





目录
1. 函数简介
strtok 是 C 语言标准库中的字符串分割函数,用于将字符串按照指定的分隔符拆分成多个子字符串(token)。每次调用 strtok 时,它会返回指向下一个标记的指针,这个标记是从字符串中提取出的、不包含任何分隔符的连续字符序列。它是处理文本数据(如 CSV、日志文件等)的常用工具。
2. 函数原型
#include <string.h>
char *strtok(char *str, const char *delimiters);- str:待分割的字符串(首次调用时传入),在后续的调用中,为了继续从上次停止的地方分割剩余的字符串,str 应被设置为 NULL。
- delimiters:分隔符集合(字符串)
- 成功:返回下一个分割出的子字符串的指针
- 结束:当没有更多子字符串时返回 NULL
在使用过程中需要注意一下几点:
① 由于 strtok 会修改原始字符串,使用时需特别小心。会修改原始字符串(将分隔符替换为 \0);
② 内部使用静态变量记录当前分割位置;
③ 在处理连续分割符时,会自动跳过连续的分隔符;
④ 多线程环境中应使用 strtok_r。
3. 用法示例
举一个简单的例子:
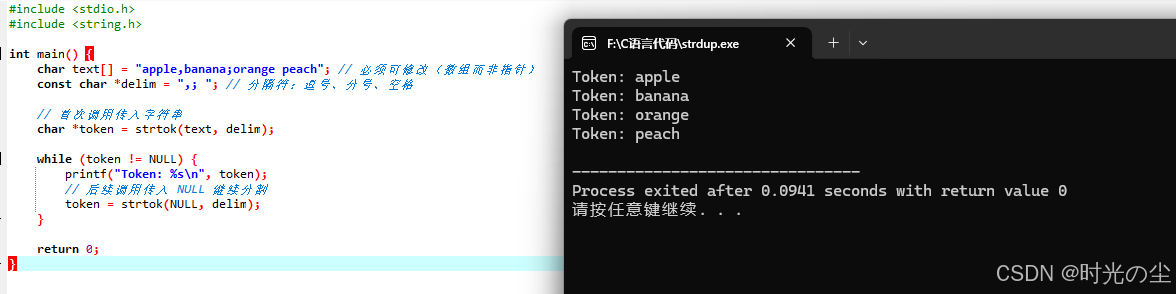
#include <stdio.h>
#include <string.h>
int main() {
char text[] = "apple,banana;orange peach"; // 必须可修改(数组而非指针)
const char *delim = ",; "; // 分隔符:逗号、分号、空格
// 首次调用传入字符串
char *token = strtok(text, delim);
while (token != NULL) {
printf("Token: %s\n", token);
// 后续调用传入 NULL 继续分割
token = strtok(NULL, delim);
}
return 0;
}
工作原理我们来解释一下:
原始字符串: "apple,banana;orange peach"
▲ 初始位置第1次调用: 找到第一个分隔符 ',' 替换为 '\0'
返回 "apple" 的地址
内部指针移动到 'b'第2次调用: 找到 ';' 替换为 '\0'
返回 "banana" 的地址
内部指针移动到 'o'第3次调用: 找到 ' ' 替换为 '\0'
返回 "orange" 地址
内部指针移动到 'p'第4次调用: 到字符串结尾
返回 "peach" 地址第5次调用: 返回 NULL
4. 使用场景
4.1 文本解析(CSV/TSV处理)
解析逗号/制表符分隔的文本数据,高效处理不规则分隔(如连续分隔符),可以使用 strtok 函数将每行数据按逗号分割成多个字段。举个例子:
char line[] = "2023-08-20,42.5,78%,Sunny";
const char *delim = ",";
char *date = strtok(line, delim);
char *temp = strtok(NULL, delim); // 继续分割
char *humidity = strtok(NULL, delim);
char *weather = strtok(NULL, delim);
// 处理各字段
printf("日期: %s, 温度: %s℃\n", date, temp);4.2 命令行参数解析
处理复杂命令行参数(如键值对参数),举个例子,如解析解析-config key1=value1;key2=value2格式:
char args[] = "-config timeout=30;retry=3";
char *config_part = strtok(args, " "); // 先按空格分割
if (config_part && strcmp(config_part, "-config") == 0) {
char *params = strtok(NULL, "");
char *pair = strtok(params, ";"); // 再按分号分割键值对
while (pair) {
char *key = strtok(pair, "=");
char *value = strtok(NULL, "=");
printf("配置项: %s -> %s\n", key, value);
pair = strtok(NULL, ";");
}
}4.3 字符串重构
提取字符串片段重组新字符串,例如在URL提取域名和路径:
char url[] = "https://www.example.com/path/to/page";
strtok(url, "://"); // 跳过协议头
char *domain = strtok(NULL, "/");
char *path = strtok(NULL, ""); // 剩余部分
char new_path[100];
snprintf(new_path, sizeof(new_path), "DOMAIN: %s\nPATH: /%s", domain, path);4.4 日志分析
在处理日志文件时,日志项可能由特定的分隔符分隔(如空格、逗号、制表符等)。strtok 可以用来将这些日志项分割成单独的条目,以便进行进一步的分析或处理。例如分析Nginx日志:
// 示例日志:127.0.0.1 - - [20/Aug/2023:10:12:33] "GET /index.html HTTP/1.1" 200 1532
char log[] = "127.0.0.1 - - [20/Aug/2023:10:12:33] \"GET /index.html HTTP/1.1\" 200 1532";
char *ip = strtok(log, " "); // 客户端IP
strtok(NULL, " ["); // 跳过无用字段
char *time = strtok(NULL, "]"); // 提取时间
strtok(NULL, "\""); // 定位到请求
char *request = strtok(NULL, "\""); // 完整请求
strtok(NULL, " ");
char *status = strtok(NULL, " "); // 状态码
char *size = strtok(NULL, " "); // 响应大小
printf("IP:%s 在 %s 请求 %s\n", ip, time, request);4.5 数据格式转换
不同格式间的数据转换,可以配合配合sprintf实现格式重组,举个例子,将日期格式转换(YYYY-MM-DD → DD/MM/YYYY):
char date[] = "2023-08-20";
char *year = strtok(date, "-");
char *month = strtok(NULL, "-");
char *day = strtok(NULL, "-");
char new_date[20];
sprintf(new_date, "%s/%s/%s", day, month, year); // 20/08/20235. 注意事项
5.1 修改原字符串
strtok 会直接修改原始字符串,将分隔符位置替换为 \0。这种设计虽然节省内存,但会导致原始数据不可逆损坏。举一个错误的示例:
char config[] = "key1=value1;key2=value2";
char *backup = config; // 错误!只是指针复制
strtok(config, ";"); // 原始config已被修改
// 此时backup同样指向被破坏的字符串正确的做法,可以使用 strdup 进行拷贝数据,然后对拷贝的数据进行处理:
char config[] = "key1=value1;key2=value2";
char *copy = strdup(config); // 深度拷贝
if (!copy) { /* 处理内存不足 */ }
// 安全操作副本
strtok(copy, ";");
free(copy); // 记得释放strdup的用法可以参考:
5.2 分隔符的隐蔽陷阱
在使用特殊字符时,最好显示调用,否则可能匹配不到:
// 看似正常的分割
char *token = strtok(path, "/\\"); // 试图匹配/或\
// 但当遇到如下字符串时:
char path[] = "C:\\Program Files/App";
// 实际分割结果可能不符合预期最佳做法:
// 显式定义分隔符集合
const char *DELIMITERS = ",; \t\n\r";
char *token = strtok(input, DELIMITERS);5.3 连续分隔符
保留空字段的方法:
char data[] = "1,,3";
char *results[3];
int count = 0;
char *ptr = data;
while (count < 3) {
results[count] = (*ptr != '\0') ? ptr : "(empty)";
ptr = strtok(ptr, ",");
if (ptr) ptr += strlen(ptr) + 1;
count++;
}
// 结果: ["1", "(empty)", "3"]



















 7694
7694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











