







入门神经网络详解
前向传播
简单神经网络结构

- 每一层由单元组成
- 输入层是由训练集的实例特征向量传入
- 经过链接点的权重传入下一层,一层的输出是下一层的输入
- 隐藏层的个数是任意的,输入层有一层,输出层有一层
- 每个单元也可以称作神经节点,根据生物学来源定义
- 以上层数为2层的神经元(输入层不算)
- 一层加权求和,然后根据非线性方程转化输出
- 作为多层向前神经网络,理论上,如果有足够的隐藏层和足够大的训练集,可以模拟任何方程
单个神经元结构
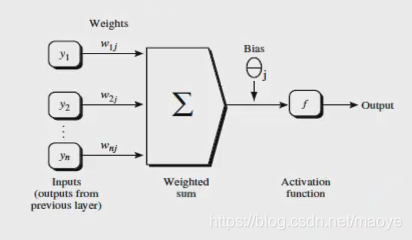
- 单个神经元由 输入项乘以权重加上偏置,最后经过激活函数得到输入
- 以采用sigmod函数作为激活为例
- s i g m o d ( ∑ i = 1 n w i ∗ x i + b ) sigmod(\sum_{i=1}^{n}w_i * x_i + b) sigmod(i=1∑nwi∗xi+b)
- Sigmod函数:
- 1 1 + e − x \frac{1}{1+e^{-x}} 1+e−x1
后向传播算法
- 通过迭代性的来处理训练集中的实例。
- 对比经过神经网络输入层预测值与真实值之间
- 反向来以最小化误差来更新每个链接的权重
- 算法详细介绍
- 输入:数据集| 学习率,一个多层前向神经网络
- 输出:一个训练好的神经网络
- 初始化权重和偏向:随机初始化在-1到1之间,或者-0.5 到0.5之间每个单元有一个偏向
根据误差反向传送计算过程
- 对于输出层
- E r r i = O j ( 1 − O j ) ( T j − O j ) Err_i=O_j(1-O_j)(T_j-O_j) Erri=Oj(1−Oj)(Tj−Oj)
- 因为 sigmod 函数s(x)的求导的导数为
- δ s ( x ) δ x = s ( x ) ( 1 − s ( x ) ) \frac{\delta s(x)}{\delta x} = s(x)(1-s(x)) δxδs(x)=s(x)(1−s(x))
- 对于掩藏层
- E r r j = O j ( 1 − O j ) ∑ k E r r k w j k Err_j=O_j(1-O_j)\sum_kErr_{k}w_{jk} Errj=Oj(1−Oj)k∑Errkwjk
- 权重更新
- Δ W i j = η E r r j O i w i j = w i j + Δ w i j η 为 学 习 了 率 \Delta W_{ij}=\eta Err_jO_i \\ w_{ij} = w_{ij} + \Delta w_{ij} \\ \eta 为学习了率 ΔWij=ηErrjOiwij=wij+Δwijη为学习了率
- 偏向更新
- Δ θ j = η E r r j θ j = θ j + Δ j \Delta\theta_j = \eta Err_j \\ \theta_j = \theta_j + \Delta_j Δθj=ηErrjθj=θj+Δj
终止条件
- 权重更新低于某个阈值
- 预测的错误率低于某个阈值
- 达到预设一定的循环函数
举一个例子
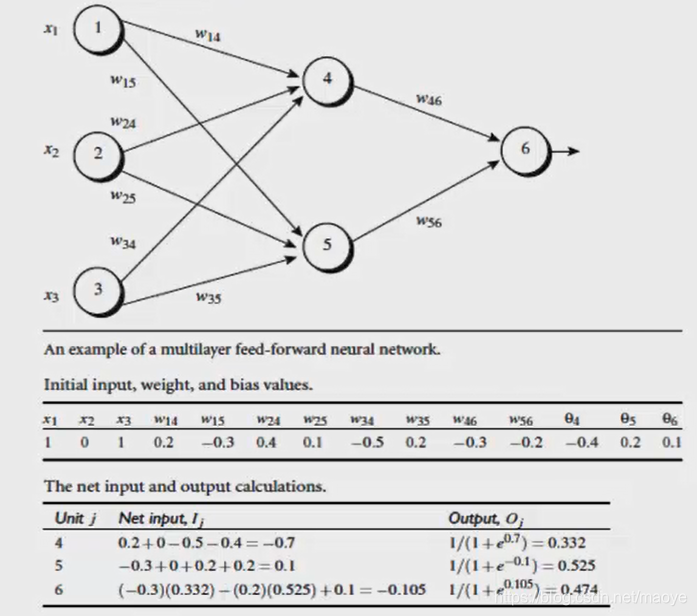
前向传播计算
输入层
x = [1, 0, 1]
掩藏层的权重
- 神经元4对应的权重与偏置
w4 = [0.2, 0.4, -0.5]
b4 = -0.4 - 神经元5对应的权重与偏置
w5 = [-0.3, 0.1, 0.2]
b5 = 0.2 - 掩藏层的输出结果计算
O 4 = 1 1 + e − ( 0.2 ∗ 1 + 0.4 ∗ 0 + ( − 0.5 ) ∗ 1 + ( − 0.4 ) ) = 1 1 + e 0.7 = 0.33181 O_4 = \frac{1}{1+e^{-(0.2*1 + 0.4*0 + (-0.5) * 1 + (-0.4))}} = \frac{1}{1+e^{0.7}} = 0.33181 O4=1+e−(0.2∗1+0.4∗0+(−0.5)∗1+(−0.4))1=1+e0.71=0.33181
O 5 = 1 1 + e − ( − 0.3 ∗ 1 + 0.1 ∗ 0 + 1 ∗ 0.2 + 0.2 ) = 1 1 + e − 0.1 = 0.52498 O_5=\frac{1}{1+e^{-(-0.3*1 + 0.1*0 +1*0.2+0.2)}} = \frac{1}{1+e^{-0.1}} = 0.52498 O5=1+e−(−0.3∗1+0.1∗0+1∗0.2+0.2)1=1+e−0.11=0.52498
同理演算输出层结果
x = [0.33181 , 0.52498]
- 输出层权重与偏置
w6 = [-0.3, -0.2]
b6 = 0.1 - 输出层演算结果
O 6 = 1 1 + e − ( 0.33181 ∗ ( − 0.3 ) + ( − 0.2 ) ∗ 0.52498 + 0.1 ) = 1 1 + e 0.10454 = 0.47389 O_6 = \frac{1}{ 1 + e^{-(0.33181 * (-0.3) + ( -0.2) * 0.52498 + 0.1)}} = \frac{1}{1+e^{0.10454}}=0.47389 O6=1+e−(0.33181∗(−0.3)+(−0.2)∗0.52498+0.1)1=1+e0.104541=0.47389
误差反向传播计算
首先假设真实的结果为
T
=
1
η
=
0.9
T = 1 \\ \eta = 0.9
T=1η=0.9
- 那神经元6的误差为:
E r r 6 = 0.47389 ∗ ( 1 − 0.47389 ) ( 1 − 0.47389 ) = 0.13117 Err_6 = 0.47389 * (1-0.47389)(1 - 0.47389)= 0.13117 Err6=0.47389∗(1−0.47389)(1−0.47389)=0.13117 - 神经元4的误差为:
E r r 4 = 0.33181 ∗ ( 1 − 0.33181 ) ∗ ( − 0.3 ) ∗ 0.13117 = − 0.0087246 Err_4 = 0.33181 * (1-0.33181)* (-0.3) * 0.13117 = -0.0087246 Err4=0.33181∗(1−0.33181)∗(−0.3)∗0.13117=−0.0087246 - 神经元5的误差为:
E r r 5 = 0.52498 ∗ ( 1 − 0.52498 ) ∗ ( − 0.2 ) ∗ 0.13117 = − 0.0065421 Err_5 = 0.52498 * (1-0.52498)* (-0.2) * 0.13117 = -0.0065421 Err5=0.52498∗(1−0.52498)∗(−0.2)∗0.13117=−0.0065421
对神经元 4-6 与神经元5-6的更新
w
46
=
−
0.3
+
0.9
∗
0.13117
∗
0.33181
=
−
0.26083
w_{46} = -0.3 + 0.9 * 0.13117 * 0.33181 = -0.26083
w46=−0.3+0.9∗0.13117∗0.33181=−0.26083
w
56
=
−
0.2
+
0.9
∗
0.13117
∗
0.52498
=
−
0.13802
w_{56} = -0.2 + 0.9 * 0.13117 * 0.52498 = -0.13802
w56=−0.2+0.9∗0.13117∗0.52498=−0.13802
b
6
=
0.1
+
0.9
∗
0.13117
b_{6} = 0.1 + 0.9 * 0.13117
b6=0.1+0.9∗0.13117

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









