






 本文详细介绍了Redis的多种功能。包括多路复用IO模型,持久化的RDB和AOF模式,事务的执行与错误处理,排序命令的使用及优化,订阅发布和消息队列机制,慢查询的配置与管理,PipeLine流水线功能,GEO地理位置存储操作,以及bitmaps位图的应用场景等。
本文详细介绍了Redis的多种功能。包括多路复用IO模型,持久化的RDB和AOF模式,事务的执行与错误处理,排序命令的使用及优化,订阅发布和消息队列机制,慢查询的配置与管理,PipeLine流水线功能,GEO地理位置存储操作,以及bitmaps位图的应用场景等。
redis io模型
持久化
Redis的所有数据都是保存在内存中的,然后不定期的通过异步方式保存到磁盘上,称为半持久化模式;也可以把每次一数据变化都写到一个append only dile(aof)里面,称为全持久化模式
RDB模式
默认redis是会以快照的形式将数据持久化到磁盘上,配置文件中默认执行,也可以手动save和bgsave。
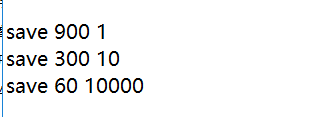
默认情况下:
- 900秒内发生了一次操作,则执行一次save;
- 300秒内发生了十次操作,则执行一次save;
- 60秒内发生了10000次操作,执行一次。
过程
- redis调用fork,创建一个子进程;
- 子进程将数据集写入一个临时RDB文件中;
- 当子进程完成对新RDB文件的写入时,redis用新的RDB文件替换原来的RDB文件,并删除旧的;
- 子进程与主进程共享内存,子进程负责将快照内容写入磁盘,主进程负责响应客户端指令,他两是并行执行的。
- save会暂停其他客户端的使用;
- bgsave则不会;
AOP持久化
记录服务器执行的所有写操作,并在服务器启动时,通过重新执行这些命令来还原数据集。默认没有启动改动能,通过appendonly=yes启动;
配置
appendfsync always 每次有数据修改发生时都会写入AOF文件;
appendfsync everysec 每秒同步一次,为默认策略;
appendfsync no 从不同步;
事务
仅满足串行隔离性,不满足原子性;没有回滚特性,一个事务内,如果后面的命令执行失败,不会导致前面成功的命令回滚。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> sadd "user:1:following" 2
QUEUED
127.0.0.1:6379> sadd "user:2:followers" 1
QUEUED
127.0.0.1:6379> exec
1) (integer) 1
2) (integer) 1
multi命令告诉redis,我接下来发送的命令你先不要执行,先暂时存起来。redis没有执行下面的两条sadd而是返回QUEUED表示这两条命令已经进入等待执行的事务队列。
当把所有要在同一事物中执行的命令都发给了redis之后,使用exec命令告诉redis将等待执行的事务队列中的所有命令按照发送顺序依次执行,exec命令的返回值就是这些命令返回值组成的列表,顺序相同。
错误处理
如果一个事务中的某个命令执行出错,redis会怎么处理?
- 语法错误,在事务中只要有一个命令由语法错误,执行exec命令后redis就会直接返回错误,连语法正确的命令都不会执行。2.6.5之前会忽略由语法错误的命令。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name value
QUEUED
127.0.0.1:6379> set name
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379> errorcommand name
(error) ERR unknown command 'errorcommand'
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get name
(nil)
- 运行错误,在命令执行时出现的错误,在实际执行之前是不会被发现的,所以是会被接收并执行的,如果事务里的一条命令出现了运行错误,事务里其他命令依然会继续执行。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set key 1
QUEUED
127.0.0.1:6379> sadd key 2
QUEUED
127.0.0.1:6379> set key 3
QUEUED
127.0.0.1:6379> exec
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
3) OK
127.0.0.1:6379> get key
"3"
可以看到正确的语句还是被执行了;
总结
redis没有关系型数据库事务提供的回滚功能,也因此,使得redis在事务上可以保持简洁和快速。
Watch命令介绍
在get获得键值后保证该键值不被其他客户端修改,直到函数执行完成后才允许其他客户端修改该键值,这样可以防止竟态条件。
watch命令可以监控一个或多个键,一旦其中有一个键被修改了,之后的事务就不会执行。监控一直持续到exec命令。
127.0.0.1:6379> set key 1
OK
127.0.0.1:6379> watch key
OK
127.0.0.1:6379> set key 2
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set key 3
QUEUED
127.0.0.1:6379> exec
(nil)
127.0.0.1:6379> get key
"2"
可以看到执行了watch命令后,事务执行前修改了key值,所以最后事务中的命令没有执行,exec返回空结果。
执行了exec命令后会取消所有键的监控,如果不想执行事务中的命令也可以用unwatch
取消监控。
排序
有序集合的集合操作
sort命令
可以对列表类型、集合类型和有序集合类型键进行排序,并且可以完成与关系数据库中的连接查询相类似的任务。
- 可以对列表类型进行排序
127.0.0.1:6379> lpush mlist 5 4 6 3 7 2 9 0
(integer) 8
127.0.0.1:6379> sort mlist
1) "0"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "9"
- 对有序集合类型排序是会忽略元素的分数,只针对元素自身的值进行排序。
127.0.0.1:6379> zadd myzset 50 2 40 3 20 1 60 5
(integer) 4
127.0.0.1:6379> sort myzset
1) "1"
2) "2"
3) "3"
4) "5"
- 可以通过alpha参数实现按照字典顺序排列非数字元素。
127.0.0.1:6379> lpush mylistalpha a c e d B C A
(integer) 7
127.0.0.1:6379> sort mylistalpha
(error) ERR One or more scores can't be converted into double
127.0.0.1:6379> sort mylistalpha alpha
1) "A"
2) "B"
3) "C"
4) "a"
5) "c"
6) "d"
7) "e"
总结
默认情况下,sort命令从小到大排列顺序,desc参数可以实现将元素按照从小到大的顺序排列。sort还支持limit参数来返回指定范围的结果。
127.0.0.1:6379> sort mylistalpha alpha desc limit 1 2
1) "d"
2) "c"
127.0.0.1:6379>
BY参数
BY参数的语法为BY参考键,参考键可以使字符串类型或者是散列类型键的某个字段。如果提供了BY参数,sort命令将不再依据元素自身的值进行排序,而是对每个元素使用元素的值替换参考键中的第一个"*"并获取其值,然后依据该值对元素排序。
127.0.0.1:6379> set itemscore:1 50
OK
127.0.0.1:6379> set itemscore:2 100
OK
127.0.0.1:6379> set itemscore:3 -10
OK
127.0.0.1:6379> sort sortbylist by itemscore:* desc
1) "2"
2) "1"
3) "3"
如果几个元素的参考键相同,则sort命令会再比较元素本身的值来决定元素的顺序。
127.0.0.1:6379> lpush sortbylist 4
(integer) 4
127.0.0.1:6379> set itemscore:4 50
OK
127.0.0.1:6379> sort sortbylist by itemscore:* desc
1) "2"
2) "4"
3) "1"
4) "3"
如果某个元素的参考键不存在时,会默认参考键的值为0。
get参数
get参数不影响排序,它的作用是使sort命令的返回结果不再是自身的值,而是get参数中指定的键值。
store参数
默认情况下sort会直接返回排序结果,如果希望保存排序结果,可以使用store参数。
127.0.0.1:6379> lpush list 2 3 1 4 2 5 5 2 4
(integer) 9
127.0.0.1:6379> sort list
1) "1"
2) "2"
3) "2"
4) "2"
5) "3"
6) "4"
7) "4"
8) "5"
9) "5"
127.0.0.1:6379> sort list store sort.result
(integer) 9
127.0.0.1:6379> lrange sort.result 0 -1
1) "1"
2) "2"
3) "2"
4) "2"
5) "3"
6) "4"
7) "4"
8) "5"
9) "5"
性能优化
sort命令时间复杂度为O(n+mlog(m)),n代表要排序元素个数,m代表返回的元素个数。
注意:
- 尽可能减少待排序键中元素的数量;
- 使用limit参数只获取需要的数据;
- 如果排序数量较大,尽可能使用store参数将结果缓存。
订阅发布
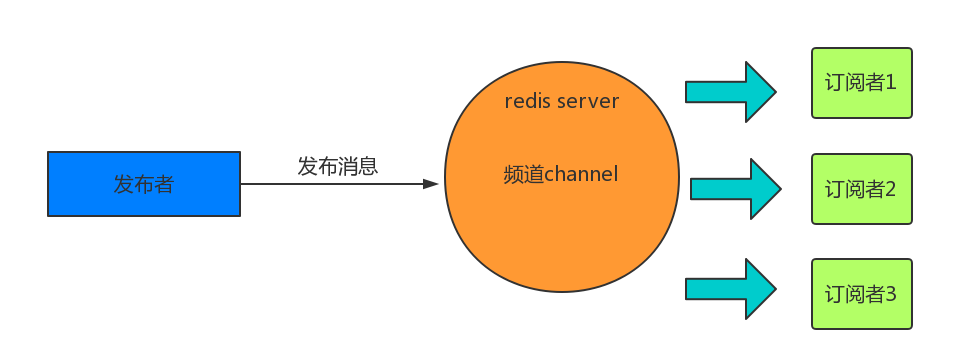
测试
打开两个客户端,一个执行发布,一个执行订阅,订阅者只要订阅这个频道就可以实时获得信息。
发布
127.0.0.1:6379> publish youku:tv "hello World"
(integer) 1
127.0.0.1:6379>
订阅
127.0.0.1:6379> subscribe youku:tv
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "youku:tv"
3) (integer) 1
1) "message"
2) "youku:tv"
3) "hello World"
退订unsubcribe [channel]
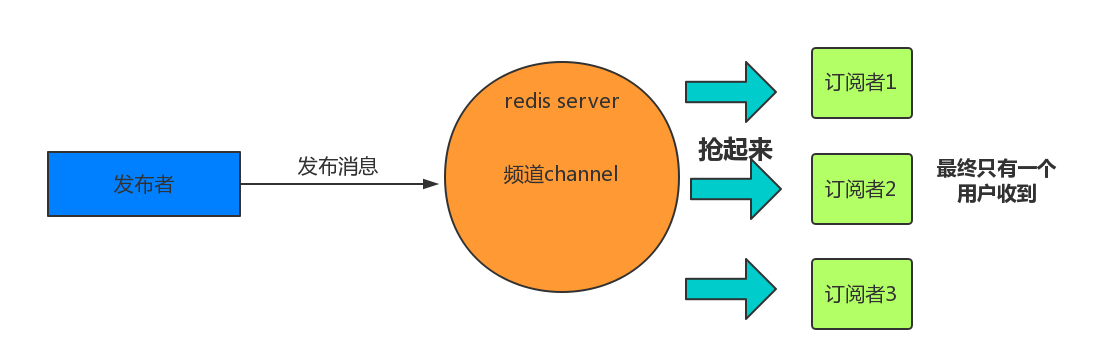
消息队列
redis消息队列是抢的模式。就是只有一个用户能收到,谁抢到就是谁的。
慢查询
客户端发送命令给redis,redis需要对慢查询排队处理。
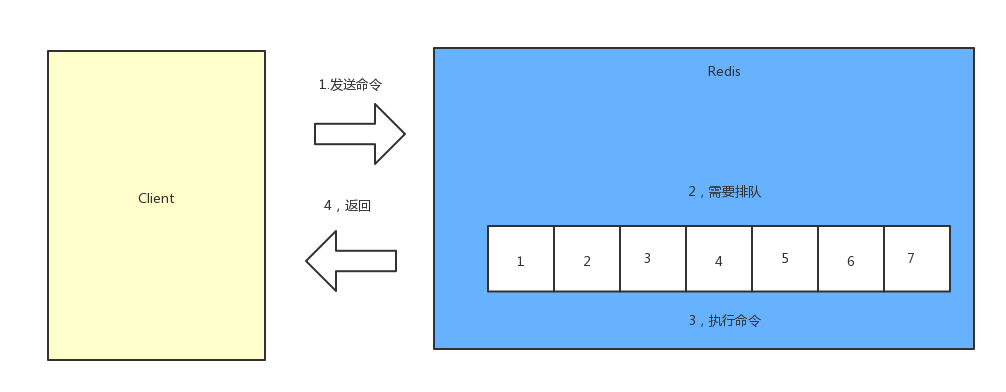
慢查询指的是内部执行事件超过某个指定时限的查询,使用两个配置项来控制。
如何配置慢查询
-
slowlog-max-len
服务器使用先进先出的方式保存多条慢查询日志,当服务器存储的慢查询日志等于slowlog-max-len选项的值时。服务器在添加一条新的慢查询日志之前,会先将最旧的一条慢查询日志删除。默认是128 通常为1000; -
slowlog-log-slower-than
该选项指定执行时间超过多少微秒;
执行时间超过这个值的命令会被记录到慢查询日志,默认为10ms,实际使用时1ms或2ms
slowlog-max-len=100
slowlog-log-slower-than=10000
比如这个配置代表超过10000微妙的命令会被放到队列中,并从100开始一直到1;
测试:
127.0.0.1:6379> config set slowlog-log-slower-than 0 //设为0,这样redis执行的命令都会被纪录进去
OK
127.0.0.1:6379> config set slowlog-max-len 10 //让服务器最多保留10条慢查询日志
OK
执行命令
127.0.0.1:6379> set msg "welcome my city"
OK
127.0.0.1:6379> set number 12345
OK
127.0.0.1:6379> set database "redis"
OK
查看日志
127.0.0.1:6379> slowlog get
1) 1) (integer) 4 #日志的唯一标识符
2) (integer) 1553053430 #命令执行时的UNIX时间戳
3) (integer) 6 #命令执行时长,以为微秒计
4) 1) "set" #命令参数
2) "database"
3) "redis"
2) 1) (integer) 3
2) (integer) 1553053421
3) (integer) 6
4) 1) "set"
2) "number"
3) "12345"
3) 1) (integer) 2
2) (integer) 1553053415
3) (integer) 27
4) 1) "set"
2) "msg"
3) "welcome my city"
慢查询的命令
- slowlog get 获取慢查询队列
- slowlog len 获取慢查询队列的长度
- slowlog reset 清空慢查询队列
注意:定期对慢查询进行持久化;
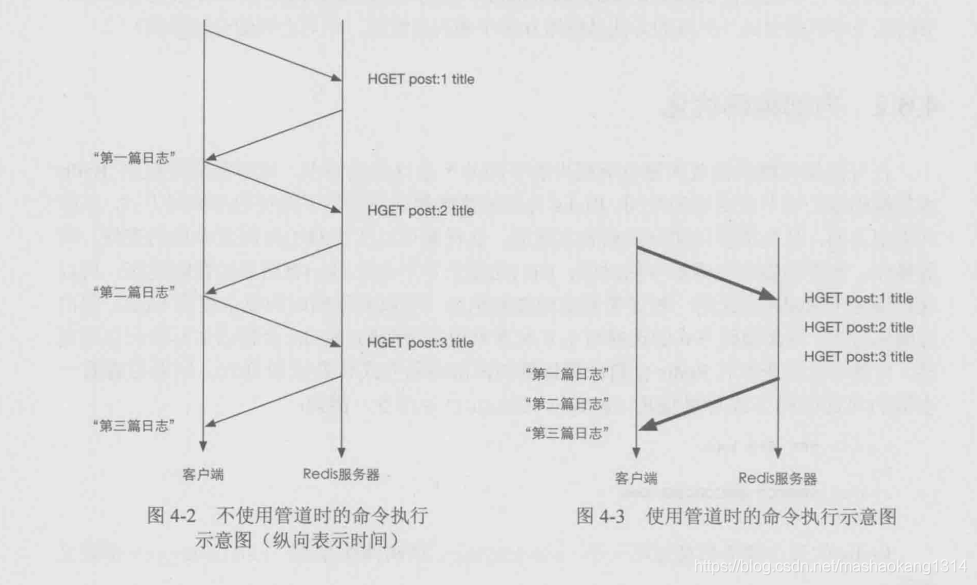
PipeLine流水线
概念
如果想同时使用hset和mset,可以通过使用PipeLine流水线功能;通过管道可以一次性发送多条命令并在执行完成后将这组命令一起通过管道发出。通过减少了客户端与redis的通信次数来实现降低往返时延累计值。而不使用pipeLine每个命令都要等上一个命令完成后才执行。
如何使用
private static void m2(){
Jedis jedis = new Jedis("localhost",6379);
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
Pipeline pip = jedis.pipelined();
for (int j = 0; j < (i + 1) * 100; j++) {
pip.hset("key"+j,"keyfield"+j,"keyvalue"+j);
}
pip.syncAndReturnAll();
}
long end = System.currentTimeMillis();
System.out.println(end-start);
}
GEO地理位置存储
redis3.2之后出现,使用zset来实现,最常用的工能就是微信里的附近的人,摇一摇功能。
如何操作
geo add 经度 维度 标识 …
127.0.0.1:6379> geoadd cities:location 117.20 40.11 beijing
(integer) 1
127.0.0.1:6379> geopos cities:location beijing
1) 1) "117.19999998807907"
2) "40.109999205000996"
计算距离
127.0.0.1:6379> geoadd cities:location 117.20 40.11 beijing
(integer) 1
127.0.0.1:6379> geopos cities:location beijing
1) 1) "117.19999998807907"
2) "40.109999205000996"
127.0.0.1:6379> geoadd cities:location 107.40 33.42 xian
(integer) 1
127.0.0.1:6379> geodist cities:location beijing xian km
"1145.9492"
bitmaps位图
采用位存储
setbit key 位数 1|0
getbit key 位数
bitcount key #统计1的个数
应用场景
朋友圈点赞功能:
# 1000 用户id 设置第一千位为1
127.0.0.1:6379> setbit p1 1000 1
(integer) 0
127.0.0.1:6379> setbit p1 666 1
(integer) 0
# 统计点赞人数,统计位数为1的个数
127.0.0.1:6379> bitcount p1
(integer) 2
# id为666的用户取消点赞
127.0.0.1:6379> setbit p1 666 0
(integer) 1
127.0.0.1:6379> bitcount p1
(integer) 1

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









