




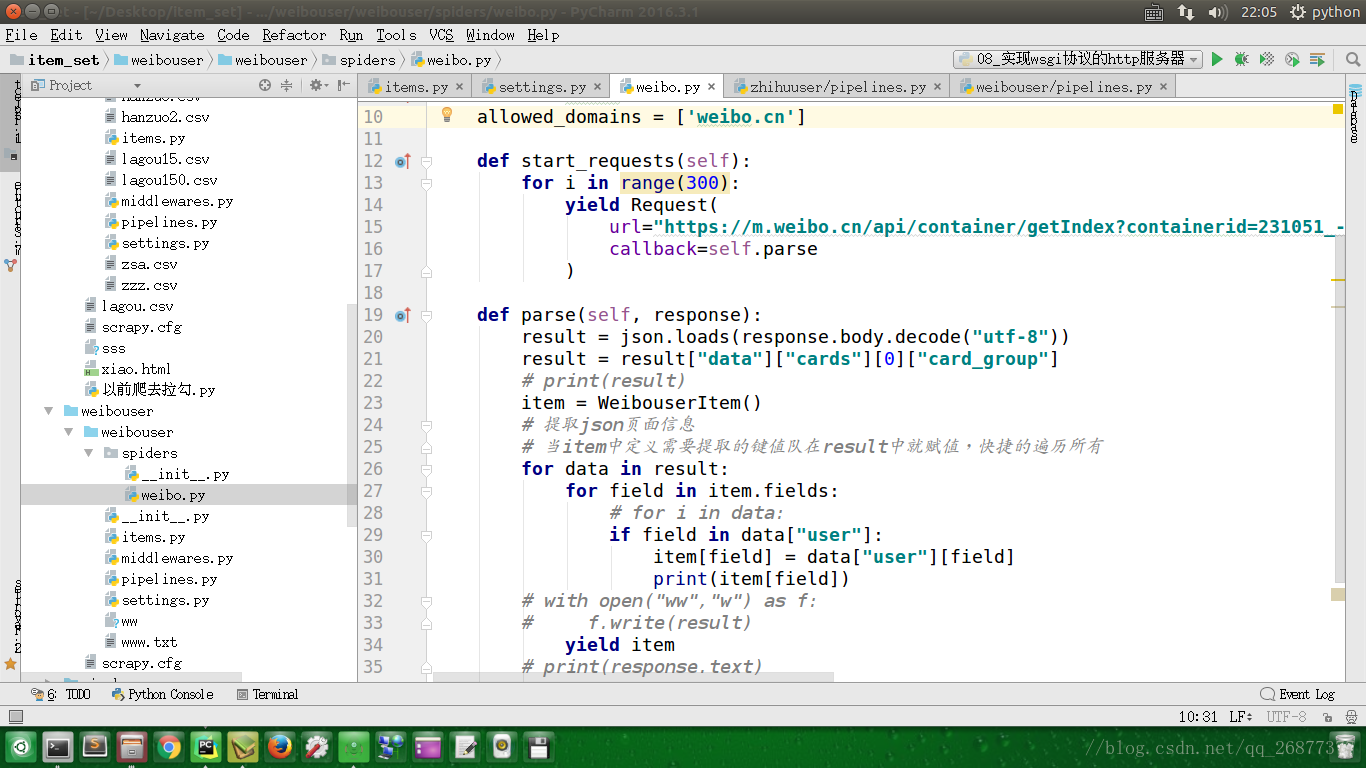
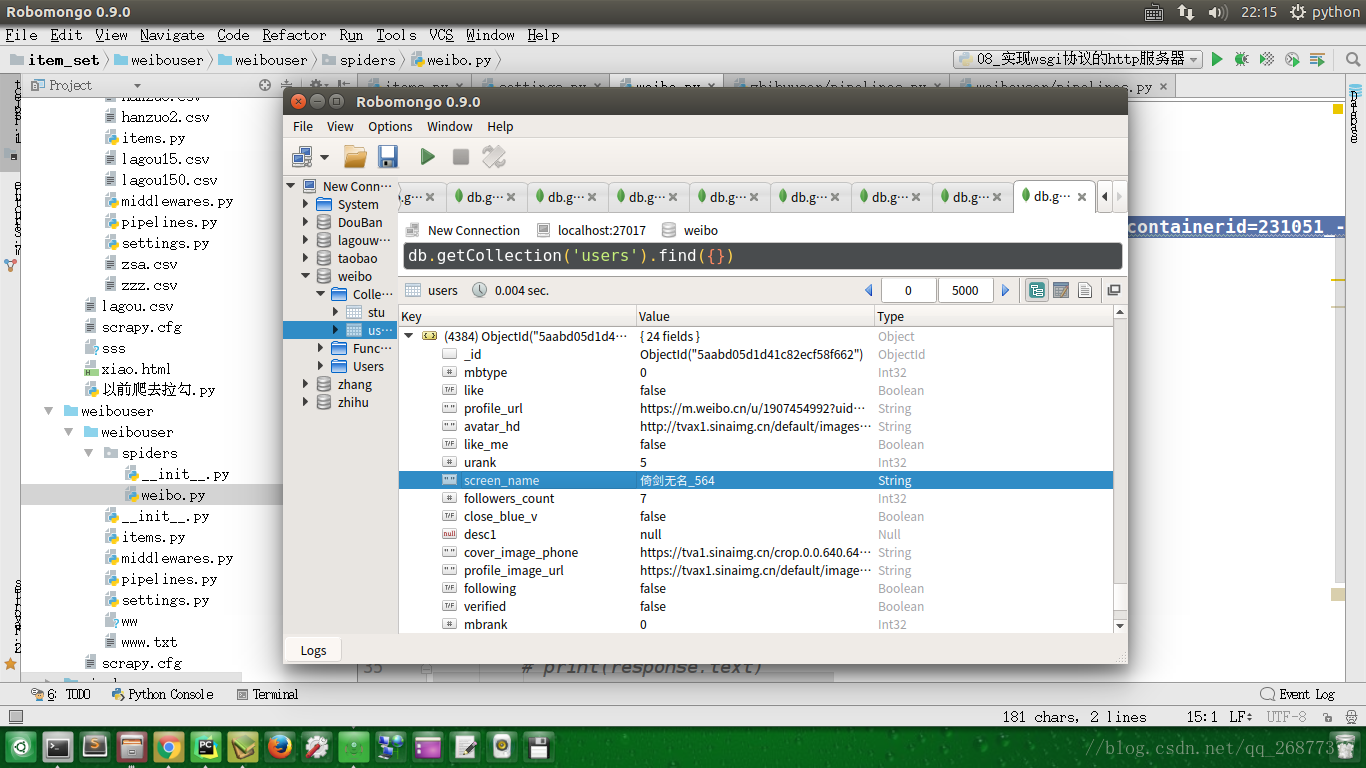
 本篇博客介绍了一个使用Python Scrapy框架实现的爬虫项目,该项目旨在从微博平台抓取特定用户的粉丝信息。爬虫通过发送请求到指定API接口获取JSON数据,并解析这些数据以提取粉丝的详细资料。
本篇博客介绍了一个使用Python Scrapy框架实现的爬虫项目,该项目旨在从微博平台抓取特定用户的粉丝信息。爬虫通过发送请求到指定API接口获取JSON数据,并解析这些数据以提取粉丝的详细资料。
import json
from scrapy import Spider, Request
from weibouser.items import WeibouserItem
class WeiboSpider(Spider):
name = 'weibo'
allowed_domains = ['weibo.cn']
def start_requests(self):
for i in range(300):
yield Request(
url="https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_2619766381&luicode=10000011&lfid=1076032619766381&featurecode=20000320&since_id="+str(i),
callback=self.parse
)
def parse(self, response):
result = json.loads(response.body.decode("utf-8"))
result = result["data"]["cards"][0]["card_group"]
# print(result)
item = WeibouserItem()
# 提取json页面信息
# 当item中定义需要提取的键值队在result中就赋值,快捷的遍历所有
for data in result:
for field in item.fields:
# for i in data:
if field in data["user"]:
item[field] = data["user"][field]
print(item[field])
# with open("ww","w") as f:
# f.write(result)
yield item
# print(response.text)
from scrapy import Spider, Request
from weibouser.items import WeibouserItem
class WeiboSpider(Spider):
name = 'weibo'
allowed_domains = ['weibo.cn']
def start_requests(self):
for i in range(300):
yield Request(
url="https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_2619766381&luicode=10000011&lfid=1076032619766381&featurecode=20000320&since_id="+str(i),
callback=self.parse
)
def parse(self, response):
result = json.loads(response.body.decode("utf-8"))
result = result["data"]["cards"][0]["card_group"]
# print(result)
item = WeibouserItem()
# 提取json页面信息
# 当item中定义需要提取的键值队在result中就赋值,快捷的遍历所有
for data in result:
for field in item.fields:
# for i in data:
if field in data["user"]:
item[field] = data["user"][field]
print(item[field])
# with open("ww","w") as f:
# f.write(result)
yield item
# print(response.text)


















 5349
5349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









