




在互联网企业里, *nux 下的 C/C++ 编程主要的焦点还是 server 开发,关于不同的 server 模型,在 UNP 第 30 章里有过简单的讨论,这里得出的结论就是多线程和多进程的 server 模型效率较高。但书中缺乏对多路复用机制的讨论,而当前主流的 server 模型则是 epoll+multi-threads/multi-processes , lighttpd 就属于这种模型。本文将探讨一个更加高效的 server 模型, half-synchorize/half-asynchorize 模式。
half-sync/half-async 模型
此模式最早是由著名的 C++ 网络编程框架 ACE 的作者的一篇文章,其主要思想就是用异步的方式来处理 IO 事件,而用同步的方式来处理业务逻辑,同步和异步之间使用一个队列作为缓冲,如下图

此模型详细介绍可参考 原文 。
spserver 简介
引用作者对 spserver 的介绍: spserver 是一个实现了半同步 / 半异步 (Half-Sync/Half-Async) 和领导者 / 追随者 (Leader/Follower) 模式的服务器框架,能够简化 TCP server 的开发工作。 并且 spserve 使用了 libevent 作为底层的异步响应机制的实现。
我抱着一种学习的态度,阅读了其 half-sync/half-async 模式的实现代码,本文也可以看做是一篇 spserver 的源码分析。
代码结构
1) spserver :主文件,程序从 start 方法里启动。
2) speventcb :主要的回调函数实现逻辑。
3) spsession :代表一个会话。
4) sprequest :封装了客户端 ip 和 messageDecoder ,个人认为封装的不好。
5) spresponse :封装了响应的内容。
6) spiochannel :封装底层 IO 。
7) spmsgdecoder :消息解析器,判断消息是否完整。
8) spbuffer :对 libevent 里的 buffer 的简单封装。
9) spthread 、 spthreadpool 、 spexecutor :线程池的封装。
代码分析
spsession 代表一个连接的会话,它属于 half-sync/half-async 模型的 3 层结构中的 queue ,业务逻辑和网络 IO 通过 session 中的 input buffer 和 output list 来通信。
先来看一下 SP_Session 类的成员:
SP_Sid_t mSid; //session id ,详见下一节
struct event * mReadEvent; // 和 session 关联的读写事件
struct event * mWriteEvent;
SP_Handler * mHandler; // 用户实现业务逻辑的 handler
void * mArg; //event args
SP_Buffer * mInBuffer; // 输入缓冲队列
SP_Request * mRequest; // 对请求的封装
int mOutOffset; // 输出偏移量,以字节为单位,表明 out list 中已输出的字节数
SP_ArrayList * mOutList; // list of msg ,输出的缓冲队列
char mStatus; // 当前 session 的状态,可为 eNormal, eWouldExit, eExit
char mRunning; // 是否在运行
char mWriting; // 是否在写
char mReading; // 是否在读
unsigned int mTotalRead, mTotalWrite; // 本 session 已读写的字节数
SP_IOChannel * mIOChannel; // 关联的 IOChannel
session 是通过 SP_SessionManager 来进行管理的,它实际上是一个 64*1024 的二维数组, entry 的类型定义如下:
typedef struct tagSP_SessionEntry {
uint16_t mSeq;
uint16_t mNext;
SP_Session * mSession;
} SP_SessionEntry;
其中每个 entry 都是通过一个 key 来标识其在 matrix 中的坐标, key=1024*row+col ,而 seq 标识这个 entry 被使用过多少次,通过 key 和 seq 就可以形成一个 ssion id 了。 entry 中的 mNext 成员指向 list 中下一个成员的 key ,这样就可以快速的定位和分配 list 的 tailor 。
程序从 SP_Server 中的 start 方法开始,绑定 server 的地址和端口后,注册 signal handler ,然后注册 listenfd 的 onAccept 异步回调函数。这里值得一提的是 libevent 对所有的异步调用做了抽象,甚至包括 signal handler 。
程序的流程是通过 libevent 对不同的事件来回调不同的函数推进的,主要的回调函数有 onAccept , onRead , onWrite 和 onResponse ,下面将逐一讨论它们的流程。
onAccept
下面结合流程图对代码分析:
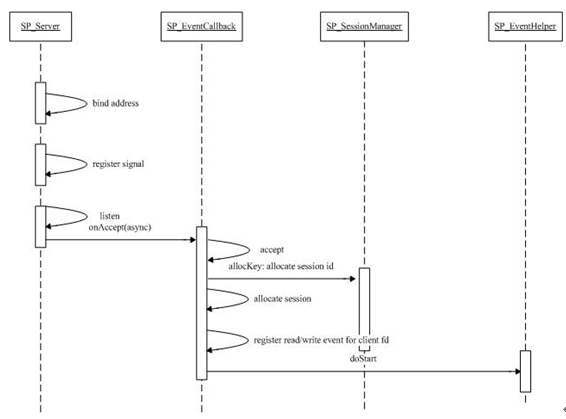
onAccept 中完成了连接的初始化,主要包括:
1) accept 并为返回的 clientfd 注册读写事件。
2) 从 session manager 中为连接分配一个 session 。
3) 调用 SP_EventHelper :: doStart 方法。
以上这些过程虽然都是通过事件触发的,但都是在主线程的 main loop 里的 event_base_loop 中调用的。而 HS-HA 模式主要是通过 doStart 方法来体现的。
doStart 实际上是把一个 task 放到一个 task queue 里,而后 task 由一个线程完成。其主要逻辑在 SP_EventHelper :: start 中实现。
在 start 中的执行步骤如下:
1) 初始化 IOChannel 。
2) 分配 response 对象。
3) 调用业务逻辑实现 SP_Handler 中的 start 方法。 SP_Handler 中的 start 方法可以调用 block 函数,这也是为何此函数会由一个线程来调用。其实凡是用户实现的业务逻辑都是通过线程来异步调用的。
4) 调用 msgqueue_push ,将经过 start 中用户返回的 response 对象放入 msgqueue 中。 msgqueue 是一个带异步通知机制的队列,当 response 对象放入队列后, msgqueue_pop 方法将被调用,它实际将 response 对象作为参数,调用 onResponse 方法。
onResponse
onResponse 函数并不是通过 libevent 的回调机制触发的,实际上它是 SP_EventArg 中的 response queue( 实际为 event_msgqueue 类型 ) 的回调函数,当队列中有 response 对象时,对每个 response 对象均调用 onResponse 函数。 onResponse 函数的主要作用就是将 response 对象中包含的 msg 对象加入到 session 的 outList 中。这里值得一提的是, SP_Message 和 SP_Session 式多对多的关系,这样可以节省重复的 SP_Message 占用的内存。
onRead
onRead 函数在 fd 可读和超时的情况下被调用,其主要流程为:
1 )判断触发事件是否为可读,若为超时,则调用 SP_EventHelper::doTimeout ,它将用户实现的 timeout 函数封装为 task , task 被 push 到 eventArg 中的 InputResultQueue 中,而后由 executor 来执行。
2 )若为可读,则读入数据并解码,解码成功则调用 SP_EventHelper::doWork ,它将用户实现的 handle 函数封装为 task , task 被 push 到 eventArg 中的 InputResultQueue 中,而后由 executor 来执行。
onWrite
onRead 函数在 fd 可写和超时的情况下被调用,其主要流程为:
1 )判断触发事件是否为可写,若为超时,则调用 SP_EventHelper::doTimeout ,它将用户实现的 timeout 函数封装为 task ,由线程调用。 task 被 push 到 eventArg 中的 InputResultQueue 中,而后由 executor 来执行。
2 )若为可写,则将 session 中的 outList 中的 msg 发往 client ,值得注意的是,这里是通过 writev 来一次尽可能的多的写出数据。
总结
由上可知,一般来说 Server 是通过 session 来管理不同的连接,且在 session 中保留输入缓冲和输出缓冲,而后通过异步事件机制来向网络中读写数据,这便形成了 half-async 端。而用户实现自身的业务逻辑,且这些业务逻辑中可调用阻塞式的函数,这便形成了 half-sync 端,而为了提高效率,在 half-sync 端可使用多线程机制。

















 7644
7644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









