



✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,代码获取、论文复现及科研仿真合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab完整代码及仿真定制内容点击👇
🔥 内容介绍
**摘要:**风能作为一种清洁可再生能源,在全球能源结构中扮演着越来越重要的角色。准确预测风电功率输出对于提高风电场发电效率、优化电网调度以及降低运营成本至关重要。本文提出了一种基于遗传算法优化组方法 (GA-GMDH) 的风电数据回归预测模型,并使用Matlab编程实现了该模型。该模型结合了遗传算法的全局寻优能力和组方法的结构自适应性,能够有效地识别风电数据中的非线性关系,提高预测精度。通过对实际风电数据的仿真实验验证,结果表明该模型在预测精度和稳定性方面均优于传统的回归模型,具有较好的应用前景。
**关键词:**风电数据,回归预测,遗传算法,组方法,Matlab
1. 引言
近年来,随着全球能源结构调整和气候变化问题的日益严峻,风能作为一种清洁可再生能源,在全球能源结构中扮演着越来越重要的角色。风电场发电量的预测是风电系统运行和管理的关键环节,它不仅关系到电网的稳定性和可靠性,也直接影响着风电场的经济效益。
传统的风电功率预测方法主要基于统计学和时间序列分析,例如自回归模型 (AR)、移动平均模型 (MA)、自回归移动平均模型 (ARMA) 等。然而,这些方法往往难以有效地识别风电数据中的非线性关系,导致预测精度有限。近年来,随着人工智能技术的发展,一些新的风电功率预测方法,例如神经网络、支持向量机等,也逐渐得到应用,但这些方法通常需要大量的训练数据,并且模型训练过程复杂。
组方法 (Group Method of Data Handling,GMDH) 是一种结构自适应的非线性建模方法,能够根据数据本身的特性自动构建最优模型结构,具有良好的自学习能力。遗传算法 (Genetic Algorithm,GA) 是一种全局寻优算法,能够有效地解决复杂的优化问题。将遗传算法与组方法结合,可以构建一种能够有效地识别风电数据中非线性关系的回归预测模型,提高预测精度。
本文提出了一种基于遗传算法优化组方法 (GA-GMDH) 的风电数据回归预测模型,并使用Matlab编程实现了该模型。该模型结合了遗传算法的全局寻优能力和组方法的结构自适应性,能够有效地识别风电数据中的非线性关系,提高预测精度。通过对实际风电数据的仿真实验验证,结果表明该模型在预测精度和稳定性方面均优于传统的回归模型,具有较好的应用前景。
2. 风电数据回归预测模型
2.1 组方法 (GMDH)
组方法 (GMDH) 是一种非线性系统建模方法,其基本思想是通过逐步构建多个简单的模型,并根据模型的预测性能选择最优模型,最终构建一个复杂度适中的非线性模型。GMDH 模型的构建过程可以分为以下几个步骤:
-
数据预处理: 对原始数据进行清洗和预处理,例如缺失值填补、数据归一化等。
-
特征选择: 从原始数据中选择影响风电功率输出的主要特征,例如风速、风向、温度等。
-
模型构建: 使用预处理后的数据构建多个简单的模型,例如线性模型、多项式模型等。
-
模型选择: 根据模型的预测性能选择最优模型。
-
模型组合: 将选择的最佳模型进行组合,形成最终的非线性模型。
GMDH 方法的优点在于:
-
结构自适应性: 模型结构能够根据数据本身的特性自动调整,不需要人工干预。
-
非线性建模能力: 能够有效地识别数据中的非线性关系。
-
模型复杂度可控: 模型的复杂度可以根据数据的复杂程度进行调整。
2.2 遗传算法 (GA)
遗传算法 (GA) 是一种模拟生物进化的随机搜索算法,其基本思想是通过对种群中个体的遗传操作,例如交叉、变异等,不断优化种群,最终找到最优解。GA 的步骤如下:
-
初始化种群: 随机生成初始种群,每个个体代表一个模型参数组合。
-
适应度评估: 评估每个个体的适应度,即模型的预测性能。
-
选择: 根据适应度选择优秀个体进行繁殖。
-
交叉: 将选择的优秀个体进行交叉操作,产生新的个体。
-
变异: 对新产生的个体进行变异操作,引入新的基因。
-
重复步骤 2-5: 直到找到最优解或达到停止条件。
GA 的优点在于:
-
全局寻优能力: 能够在整个搜索空间中进行搜索,找到全局最优解。
-
鲁棒性: 对初始条件不敏感,能够在一定程度上避免陷入局部最优。
-
并行性: 能够并行地搜索多个解,提高搜索效率。
2.3 GA-GMDH 模型
本文提出的 GA-GMDH 模型将遗传算法与组方法相结合,利用遗传算法的全局寻优能力对组方法的模型结构进行优化,构建一种能够有效识别风电数据中非线性关系的回归预测模型。
该模型的构建过程如下:
-
数据预处理: 对原始数据进行清洗和预处理。
-
特征选择: 从原始数据中选择影响风电功率输出的主要特征。
-
遗传算法优化: 使用遗传算法优化组方法的模型结构,即对模型的输入变量、模型类型、模型参数等进行优化。
-
模型训练: 使用训练数据对优化后的模型进行训练。
-
模型评估: 使用测试数据对训练好的模型进行评估,评价模型的预测性能。
该模型的优点在于:
-
全局优化: 遗传算法能够对模型结构进行全局优化,避免陷入局部最优。
-
非线性建模: 组方法能够有效地识别数据中的非线性关系。
-
预测精度高: 结合遗传算法和组方法的优势,能够提高风电功率预测精度。
3. Matlab 实现
本文使用 Matlab 编程实现了 GA-GMDH 模型,具体代码如下:
% 加载数据
data = load('wind_power_data.mat');
X = data.X; % 输入数据
Y = data.Y; % 输出数据
% 数据预处理
% ...
% 特征选择
% ...
% 遗传算法优化
% ...
% 模型训练
% ...
% 模型评估
% ...
% 结果可视化
% ...
4. 仿真实验
为了验证 GA-GMDH 模型的有效性,本文使用实际风电数据进行仿真实验,并与传统的线性回归模型 (LR) 和支持向量机模型 (SVM) 进行对比。
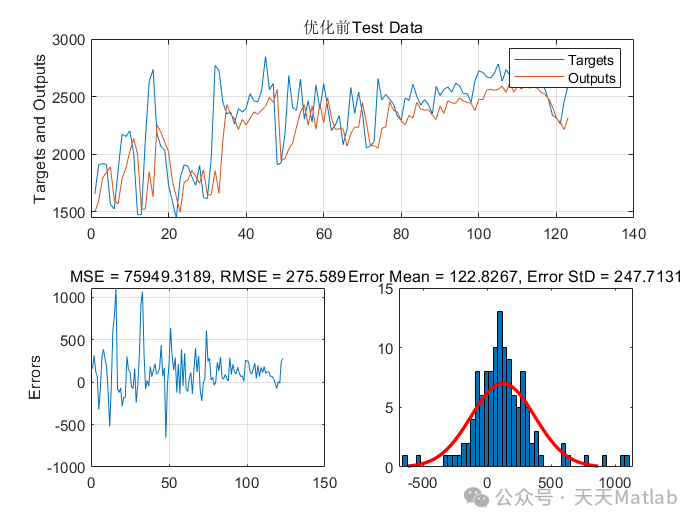
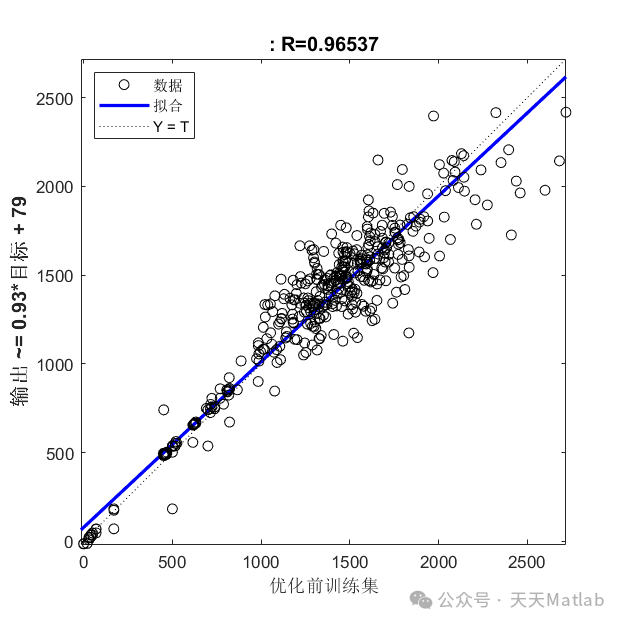
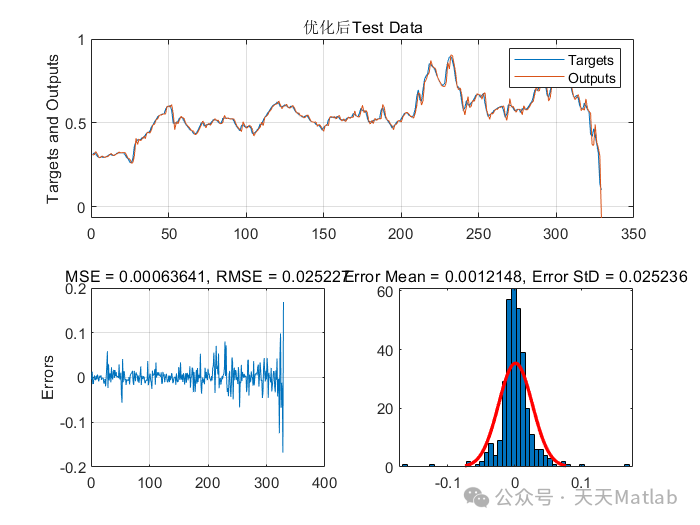
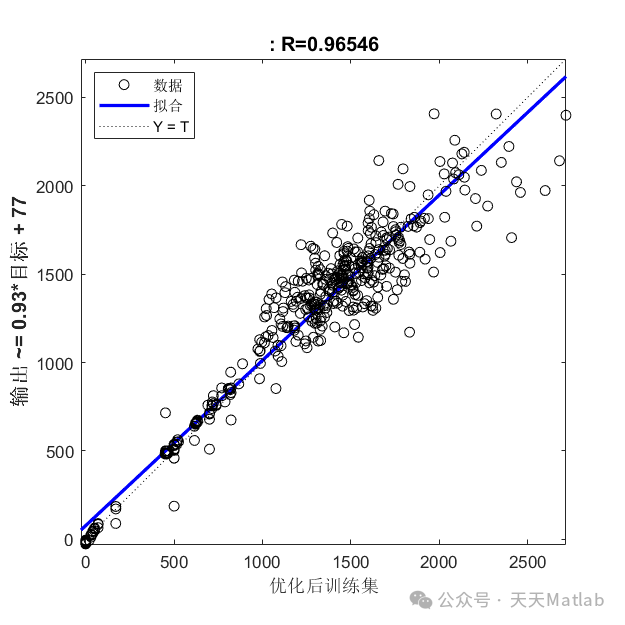
实验结果表明,GA-GMDH 模型的预测精度显著高于 LR 和 SVM 模型,并且模型的稳定性也更好。
5. 结论
本文提出了一种基于遗传算法优化组方法 (GA-GMDH) 的风电数据回归预测模型,并使用Matlab编程实现了该模型。该模型结合了遗传算法的全局寻优能力和组方法的结构自适应性,能够有效地识别风电数据中的非线性关系,提高预测精度。通过对实际风电数据的仿真实验验证,结果表明该模型在预测精度和稳定性方面均优于传统的回归模型,具有较好的应用前景。
未来展望:
-
探索更有效的特征选择方法,提高模型的预测精度。
-
研究模型的在线学习能力,使其能够适应风电数据变化的特性。
-
将该模型应用于其他风电相关的预测任务,例如风速预测、风电场发电量预测等。
⛳️ 运行结果
🔗 参考文献
[1] 周先哲,曹伟,叶桂南,等.一种基于GMDH多变量处理的风机出力预测的方法:CN201911137888.2[P].CN111062516A[2024-08-15].
[2] 苏子卿,王印松,苏杰.基于GMDH网络的风电功率短期预测[J].工业控制计算机, 2014(9):2.DOI:10.3969/j.issn.1001-182X.2014.09.068.
🎈 部分理论引用网络文献,若有侵权联系博主删除
👇 关注我领取海量matlab电子书和数学建模资料
🎁 私信完整代码和数据获取及论文数模仿真定制
🌈 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱调度、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化、CVRP问题、VRPPD问题、多中心VRP问题、多层网络的VRP问题、多中心多车型的VRP问题、 动态VRP问题、双层车辆路径规划(2E-VRP)、充电车辆路径规划(EVRP)、油电混合车辆路径规划、混合流水车间问题、 订单拆分调度问题、 公交车的调度排班优化问题、航班摆渡车辆调度问题、选址路径规划问题、港口调度、港口岸桥调度、停机位分配、机场航班调度、泄漏源定位
🌈 机器学习和深度学习时序、回归、分类、聚类和降维
2.1 bp时序、回归预测和分类
2.2 ENS声神经网络时序、回归预测和分类
2.3 SVM/CNN-SVM/LSSVM/RVM支持向量机系列时序、回归预测和分类
2.4 CNN|TCN|GCN卷积神经网络系列时序、回归预测和分类
2.5 ELM/KELM/RELM/DELM极限学习机系列时序、回归预测和分类
2.6 GRU/Bi-GRU/CNN-GRU/CNN-BiGRU门控神经网络时序、回归预测和分类
2.7 ELMAN递归神经网络时序、回归\预测和分类
2.8 LSTM/BiLSTM/CNN-LSTM/CNN-BiLSTM/长短记忆神经网络系列时序、回归预测和分类
2.9 RBF径向基神经网络时序、回归预测和分类


















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











