





目录
1. 进程的定义
进程是处于执行期的程序,但进程并不仅仅局限于一段可执行程序代码,通常还包括其他资源,如打开的文件、挂起的信号、内核内部数据、处理器状态、地址空间以及一个或者多个执行线程、用来存放全局变量的数据段等。
进程是一个程序的一次执行的过程,同时也是资源分配的最小单位。它和程序是有本反区别的:程序是静态的,是一些保存在磁盘上的指令的有序集合,没有任何执行的概念;而进程是一个动态的概念,它是程序执行的过程,包括动态创建、调度和消亡的整个过程。进程是程序执行和资源管理的最小单位。因此,对系统而言,当用户在系统中输入命令执行一个程序时,它将启动一个进程。
程序本身不是进程,进程是处于执行期的程序以及它所包含的资源的总称。实际上完全可能存在两个不同的进程执行的是同一个程序,并且两个或两个以上并存的进程还可以共享许多如打开文件、地址空间之类的资源。
在Linux系统中,进程分为用户进程、守护进程、批处理进程:
- 用户进程:也成终端进程,用户通过终端命令启用的进程。
- 守护进程:也成精灵进程,即运行的守护进程,在系统引导时间就启动,是后台服务进程,大多数服务进程都是通过守护进程实现的。
- 批处理进程:执行的是批处理文件、shell脚本。
2. 进程的控制模块
进程控制模块(Process Control Module) 是内核的核心组件之一,负责进程的创建、终止、状态转换、调度及资源管理等全生命周期操作。它通过操控进程控制块(如 Linux 的task_struct)实现对进程的管理,是多任务操作系统实现并发执行的基础。
对于 task_struct 文件,可以通过如下路径获取内核源码:
通常存放在 include/linux/sched.h 路径下:
也可以直接通过在线工具,在线查看:
sched.h - include/linux/sched.h - Linux source code v6.17.1 - Bootlin Elixir Cross Referencer
这里如果不知道自己Linux内核是多少的可以通过如下命令查看:
uname -r其中6代表主版本号、8代表次版本号、0代表修订号、85代表发行版本号、后面为发行版本标识generic标识通用版本:

3. 进程的创建
内核通过一个唯一的进程标识值PID标识每个进程。PID是一个int型数,其代表系统中允许同时存在的最大数目。
一个进程要被执行,首先要被创建,进程需要一定的系统资源,如CPU时间片、内存空间、操作文件、硬件设备等,进程创建包括如下操作:
- 初始化当前进程PCB(进程控制模块),分别配有效进程 ID,设置进程优先级和CP时间片
- 为进程分配内存空间
- 加载任务到内存空间,将进程代码复制到内存空间
- 设置进程执行状态为就绪态,将进程PCB放入到进程队列中
操作系统内核为方便所有进程进行管理,将进程的PCB放在队列中,新创建的进程放入队尾,当进程执行完毕后,从队列中踢除,Linux系统中有两个重要的队列:
- 运行队列:内核要寻找一个新的进程在CPU上运行,必须考虑处于可运行状态的进程,不过扫描整个进程链表是相对低效的,所以引入了可运行状态进程的双向循环链表,也叫运行队列。
- 等待队列:处于睡眠状态的进程被放入等待队列当中,等待队列是以双循环列表为基础的数据结构,与进程调度机制紧密结合,能够用于实现核心的异步时间通知机制。
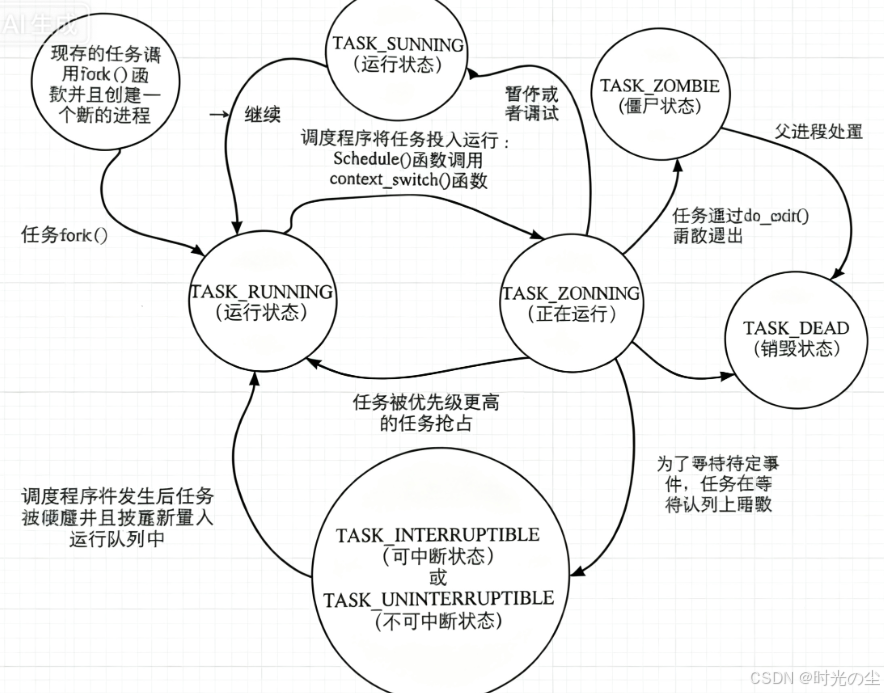
4. 进程状态
Linux 内核在task_struct结构体中通过state字段定义进程状态,核心状态包括:
| 状态名称 | 宏定义(内核中) | 含义与特点 |
|---|---|---|
| 运行态 | TASK_RUNNING | 进程要么正在 CPU 上执行,要么在就绪队列等待调度。新进程通过fork()创建后进入此状态;处于可中断 / 不可中断睡眠态的进程,等待的事件发生后会被唤醒回到该状态;停止态的进程 “继续” 后也会回到运行态;还可能被更高优先级进程抢占后暂时离开运行态。 |
| 可中断睡眠态 | TASK_INTERRUPTIBLE | 进程因等待资源(如 I/O、信号量)而暂停,可被信号唤醒(转为就绪态)。 |
| 不可中断睡眠态 | TASK_UNINTERRUPTIBLE | 进程因等待关键资源(如磁盘 I/O)而暂停,不可被信号唤醒(确保资源操作原子性)。 |
| 暂停态 | TASK_STOPPED | 进程被暂停执行(如收到SIGSTOP、SIGTSTP信号),需SIGCONT信号恢复。 |
| 销毁态 | TASK_DEAD | 父进程处理完僵尸进程后,进程最终进入销毁态,相关资源被彻底释放。。 |
| 僵尸态 | EXIT_ZOMBIE | 进程已终止,但父进程未调用wait()系列函数回收其 PCB(保留 PID 和退出状态)。 |
5. 进程调度
就绪队列(Ready Queue),存储所有处于就绪状态的进程,等待被调度执行。当一个进程被创建、从阻塞状态变为就绪状态,或者从运行状态被暂停时,它会被放入就绪队列。
上下文切换(Context Switch),当调度器选择一个新的进程执行时,需要保存当前正在运行进程的上下文(包括 CPU 寄存器的值、程序计数器、栈指针等),并加载新进程的上下文,这个过程就是上下文切换。上下文切换会带来一定的开销,因此高效的调度算法会尽量减少不必要的上下文切换。
进程的调度方法,根据不同的使用场景有多种:
- 先来先服务(First-Come, First-Served,FCFS):按照进程进入就绪队列的先后顺序进行调度,先进入的进程优先获得 CPU 资源。该算法简单易实现,但对于短进程来说可能不太公平,因为长进程可能会占用 CPU 很长时间,导致短进程等待时间过长。例如,有进程 A(运行时间 10ms)和进程 B(运行时间 1ms),若 A 先进入就绪队列,B 需要等待 A 执行完才能执行,B 的等待时间就会较长。
- 短作业优先(Shortest Job First,SJF):从就绪队列中选择预计运行时间最短的进程进行调度。可以分为非抢占式和抢占式(最短剩余时间优先,SRTF)。SJF 能有效减少平均周转时间,但缺点是难以准确预知进程的运行时间,并且可能导致长进程饥饿(长时间得不到调度)。
- 时间片轮转(Round Robin,RR):每个进程被分配一个时间片(如 100ms),在时间片内进程可以占用 CPU 运行。当时间片用完后,即使进程没有执行完毕,也会被暂停并放入就绪队列末尾,等待下一次调度。RR 算法能较好地保证系统的响应时间,适用于分时系统,让多个交互型用户感觉系统在同时为他们服务。
- 优先级调度(Priority Scheduling):为每个进程分配一个优先级,调度器总是选择优先级最高的进程执行。优先级可以根据进程的类型(如系统进程优先级通常较高)、重要程度等因素来确定。该算法可能导致低优先级进程饥饿,因此可以采用动态优先级调整的方式,例如随着等待时间增加,进程优先级逐渐提高。
- 多级反馈队列(Multilevel Feedback Queue):将进程按优先级划分为多个队列,每个队列对应不同的时间片(优先级越高,时间片越短)。新进程首先进入最高优先级队列,获得一个较短的时间片。如果在时间片内没有执行完,就会被移到下一级队列,获得更长的时间片。多级反馈队列算法综合了多种调度算法的优点,能较好地适应不同类型的进程。
在 Linux 操作系统中,采用了完全公平调度器(Completely Fair Scheduler,CFS)作为默认的进程调度器。CFS 基于进程的虚拟运行时间(vruntime)来进行调度,它为每个进程维护一个虚拟运行时间,每次调度时选择虚拟运行时间最短的进程执行,从而实现了公平性。




















 6870
6870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











