






 本文介绍了一种计算两个句子间相似度的模型,用于解决句子是否为同义句、是否可从另一句推断及是否为答案的问题。模型通过编码、多方式匹配、内部聚合和混合聚合等步骤,最后通过预测层输出类别概率。
本文介绍了一种计算两个句子间相似度的模型,用于解决句子是否为同义句、是否可从另一句推断及是否为答案的问题。模型通过编码、多方式匹配、内部聚合和混合聚合等步骤,最后通过预测层输出类别概率。
1. 问题描述
这是一篇计算两个句子间相似度的文章,用于句子p是否是句子q的另一种表达(paraphrase identification)、句子p是否可以从句子q中推断出(natural language inference)、句子p是否是句子q的答案(Answer Sentence Selection)的问题中。在上述三方面都做了实验,如下图所示:

2. 以前的解决方法几创新点
阶段一,分别对两个句子encode后生成每个句子的representation,利用这两个representation求相似度;阶段二,在句子层面加入attention;阶段三,在word层面加入attention;本文在word层面的attention使用四种attention的结合,分别为concatenated、bilinear、element-wise dot product and difference这四种。

3. 框架描述
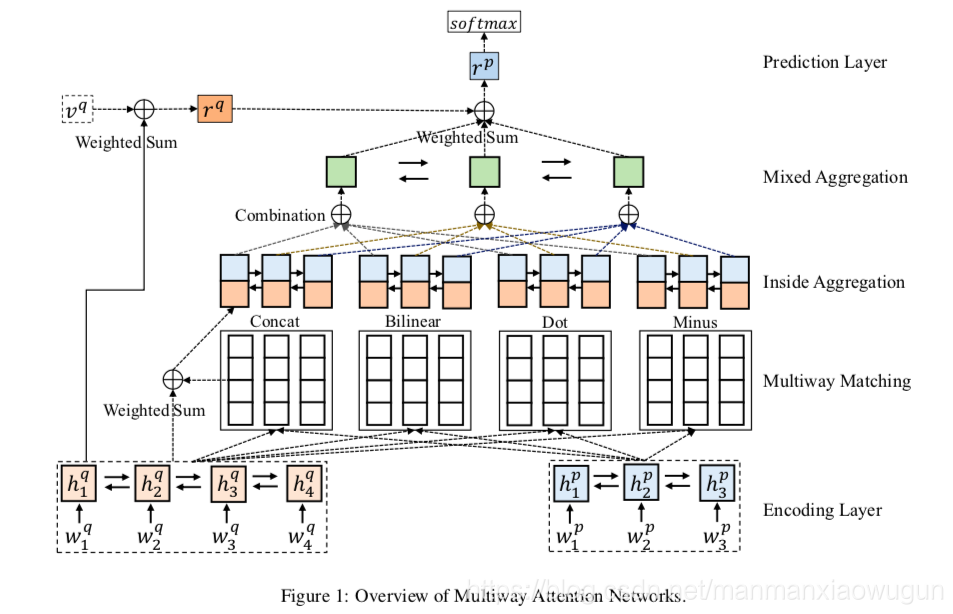
将描述和图结合、再对应上原文中的公式观感更佳哦。
encoding layer: 将句子p和句子q分别放入单层双向rnn中做encoding。
multiway matching:分别用四种attention做,拿一种attention举例(concat),将句子p某时刻的hidden state和句子q所有时刻的hidden state求相似性,对相似度做softmax后得到句子q所有时刻的hidden state的权重,按权重相加得到句子p某时刻的representation。
inside aggregation:分别用四种attention做,拿一种attention举例(concat),将上层attention后句子p某时刻的representation和句子p某时刻原来的hidden state concat后,作为该时刻单层双向rnn的输入。
mixed aggregation:对于句子p的每一时刻来说,都有来自于四种attention得来的representation,求出这四种representation的权重,按权重相加即为句子p该时刻的representation。
prediction layer:将句子q所有时刻的hidden state求权重,按权重相加得到句子q的representation,将句子q的representation和句子p每时刻的representation求相似性,对相似度做softmax后得到句子p所有时刻的hidden state的权重,按权重相加得到最终pq相结合后的representation。将最终pq相结合后的representation输入到多层全连接后输出属于某一类的概率。
4. 疑问
相似度匹配是怎么应用到squad的数据集中的。

















 3692
3692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









