODE |
| my-deploy-569b69f85d-cw7wt | 1/1 | Running | 52m | 10.244.9.3 | k8s31node2 |
| my-deploy-569b69f85d-hzfzg | 1/1 | Running | 12m | 10.244.165.29 | k8s31node1 |
| my-deploy-569b69f85d-qrm5p | 1/1 | Running | 52m | 10.244.165.28 | k8s31node1 |
| my-deploy-7cf64887cf-kbjwg | 0/1 | Pending | 0s | <none> | <none> |
| my-deploy-7cf64887cf-kbjwg | 0/1 | Pending | 0s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-kbjwg | 0/1 | ContainerCreating | 0s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-kbjwg | 0/1 | ContainerCreating | 1s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-kbjwg | 0/1 | Running | 1s | 10.244.9.6 | k8s31node2 |
| my-deploy-7cf64887cf-kbjwg | 0/1 | Running | 11s | 10.244.9.6 | k8s31node2 |
| my-deploy-7cf64887cf-kbjwg | 1/1 | Running | 11s | 10.244.9.6 | k8s31node2 |
| my-deploy-569b69f85d-hzfzg | 1/1 | Terminating | 13m | 10.244.165.29 | k8s31node1 |
| my-deploy-7cf64887cf-89w8b | 0/1 | Pending | 0s | <none> | <none> |
| my-deploy-7cf64887cf-89w8b | 0/1 | Pending | 0s | <none> | k8s31node1 |
| my-deploy-7cf64887cf-89w8b | 0/1 | ContainerCreating | 0s | <none> | k8s31node1 |
| my-deploy-569b69f85d-hzfzg | 1/1 | Terminating | 13m | 10.244.165.29 | k8s31node1 |
| my-deploy-569b69f85d-hzfzg | 0/1 | Error | 13m | 10.244.165.29 | k8s31node1 |
| my-deploy-7cf64887cf-89w8b | 0/1 | ContainerCreating | 1s | <none> | k8s31node1 |
| my-deploy-569b69f85d-hzfzg | 0/1 | Error | 13m | 10.244.165.29 | k8s31node1 |
| my-deploy-569b69f85d-hzfzg | 0/1 | Error | 13m | 10.244.165.29 | k8s31node1 |
| my-deploy-7cf64887cf-89w8b | 0/1 | Running | 2s | 10.244.165.30 | k8s31node1 |
| my-deploy-7cf64887cf-89w8b | 0/1 | Running | 11s | 10.244.165.30 | k8s31node1 |
| my-deploy-7cf64887cf-89w8b | 1/1 | Running | 11s | 10.244.165.30 | k8s31node1 |
| my-deploy-569b69f85d-qrm5p | 1/1 | Terminating | 53m | 10.244.165.28 | k8s31node1 |
| my-deploy-7cf64887cf-crw52 | 0/1 | Pending | 0s | <none> | <none> |
| my-deploy-7cf64887cf-crw52 | 0/1 | Pending | 0s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-crw52 | 0/1 | ContainerCreating | 0s | <none> | k8s31node2 |
| my-deploy-569b69f85d-qrm5p | 1/1 | Terminating | 53m | 10.244.165.28 | k8s31node1 |
| my-deploy-569b69f85d-qrm5p | 0/1 | Error | 53m | 10.244.165.28 | k8s31node1 |
| my-deploy-7cf64887cf-crw52 | 0/1 | ContainerCreating | 1s | <none> | k8s31node2 |
| my-deploy-569b69f85d-qrm5p | 0/1 | Error | 53m | 10.244.165.28 | k8s31node1 |
| my-deploy-569b69f85d-qrm5p | 0/1 | Error | 53m | 10.244.165.28 | k8s31node1 |
| my-deploy-7cf64887cf-crw52 | 0/1 | Running | 2s | 10.244.9.5 | k8s31node2 |
| my-deploy-7cf64887cf-crw52 | 0/1 | Running | 11s | 10.244.9.5 | k8s31node2 |
| my-deploy-7cf64887cf-crw52 | 1/1 | Running | 11s | 10.244.9.5 | k8s31node2 |
| my-deploy-569b69f85d-cw7wt | 1/1 | Terminating | 53m | 10.244.9.3 | k8s31node2 |
| my-deploy-569b69f85d-cw7wt | 1/1 | Terminating | 53m | 10.244.9.3 | k8s31node2 |
| my-deploy-569b69f85d-cw7wt | 0/1 | Error | 53m | 10.244.9.3 | k8s31node2 |
| my-deploy-569b69f85d-cw7wt | 0/1 | Error | 53m | 10.244.9.3 | k8s31node2 |
| my-deploy-569b69f85d-cw7wt | 0/1 | Error | 53m | 10.244.9.3 | k8s31node2 |
- 过程分析
我们 deploy-first.yaml 没有配置 spec.strategy,都走默认配置,等效于
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
......
......
...... replicas=3
maxSurge=3*0.25=0.75=1(向上取整)最大允许超出 1 个。
maxUnavailable=3*0.25=0.75=0(向下取整)最大允许不可用为 0 个。也就是无论何时,系统都要保持至少3个副本可用。
Deployment 滚动升级时的三个副本数和默认maxSurge、maxUnavailable 配置关系如下:
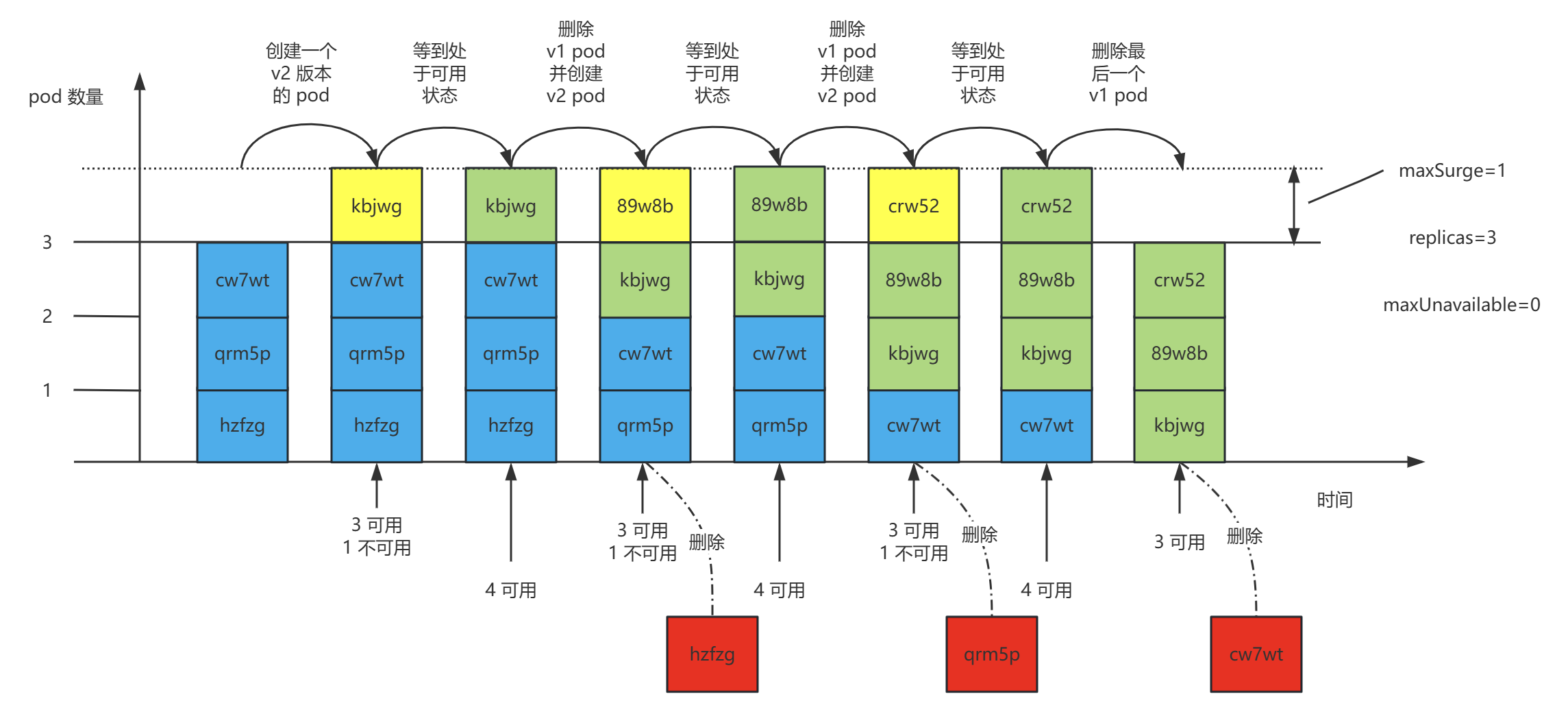
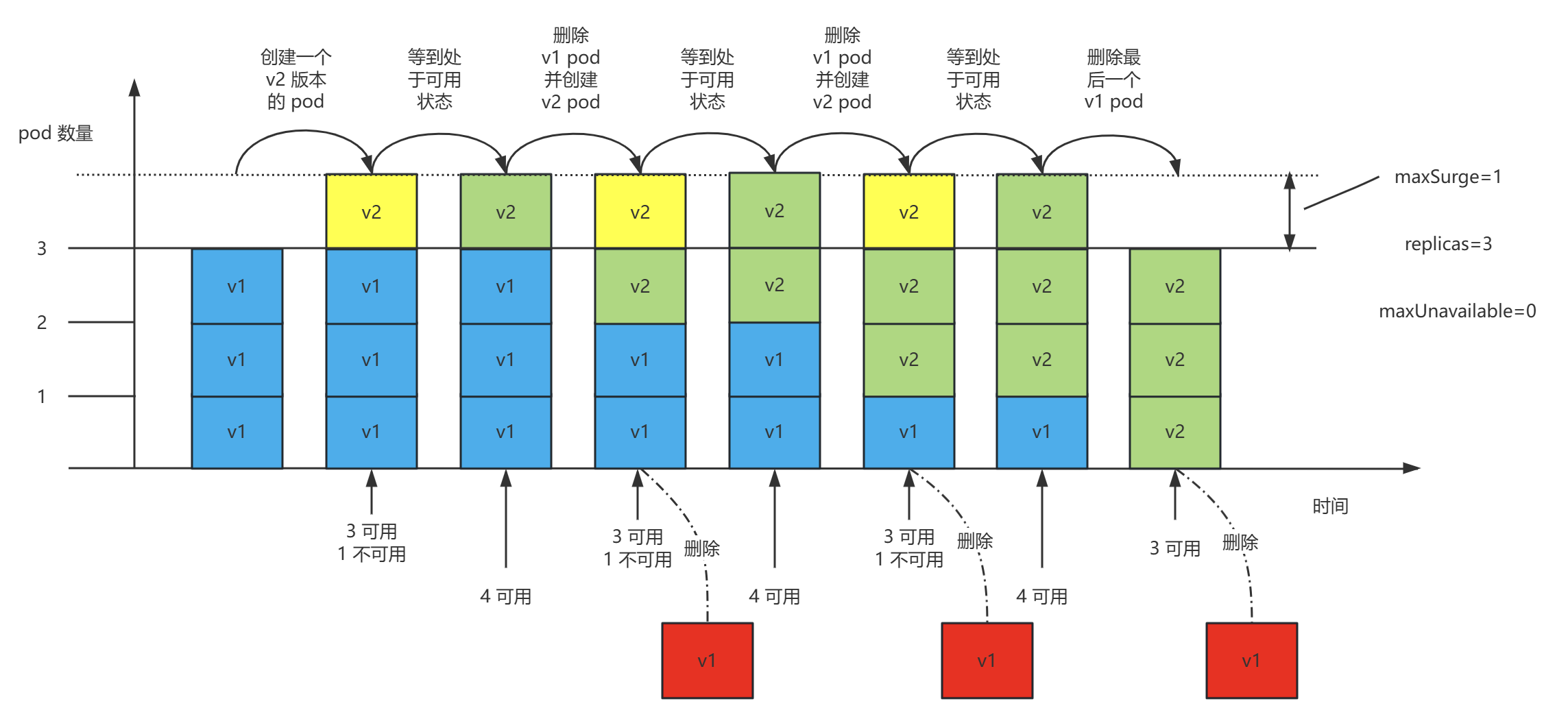
- 滚动更新之前,系统里面有3个 v1.0 的副本 cw7wt、qrm5p、hzfzg。
- 滚动更新开始后,kubelet 创建一个 v2.0 版本的 pod kbjwg。因为有就绪探针,此时它并没有处于可用状态。系统中现在有3个可用副本,一个不可用副本。
- 等到 kbjwg 就绪探针探测成功后,系统中有4个可用副本。
- 紧接着 kubelet 删除一个 v1.0 的 pod hzfzg 并创建一个 v2.0 版本的 pod 89w8b。
- 以此类推,直到3个 v2.0 版本的 pod 都处于可用状态,这个时候 kubelet 才删除最后一个 v1.0 pod cw7wt。
整个过程可以抽象成下面这张图:
- 访问接口
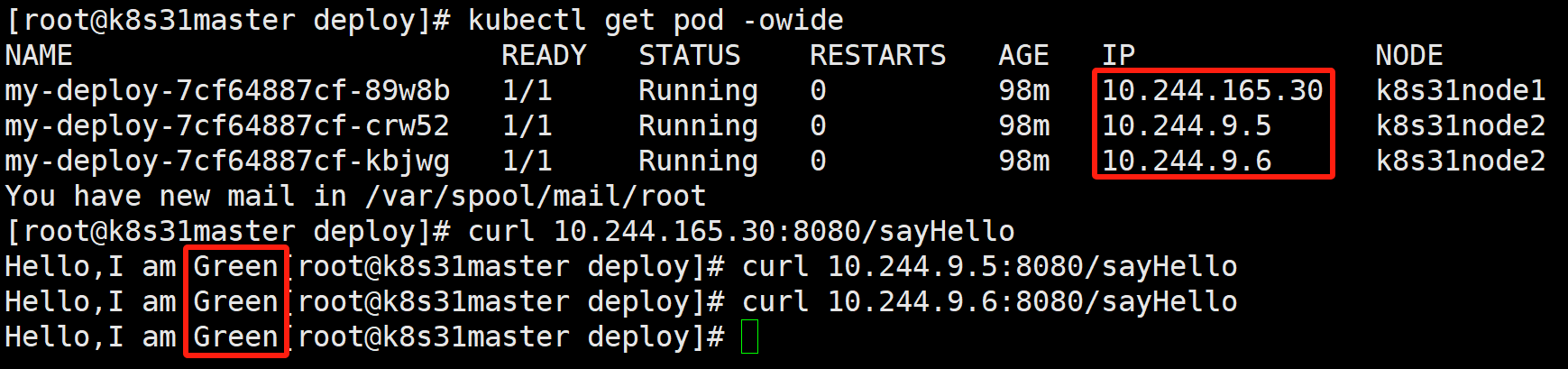
可以看到,所有 pod 的版本,已经都被替换为 2.0 了。
- 查看 ReplicaSet
kubectl get rs
可以看到有 2 个 rs 存在, my-deploy-569b69f85d 就是升级之前 v1.0 的 deploy 生成的 rs。
- 扩展
对于 replicas=3,maxSurge=1,maxUnavailable=1 大家可以很容易画出下面这张图。
大家可以根据我上面的思路,自行画看看。
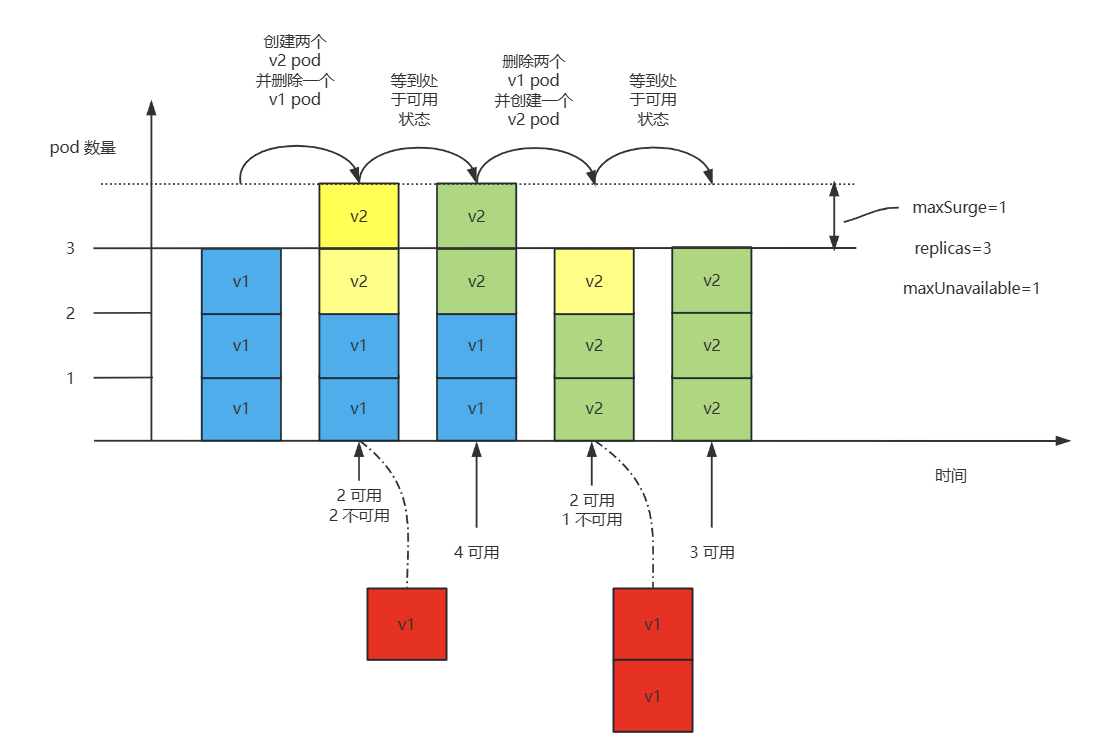
六、Deployment 实现 Pod 的版本回退
- 查看控制器的滚动历史
kubectl rollout history deploy my-deploy
- 版本号从1开始,依次递增
- 版本号 0 表示最后的修订。
- 创建 deploy 如果不给定 --record 参数,版本历史中的 CHANGE-CAUSE 这⼀栏会为空。这也会使⽤户很难辨别每次的版本做了哪些修改。

- 回滚到⼀个特定的 Deployment 版本
通过在 undo 命令中指定⼀个特定的版本号,便可以回滚到那个特定的版本。例如,如果想回滚到第⼀个版本,可以执⾏下述命令:
kubectl rollout undo deploy/my-deploy --to-revision=1
或者
kubectl rollout undo deploy my-deploy --to-revision=1

- 查看 ReplicaSet
kubectl get rs
ReplicaSet 版本,回滚到上一个版本。
- 访问接口

可以看到,所有 pod 的版本,已经都被替换为 1.0 了。
- 回滚到上一个版本
kubectl rollout undo deploy/my-deploy直接 undo 就行,因为 --to-revision 默认等于0,就是上一个版本。
七、Deployment 实现 Pod 的动态缩容
副本数从 3 缩容到 2
kubectl patch deployment my-deploy -p '{"spec":{"replicas":2}}'
# patch 以打补丁的方式,修改资源
# -p patch 的缩写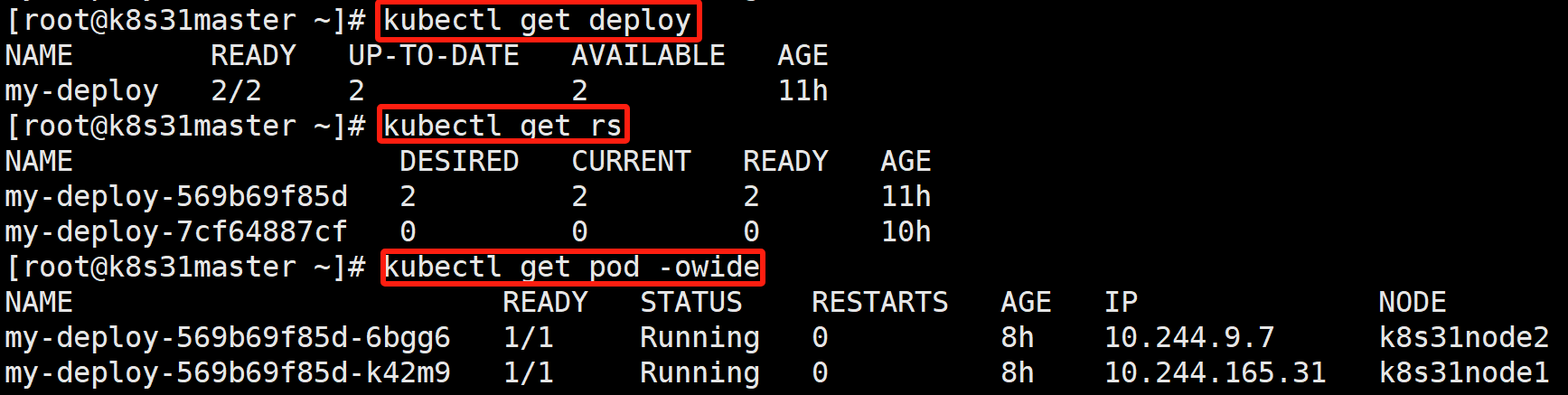
八、Deployment 实现 Pod 的重建式更新
修改 deploy-first.yaml,把 pod 更新策略变成 Recreate。
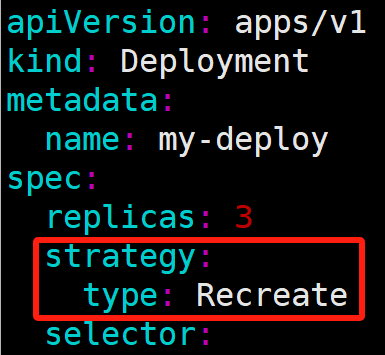
- 执行并监控
kubectl apply -f deploy-first.yaml --record
kubectl get pod -owide -w| NAME | READY | STATUS | RESTARTS | AGE | IP | NODE |
| my-deploy-569b69f85d-6bgg6 | 1/1 | Running | 1 | (11m | ago) | 2d8h |
| my-deploy-569b69f85d-k42m9 | 1/1 | Running | 1 | (11m | ago) | 2d8h |
| my-deploy-569b69f85d-jz8gb | 0/1 | Pending | 0 | 0s | <none> | <none> |
| my-deploy-569b69f85d-jz8gb | 0/1 | Pending | 0 | 0s | <none> | k8s31node1 |
| my-deploy-569b69f85d-jz8gb | 0/1 | ContainerCreating | 0 | 0s | <none> | k8s31node1 |
| my-deploy-569b69f85d-6bgg6 | 1/1 | Terminating | 1 | (14m | ago) | 2d8h |
| my-deploy-569b69f85d-k42m9 | 1/1 | Terminating | 1 | (14m | ago) | 2d8h |
| my-deploy-569b69f85d-jz8gb | 0/1 | Terminating | 0 | 0s | <none> | k8s31node1 |
| my-deploy-569b69f85d-6bgg6 | 1/1 | Terminating | 1 | (14m | ago) | 2d8h |
| my-deploy-569b69f85d-k42m9 | 1/1 | Terminating | 1 | (14m | ago) | 2d8h |
| my-deploy-569b69f85d-6bgg6 | 0/1 | Error | 1 | 2d8h | 10.244.9.9 | k8s31node2 |
| my-deploy-569b69f85d-k42m9 | 0/1 | Error | 1 | 2d8h | 10.244.165.32 | k8s31node1 |
| my-deploy-569b69f85d-6bgg6 | 0/1 | Error | 1 | 2d8h | 10.244.9.9 | k8s31node2 |
| my-deploy-569b69f85d-6bgg6 | 0/1 | Error | 1 | 2d8h | 10.244.9.9 | k8s31node2 |
| my-deploy-569b69f85d-k42m9 | 0/1 | Error | 1 | 2d8h | 10.244.165.32 | k8s31node1 |
| my-deploy-569b69f85d-k42m9 | 0/1 | Error | 1 | 2d8h | 10.244.165.32 | k8s31node1 |
| my-deploy-569b69f85d-jz8gb | 0/1 | ContainerStatusUnknown | 0 | 2s | <none> | k8s31node1 |
| my-deploy-569b69f85d-jz8gb | 0/1 | ContainerStatusUnknown | 0 | 2s | <none> | k8s31node1 |
| my-deploy-569b69f85d-jz8gb | 0/1 | ContainerStatusUnknown | 0 | 2s | <none> | k8s31node1 |
| my-deploy-7cf64887cf-4n766 | 0/1 | Pending | 0 | 0s | <none> | <none> |
| my-deploy-7cf64887cf-w8bhs | 0/1 | Pending | 0 | 0s | <none> | <none> |
| my-deploy-7cf64887cf-4n766 | 0/1 | Pending | 0 | 0s | <none> | k8s31node1 |
| my-deploy-7cf64887cf-8hsdj | 0/1 | Pending | 0 | 0s | <none> | <none> |
| my-deploy-7cf64887cf-w8bhs | 0/1 | Pending | 0 | 0s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-8hsdj | 0/1 | Pending | 0 | 0s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-4n766 | 0/1 | ContainerCreating | 0 | 0s | <none> | k8s31node1 |
| my-deploy-7cf64887cf-w8bhs | 0/1 | ContainerCreating | 0 | 0s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-8hsdj | 0/1 | ContainerCreating | 0 | 0s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-4n766 | 0/1 | ContainerCreating | 0 | 1s | <none> | k8s31node1 |
| my-deploy-7cf64887cf-w8bhs | 0/1 | ContainerCreating | 0 | 1s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-8hsdj | 0/1 | ContainerCreating | 0 | 1s | <none> | k8s31node2 |
| my-deploy-7cf64887cf-8hsdj | 0/1 | Running | 0 | 2s | 10.244.9.11 | k8s31node2 |
| my-deploy-7cf64887cf-w8bhs | 0/1 | Running | 0 | 2s | 10.244.9.10 | k8s31node2 |
| my-deploy-7cf64887cf-4n766 | 0/1 | Running | 0 | 2s | 10.244.165.33 | k8s31node1 |
| my-deploy-7cf64887cf-4n766 | 0/1 | Running | 0 | 11s | 10.244.165.33 | k8s31node1 |
| my-deploy-7cf64887cf-w8bhs | 0/1 | Running | 0 | 11s | 10.244.9.10 | k8s31node2 |
| my-deploy-7cf64887cf-8hsdj | 0/1 | Running | 0 | 11s | 10.244.9.11 | k8s31node2 |
| my-deploy-7cf64887cf-8hsdj | 1/1 | Running | 0 | 11s | 10.244.9.11 | k8s31node2 |
| my-deploy-7cf64887cf-w8bhs | 1/1 | Running | 0 | 11s | 10.244.9.10 | k8s31node2 |
| my-deploy-7cf64887cf-4n766 | 1/1 | Running | 0 | 11s | 10.244.165.33 | k8s31node1 |
- 过程分析
- 刚开始我们有两个 1.0 版本的 pod:6bgg6、k42m9
- 因为 deploy-first.yaml 文档 replicas=3,kubelet 尝试再创建一个 1.0 版本的 jz8gb。
- kubelet 发现 pod 更新策略变成 Recreate。删除所有已经存在的 1.0 版本 Pod:6bgg6、k42m9、jz8gb,再重新创建新的 2.0 版本 Pod:8hsdj、w8bhs、4n766。
- 重建式更新策略 Recreate,会删除所有已经存在的 pod,再重新创建新的 pod,所以会造成线上服务在版本更新的时候不可用,所以生产环境很少采用这种方式。
- 查看滚动历史
kubectl rollout history deploy/my-deploy 
- 可以看到,加了 --record 参数后,CHANGE_CAUSE 会帮我们记录下更新原因了。
- --record 参数已被官方标记为 已过时。
- 可以通过手动添加
kubernetes.io/change-cause注解的方式,来记录 CHANGE_CAUSE。- 例如,在更新 Deployment 后,运行以下命令来设置变更原因:
kubectl annotate deployment/<deployment-name> kubernetes.io/change-cause="Your change description here"
- 确保替换 <deployment-name> 为你实际的 Deployment 名称,并将 "Your change description here" 替换为描述此次变更的实际文本。

- 查看 rs、pod
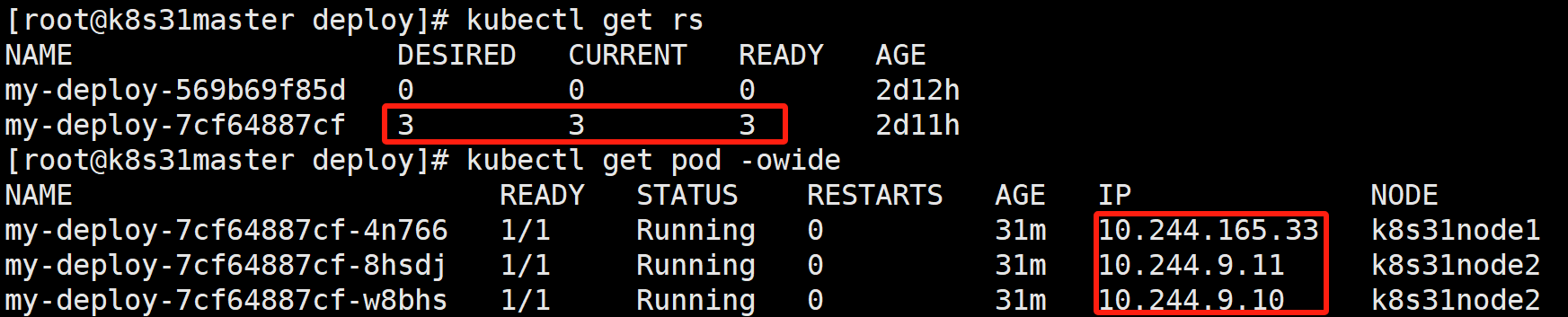
- 访问接口
尝试在集群不同节点上访问接口:
[root@k8s31master ~]# curl 10.244.165.33:8080/sayHello
[root@k8s31node1 ~]# curl 10.244.9.11:8080/sayHello
[root@k8s31node2 ~]# curl 10.244.9.10:8080/sayHello


可以看到,所有版本都升级为 2.0 了。
从这也能看出,pod 的 IP 是一种 clusterIp,集群内的任何节点都能正常访问到。
- 删除 deploy
删除 deploy,为下面的实验做准备。
kubectl delete -f deploy-first.yaml
kubectl get deploy
kubectl get rs
kubectl get pod -owide
从这也能看出,删除 Deployment,则它所创建的 ReplicaSet、Pod 也会被一并删除。

















 2488
2488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









