



Elasticsearch功能的核心是搜索引擎
全文检索(Full-Text Search)是一种从大量文本数据中快速检索出包含指定词汇或短语的信息的技术。
全文检索实现原理
1)在全文检索中,首先需要对文本数据进行处理,包括分词、去除停用词等。然后,对处理后的文本数据建立索引,索引会记录每个单词在文档中的位置信息以及其他相关的元数据,如词频、权重等。
这个过程通常使用倒排索引(inverted index)来实现,倒排索引将单词映射到包含该单词的文档列表中,以便快速定位相关文档。
2)当用户发起搜索请求时,搜索引擎会根据用户提供的关键词或短语,在建立好的索引中查找匹配的文档。搜索引擎会根据索引中的信息计算文档的相关性,并按照相关性排序返回搜索结果。用户可以通过不同的搜索策略和过滤条件来精确控制搜索结果的质量和范围。
在一个文档集合中,每个文档都可视为一个词语的集合,倒排索引则是将词语映射到包含这个词语的文档的数据结构。
正排索引(Forward Index)和倒排索引(Inverted Index)是全文检索中常用的两种索引结构,它们在索引和搜索的过程中扮演不同的角色。
正排索引(正向索引)
正排索引是将文档按顺序排列并进行编号的索引结构。每个文档都包含了完整的文本内容,以及其他相关的属性或元数据,如标题、作者、发布日期等。在正排索引中,可以根据文档编号或其他属性快速定位和访问文档的内容。正排索引适合用于需要对文档进行整体检索和展示的场景,但对于包含大量文本内容的数据集来说,正排索引的存储和查询效率可能会受到限制。
在MySQL 中通过 ID 查找就是一种正排索引的应用。
倒排索引(反向索引)
倒排索引是根据单词或短语建立的索引结构。它将每个单词映射到包含该单词的文档列表中。倒排索引的建立过程是先对文档进行分词处理,然后记录每个单词在哪些文档中出现,以及出现的位置信息。通过倒排索引,可以根据关键词或短语快速找到包含这些词语的文档,并确定它们的相关性。倒排索引适用于在大规模文本数据中进行关键词搜索和相关性排序的场景,它能够快速定位文档,提高搜索效率。
倒排索引的实现涉及到多个步骤:
1)文档预处理:对文档进行分词处理,移除停用词,并进行词干提取等操作。
2)构建词典:将处理后的词汇添加到词典中,并为每个词汇分配一个唯一的ID。
3) 创建倒排列表:对于词典中的每个词汇,创建一个倒排列表,记录该词汇在哪些文档中出现,以及出现的位置信息。
4)存储索引文件:将词典和倒排列表存储在磁盘上的索引文件中,通常会进行压缩处理以减小存储空间并提升查询效率。
5)查询处理:当用户发起搜索请求时,搜索引擎会从词典中查找每个关键词对应的倒排列表,并根据列表中的文档ID快速定位到包含这些关键词的文档。
索引
索引是Elasticsearch中用于存储和管理相关数据的逻辑容器。索引可以看作数据库中的一个表,它包含了一组具有相似结构的文档。在Elasticsearch中,数据以JSON格式的文档存储在索引内。每个索引具有唯一的名称,以便在执行搜索、更新和删除操作时进行引用。索引的名称可以由用户自定义,但必须全部小写。总之,索引是Elasticsearch中用于组织、存储和检索数据的一个核心概念。通过将数据划分为不同的索引,用户可以更有效地管理和查询相关数据。
映射(Mapping)
映射类似于关系型数据库中的Schema,可以近似地理解为“表结构”。
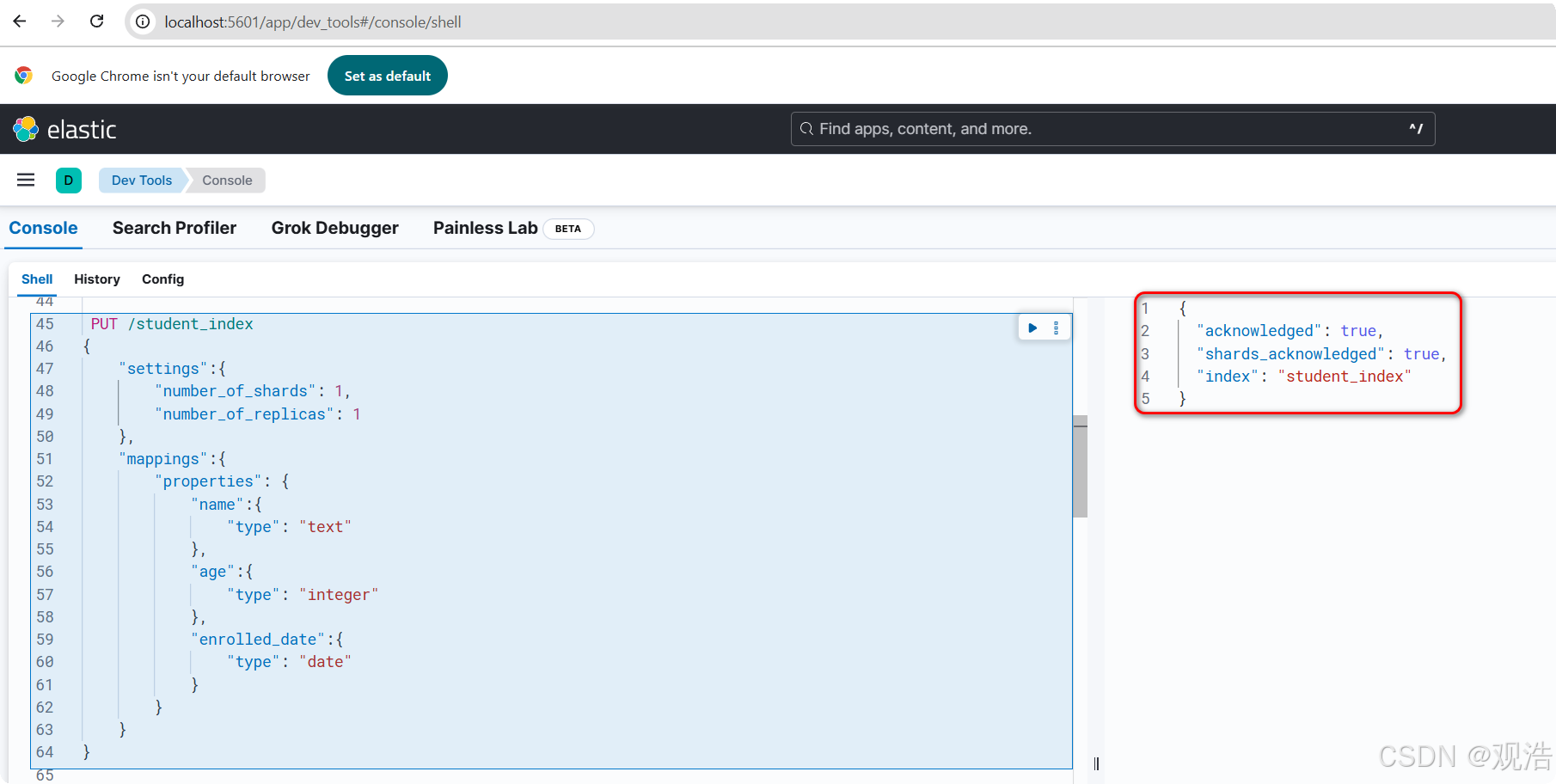
PUT /student_index
{
"settings":{
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings":{
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
},
"enrolled_date":{
"type": "date"
}
}
}
}
文档
关系型数据库将数据以行或元组为单位存储在数据库表中,而Elasticsearch将数据以文档为单位存储在索引中。作为Elasticsearch的基本存储单元,文档是指存储在Elasticsearch索引中的JSON对象。文档中的数据由键值对构成。键是字段的名称,值是不同数据类型的字段。不同的数据类型包含但不限于字符串类型、数字类型、布尔类型、对象类型等。
文档元数据,用于标注文档的相关信息
_index:文档所属的索引名
_type:文档所属的类型名
_id:文档唯一id
_source: 文档的原始Json数据
_version: 文档的版本号,修改删除操作_version都会自增1
_seq_no: 和_version一样,一旦数据发生更改,数据也一直是累计的。Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
_primary_term: _primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免PrimaryShard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。
ElasticSearch索引操作详解
创建索引
PUT /student_index
{
"settings":{
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings":{
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
},
"enrolled_date":{
"type": "date"
}
}
}
}
删除索引
DELETE /student_index
修改索引
PUT /student_index/_settings
{
"index":{
"number_of_replicas": 2
}
}
动态更新索引的部分mapping字段信息
PUT /student_index/_mapping
{
"properties": {
"grade":{
"type": "integer"
}
}
}
索引别名详解
索引别名可以指向一个或多个索引,并且可以在任何需要索引名称的API中使用。别名提供了极大的灵活性,它允许用户执行以下操作。
如何为索引添加别名
GET /myindex
POST /_aliases
{
"actions": [
{
"add": {
"index": "myindex",
"alias": "myindex_alias1"
}
}
]
}
多索引检索的实现方案
不使用别名的方案
方式一:使用逗号对多个索引名称进行分隔
PUT /tlmall_logs_202501
PUT /tlmall_logs_202502
PUT /tlmall_logs_202503
POST tlmall_logs_202501,tlmall_logs_202502,tlmall_logs_202503/_search
方式二:使用通配符进行多索引检索
POST tlmall_logs_*/_search
使用别名的方案
使别名关联已有索引
POST /_aliases
{
"actions": [
{
"add": {
"index": "tlmall_logs_202501",
"alias": "tlmall_logs_2025"
}
},
{
"add": {
"index": "tlmall_logs_202502",
"alias": "tlmall_logs_2025"
}
},
{
"add": {
"index": "tlmall_logs_202503",
"alias": "tlmall_logs_2025"
}
}
]
}
使用别名进行检索
GET tlmall_logs_2025/_search
思考:使用别名和基于索引的检索效率一样吗?
若索引和别名指向相同,则在相同检索条件下的检索效率是一致的,因为索引别名只是物理索引的软
链接的名称而已。
注意:
1) 对相同索引别名的物理索引建议有一致的映射,以提升检索效率。
2) 推荐充分发挥索引别名在检索方面的优势,但在写入和更新时还得使用物理索引。

















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









