




 本文详细介绍了Linux自动化运维中的文本测试命令text,包括-a、-o、-n、-z等选项的使用。接着讲解了grep的强大搜索功能,以及sed文本编辑器的d、i、a、p等命令的实践应用。最后,文章深入探讨了awk列编辑器的工作原理、语法格式及各种查询和处理技巧,如按行号、信息、列进行查找和操作。
本文详细介绍了Linux自动化运维中的文本测试命令text,包括-a、-o、-n、-z等选项的使用。接着讲解了grep的强大搜索功能,以及sed文本编辑器的d、i、a、p等命令的实践应用。最后,文章深入探讨了awk列编辑器的工作原理、语法格式及各种查询和处理技巧,如按行号、信息、列进行查找和操作。
1. text测试语句
shell环境中测试条件表达式工具text的使用方法:
test 条件1 [选项] 条件2
[ 条件1 [选项] 条件2 ]
选项:
-a:两个条件都为真
-o:两个条件有一个为真
=:字符串是否相等,若相等返回true
!=:字符串是否不等,若不等返回true
test [选项] 变量
[ [选项] 变量 ]
选项:
-n:字符串的长度非零
-z:字符串的长度是否为零
test file1 [选项] file2
[ file1 [选项] file2]
选项:
-ef:两个文件是否为同一个文件,可用于硬连接。主要判断两个文件是否指向同一个inode(节点)。
-nt:判断文件1是否比文件2新
-ot:判断文件1比是否文件2旧
test [选项] file
[ [选项] file ]
选项:
-b:文件是否块设备文件
-c:文件并且是字符设备文件
-d:文件并且是目录
-e:文件是否存在*
-f:文件是否为正规文件*
-L: 文件是否是一个符号链接(同-h)
这里的test和符号[ ]的作用是一样的,[ ]与内容之间一定要有空格。。
1.1 -a与-o
使用-a选项,两个条件同时成立,输出yes,反之为no。

由此可以测试得-a选项,必须两个条件都为真,结果才为真。
使用-o选项,两个条件中只要有一个选项成立,输出结果就为yes,反之为no。

1.2 -n与-z
两者的作用刚好是相反的:
- -n:如果变量有值则为yes,变量为空为no(判断是否有值)
- -z:如果变量有值则为no,变量为空为yes(判断是否没有值)


1.3 =、!=
=:字符串是否相等,若相等返回true
!=:字符串是否不等,若不等返回true

1.4 -ef、-nt与-ot
两个文件是否为同一个文件,可用于硬连接。主要判断两个文件是否指向同一个i节点,同一个i节点表示对应同一个盘符。

-nt判断文件1是否比文件2新(new)
-ot判断文件1比是否文件2旧(old)

1.5 -b,-c,-d,-e,-f,-L
test [选项] file
[ [选项] file ]
选项:
-b:文件是否块设备文件
-c:文件并且是字符设备文件
-d:文件并且是目录
-e:文件目录是否存在*
-f:文件是否为正规文件*
-L: 文件是否是一个符号链接(同-h)


2.grep搜索
grep:强大的搜索工具
grep [搜索内容] 文件名
grep [搜索内容] 文件名1 文件名2 文件名3 ……
grep -E "[1-9]+" = egrep "[1-9]+" # 使用扩展正则表达式
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
开始做测试,首先建立一个实验文件:

x*y:表示任意多个x后紧跟一个y,中间不能有任何的字符。

x...y:表示x和y之间有3个任意字的符。

xy+:表示y出现1到任意多次。

x??y:表示x出现0-2次

\<x{1}y\>:表示内容为xy的行
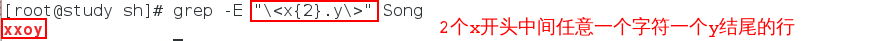
(xy){2}:含有xyxy的行

3.sed文本编辑器
sed:功能强大的流式文本编辑器,他即可以编辑文件,号可以接收改变命令的结果
sed 是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。
处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。
文件内容并没有改变,除非你使用重定向存储输出。
Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
sed '[动作]' 选项 文件名
条件:
d:删除
i:上一行增加
a:下一行增加
p:打印要与选项-n连用有效果
c:替换
w:结果写入其他文件
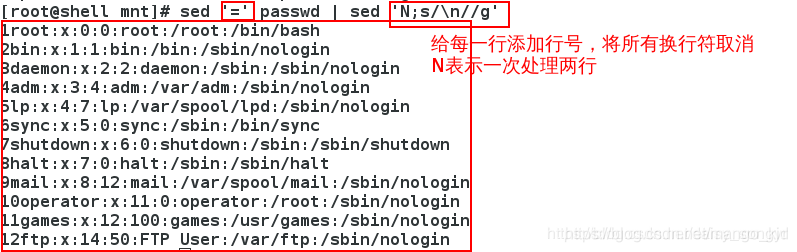
=:前一行添加行号
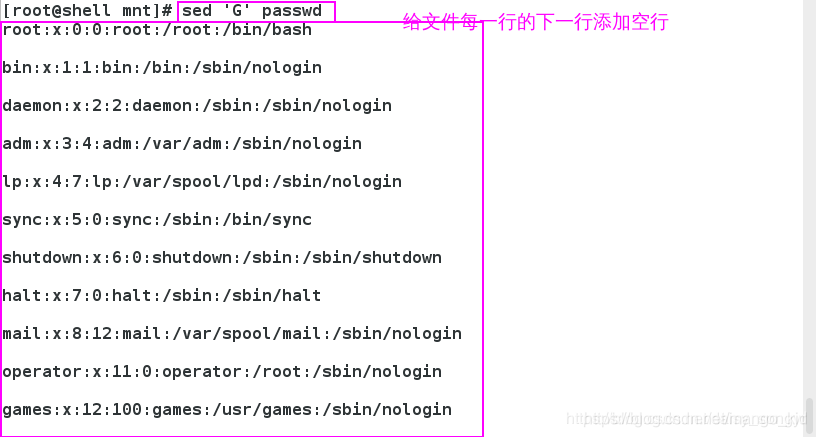
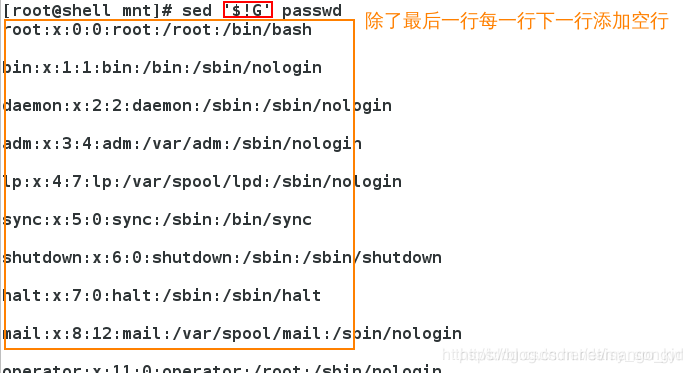
G:下一行添加空行
N:一次处理两行
选项:
-e:与;意思相同,允许执行多条sed命令编辑
-f:使用文件中的条件
-n:只显示指定操作的结果,不加显示全文
-i:用sed修改结果直接该文件中的内容,而不是由屏幕输出。
sed 's/指定内容/替换内容/g' 选项 文件名
sed 's@指定内容@替换内容@g' 选项 文件名
s:行
g:列
我们直接使用fstab的复制文件来进行实验

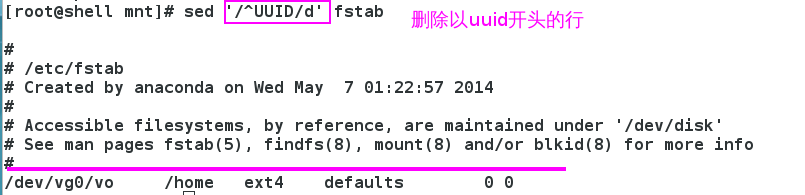
3.1 d
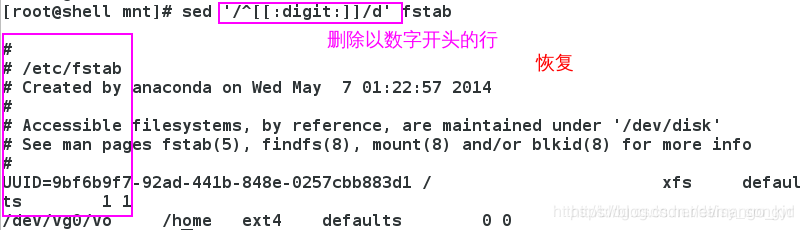
3.1.1 删除指定字符开头行
删除选择的内容,可以给之前添加!表示删除选择内容之外的其他所有。



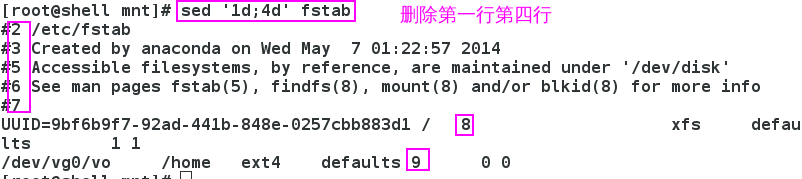
3.1.2 删除指定的行
如果要直接删除指定的行:
1,4d # 删除1-4行
1d;4d # 删除第1行和第4行

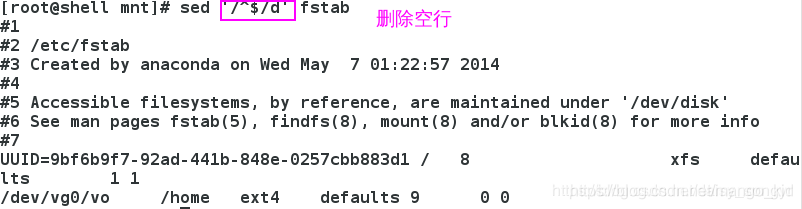
3.1.3 删除空行
/^$/d # ^表示开头,$表示结尾
3.2 i与a
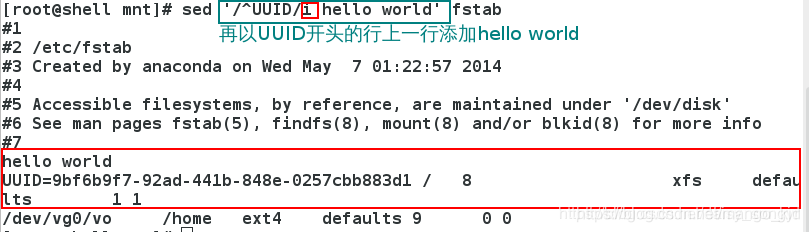
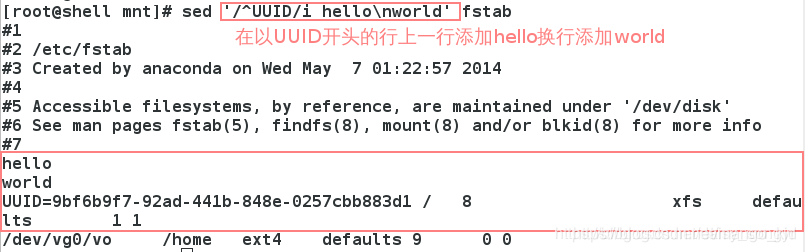
3.2.1 i
i(在当前行上面插入文本)动作模式
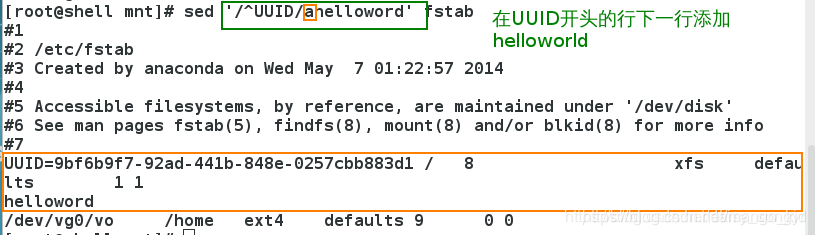
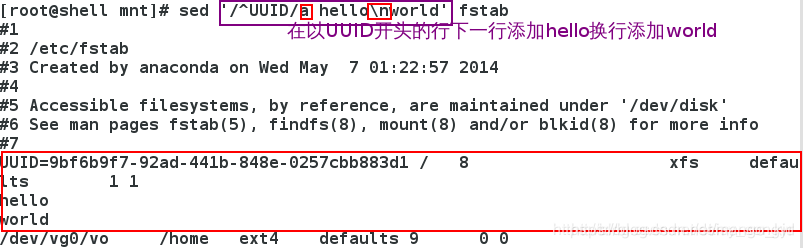
3.2.2 a
a(在当前行下面添加文本)动作
3.3 p
p打印模式,打印模式下要使用-n选项,不使用-n结果会显示出全文,打印指定行 就没有意义了。
3.3.1 打印指定字符开头行


如果不加-n选项。
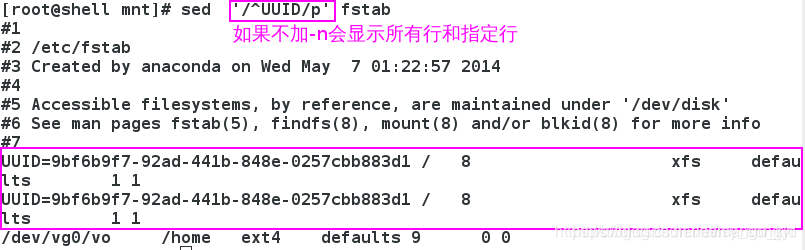
3.3.2 打印指定行


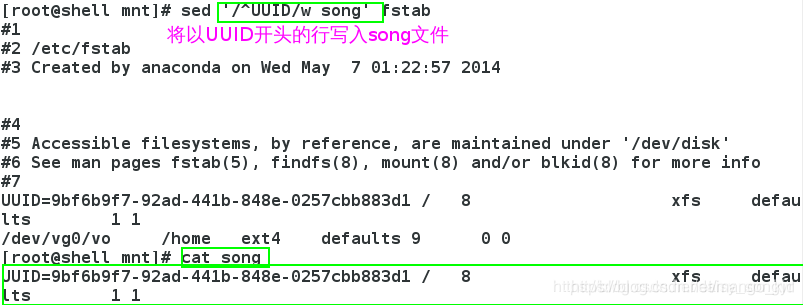
3.4 w
将检索出来的行保存在指定的文件中。

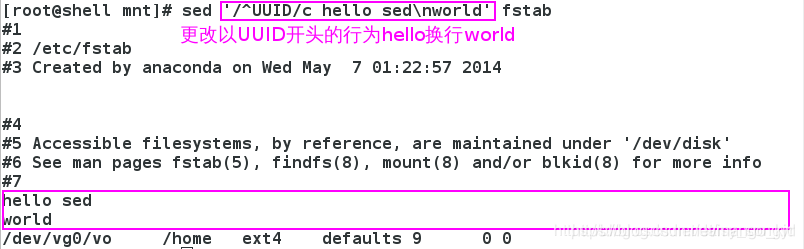
3.5 c
替换一行的内容。
3.6 =
给指定行前一行添加行号。
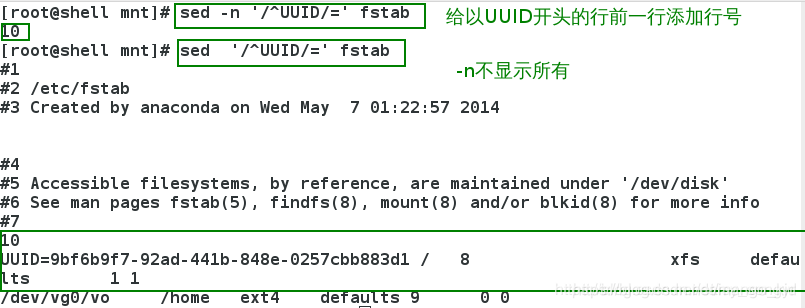
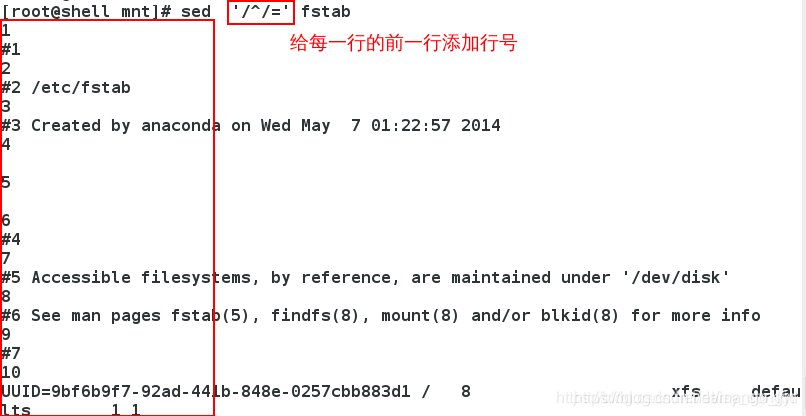
给每一行添加行号:
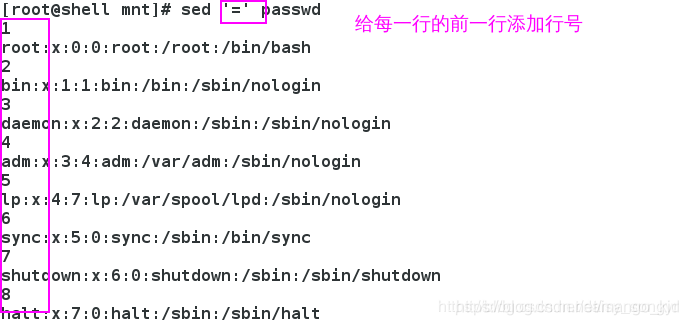
如果多次添加了行号,可以使用删除数次开头行的方式恢复。

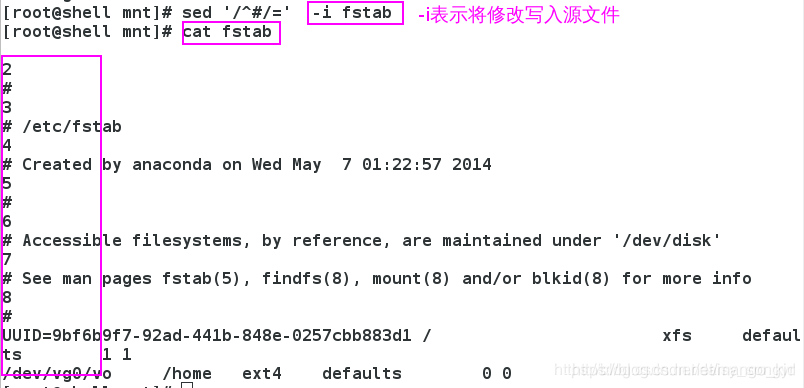
3.7 -i
这样就可以将你的修改写入源文件中。
3.8 -e
-e代表;的作用,你可以在以条命令中匹配多个选定内容。


3.9 -f
使用条件文件来修改指定文件。

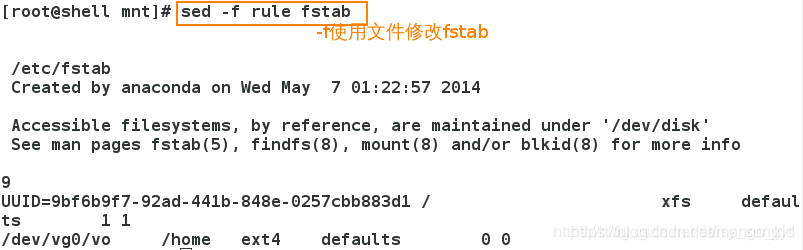
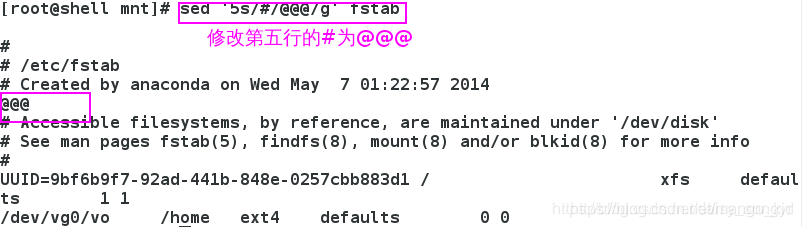
3.10 / @
也可以像vim中的方式,来使用sed选择:
3.10.1 所有行所有列
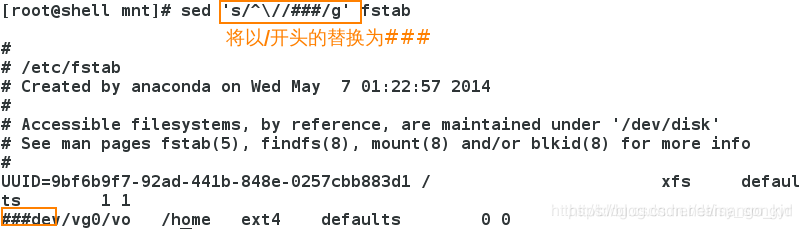

3.10.2 没有g表示第一列

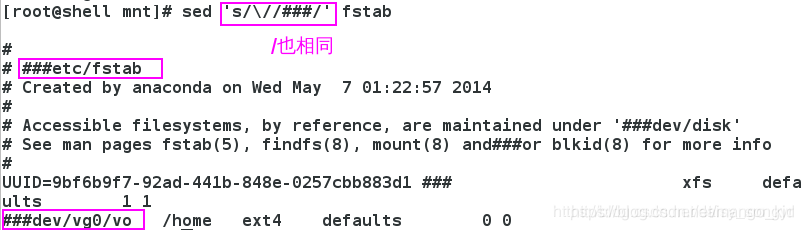
3.10.3 指定行
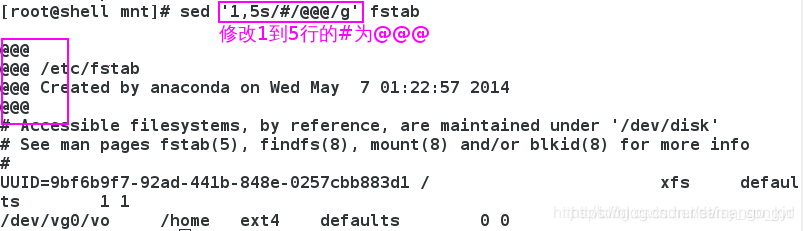
3.11 G
给指定的行加空行:

3.12 N
一次处理两行:
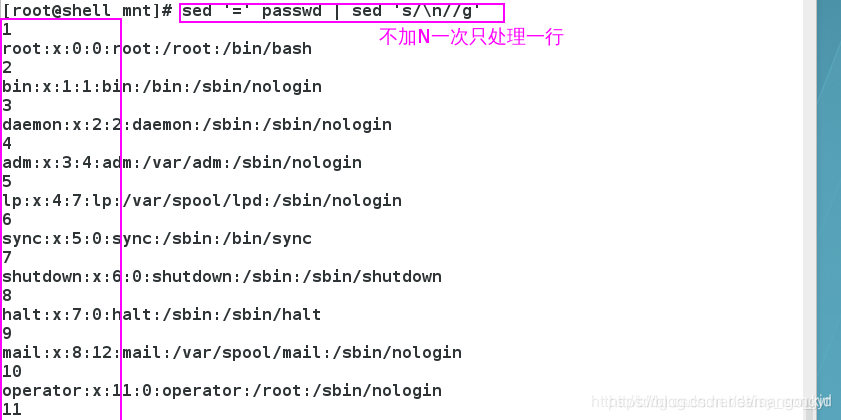
4.awk
4.1 什么是awk
在linux中查找到awk的全称是gawk:

他是awk的GNU版本。
我们通过man查看这个命令的说明:

这就是比较
4.2 awk的工作
awk主要是用来处理文件的,他主要是用来处理日志文件。配置文件通常使用sed命令来处理,因为sed可以使用-i选项将内存中的数据直接保存进磁盘里,改变配置文件,awk和grep都没有这个功能。
awk处理文件的方式主要有:
- 排除信息
- 查询信息
- 统计信息
- 替换信息(输出的信息被替换,源文件不变)
4.3 执行原理
对一个文件进行awk操作就是:
- 将这个文件一行一行的读取,直到读取到最后一行。
- 读取的时候进行判断,是否是需要的信息。
- 匹配条件,对满足的行进行处理执行的动作。
- 不满足就开始读取下一行。
4.4 语法格式
awk [参数] '模式-动作' 文件
参数:
-F 设定分割符
awk中的正则:
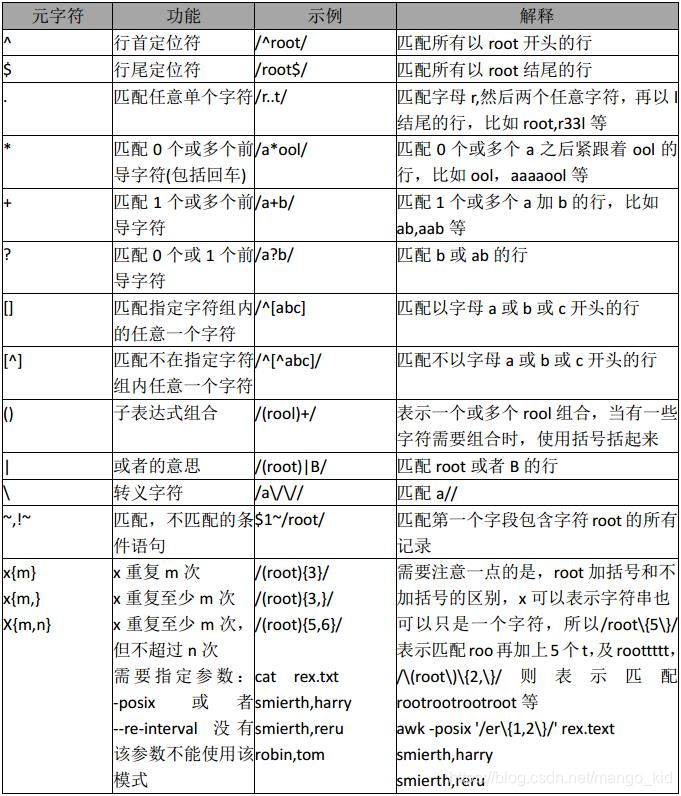
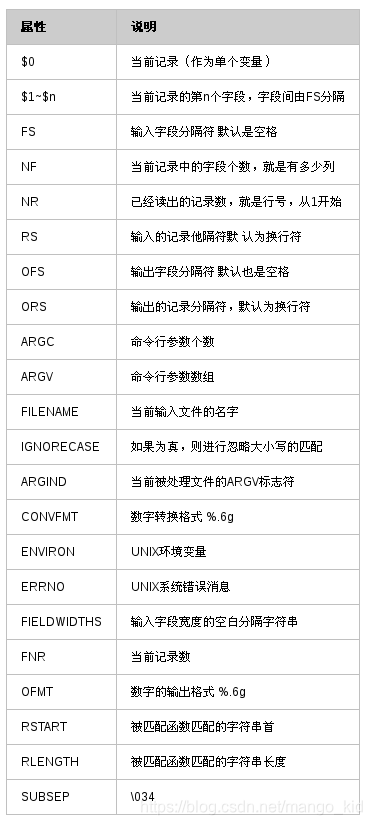
awk中的内置变量:
4.3.1 按照行号查询信息
显示文件的第二行
awk 'NR==2' 文件

显示文件的第二行到第四行:
awk 'NR==2,NR==4' 文件
awk 'NR>=2&&NR<=4' 文件


显示文件的第二行和第四行 :
awk 'NR==2;NR==4' 文件
awk 'NR==2||NR==4' 文件


查询文件一共有几行:
awk '{print NR}' 文件

4.3.2 按照信息查询
查询一个关键信息:
awk '/关键信息1/' 文件

查询一个关键信息到另一个关键信息中间所有的行:
awk '/关键信息1/,/关键信息2/' 文件

查询一个关键信息和另一个关键信息:
awk '/关键信息1/;/关键信息2/' 文件

打印查询到关键字行的第一列:
awk -F : '/bash/{print $1}' 文件
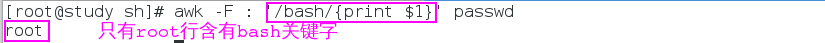
4.3.3 按照列进行查找
以:作为分割符输出第一列。
awk -F : '{print $1}' 文件
 输出第一列和第三列:
输出第一列和第三列:
awk -F : '{print $1"\t"$3}' 文件

输出第一行的第一列和第三列:
awk -F : 'NR==1{print $1"\t"$3}' 文件
awk -F : 'NR==1{print $1,$3}' 文件 # 中间自动分一个空格

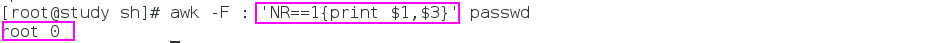
输出含有root关键字的第一列和第三列:
awk -F : '/root/{print $1"\t"$3}' 文件

查询每一行有几列:
awk -F : '{print NF}' 文件

输出第三行的第一列:
awk -F : 'NR==3{print $1}' 文件
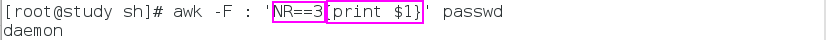
4.3.4 BEGIN END
在命令格式上分别体现如下 :
BEGIN{}:读入第一行文本之前执行,一般用来初始化操作
{}:逐行处理,逐行读入文本执行相应的处理,是最常见的编辑指令
END{}:处理完最后一行文本之后执行 , 一般用来输出处理
我们设定实验每行读取文件开始前打印username,读取完之后打印共有几个用户:
awk -F : 'BEGIN{print "username"}{print $1}END{print NR}' 文件

4.3.5 设定变量n
还可以设定一个变量,让变量在每一行加一给用户编号:
awk -F : 'BEGIN{n=1;print "username"}{print n++,$1}END{print "over"}' 文件

4.3.6 特殊用法
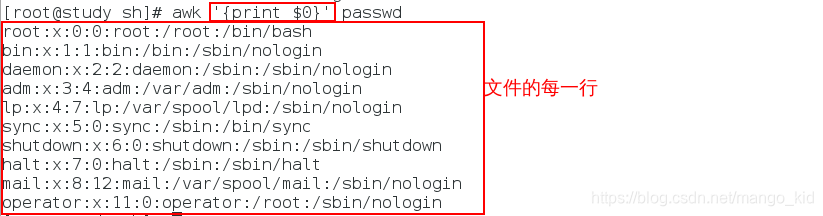
输出每一行:
awk '{print $0}' 文件
计算34+12:
awk 'BEGIN{a=34;print a+12}'

输出以a、b、c或d开头的行:
awk '/^[a-d]/' 文件

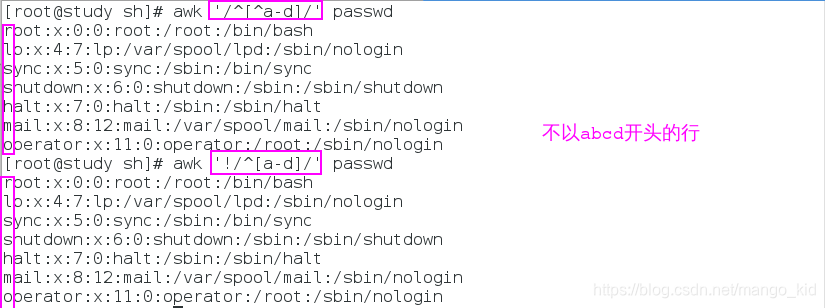
输出不以a、b、c或d开头的行:
awk '/^[^a-d]/' 文件
awk '!/^[a-d]/' 文件
输出以a、b、c或d开头或者以bash结尾的行:
awk '/^[a-d]|bash$/' 文件
awk '/^[a-d]/||/bash$/' 文件

输出以a、b、c或d开头且以bash结尾的行:
awk '/^[a-d]&bash$/' 文件
awk '/^[a-d]/&&/bash$/' 文件

打印第六列以bin结尾的行:
awk -F : '$6~/bin$/' 文件 # $6~:表示文件的第六列匹配正则表达式
awk -F : '$6~/\<bin$/' 文件 # \<the\> 只能匹配单词,就是只能匹配the apple中的the ,不能匹配otherwise中的the

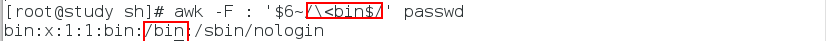
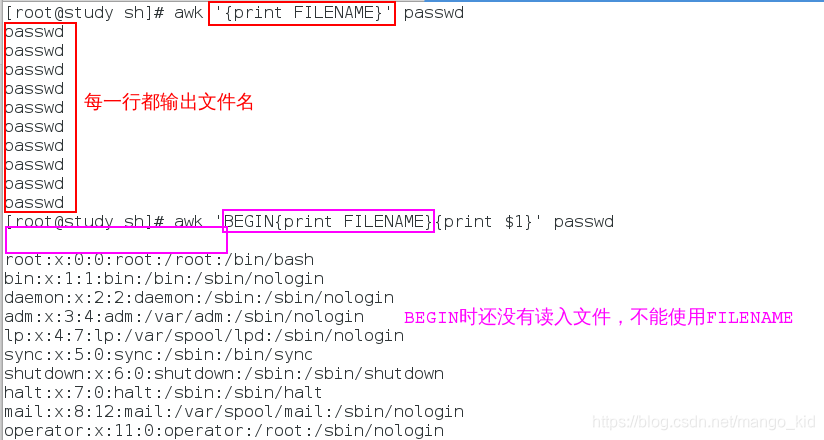
输出文件名:
awk '{print FILENAME}' 文件
awk '{print $1}END{print FILENAME}' 文件


















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









