



pytorch根据开放场景语音文字合成新语音(VoiceLoop)
Song • 2119 次浏览 • 0 个回复 • 2018年01月12日
VoiceLoop
PyTorch实现了VoiceLoop:Voice Fitting and Synthesis via a Phonological Loop的文章中描述的方法。 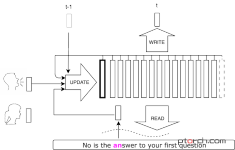
VoiceLoop是一种神经文本到语音(TTS),能够将文本转换为在野外采样的语音。一些演示样本可以在这里找到。
快速链接
快速开始
按照安装程序中的说明进行操作,然后执行:
python generate.py --npz data / vctk / numpy_features_valid / p318_212.npz --spkr 13 --checkpoint models / vctk / bestmodel.pth结果将被放置在models/vctk/results。它会产生2个样本:
- 生成的样本将被保存与
gen_10.wav扩展。 - ground-truth (test)也会生成,并以
orig.wav扩展名保存。
您也可以生成相同的文本,但使用不同的说话者,具体为:
python generate.py --npz data / vctk / numpy_features_valid / p318_212.npz --spkr 18 --checkpoint models / vctk / bestmodel.pth这将生成以下示例。
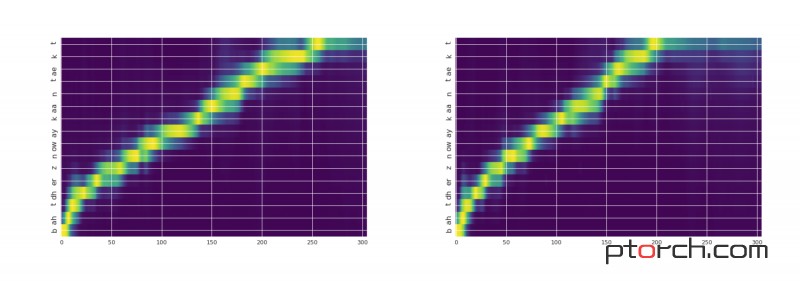
这是相应的图片:
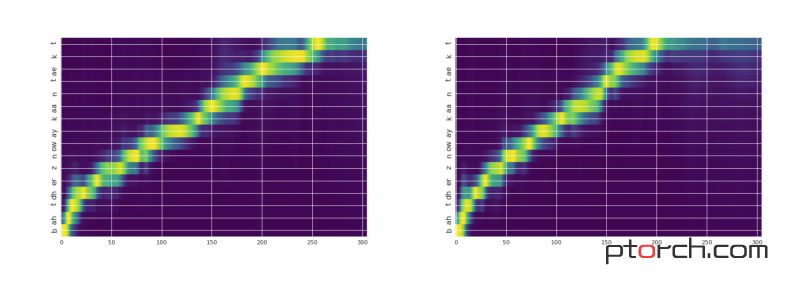
图例:X轴是输出时间(声音样本)输入Y轴(文本/音素)。左图是扬声器10,右图是扬声器14。
最后,还支持自由文本:
python generate.py --text “ hello world ”-- spkr 1 --checkpoint models / vctk / bestmodel.pth建立
要求:Linux/OSX,Python2.7和PyTorch 0.1.12。Generation需要安装phonemizer,请按照设置说明那里。当前版本的培训代码需要对CUDA的支持。Generation可以在CPU上运行。
git clone https://github.com/facebookresearch/loop.git
cd loop
pip install -r scripts/requirements.txt数据
用于训练的模型数据可以通过以下方式下载:
bash scripts/download_data.sh该脚本下载并预处理VCTK的一个子集。这个子集包含美国口音的发言者。
使用Merlin对数据集进行预处理- 从每个音频片段中使用WORLD声码器提取声码器特征。下载后,数据集将位于data子文件夹下,如下所示:
loop
├── data
└── vctk
├── norm_info
│ ├── norm.dat
├── numpy_feautres
│ ├── p294_001.npz
│ ├── p294_002.npz
│ └── ...
└── numpy_features_valid可以使用Kyle Kastner的以下脚本执行预处理管道:https://gist.github.com/kastnerkyle/cc0ac48d34860c5bb3f9112f4d9a0300。
预训练模型
Pretrainde模型可以通过以下途径下载:
bash scripts/download_models.sh下载后,模型将位于models子文件夹下,如下所示:
loop
├── data
├── models
├── blizzard
├── vctk
│ ├── args.pth
│ └── bestmodel.pth
└── vctk_alt更新于10/25/2017:单个speaker模型可在models/blizzard/
SPTK和WORLD
最后,语音生成需要在Merlin中完成SPTK3.9和WORLD声码器。要下载可执行文件:
bash scripts/download_tools.sh其结果如下子目录:
loop
├── data
├── models
├── tools
├── SPTK-3.9
└── WORLD训练
单喇叭
单一的扬声器模型是在blizzard 2011。数据应该如上所述下载和准备。数据准备就绪后,运行:
python train.py --noise 1 --expName blizzard_init --seq-len 1600 --max-seq-len 1600 --data data / blizzard --nspk 1 --lr 1e-5 --epochs 10然后,继续训练模型:
python train.py --noise 1 --expName blizzard --seq-len 1600 --max-seq-len 1600 --data data / blizzard --nspk 1 --lr 1e-4 --checkpoint checkpoints / blizzard_init / bestmodel .pth --epochs 90多音箱
在vctk上训练一个新的模型,首先使用4的噪声等级训练模型,输入序列长度为100:
python train.py --expName vctk --data data / vctk --noise 4 --seq-len 100 --epochs 90然后,继续使用2的噪音水平对全模型进行训练:
python train.py --noise 1 --expName blizzard --seq-len 1600 --max-seq-len 1600 --data data/blizzard --nspk 1 --lr 1e-4 --checkpoint checkpoints/blizzard_init/bestmodel.pth --epochs 90引文
如果你发现这个代码在你的研究中有用,那么请引用:
@article{taigman2017voice,
title = {VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop},
author = {Taigman, Yaniv and Wolf, Lior and Polyak, Adam and Nachmani, Eliya},
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprinttype = {arxiv},
eprint = {1705.03122},
primaryClass = "cs.CL",
year = {2017}
month = October,
}许可证
Loop有CC-BY-NC许可证。
原创文章,转载请注明 :pytorch根据开放场景语音文字合成新语音(VoiceLoop) - pytorch中文网
原文出处: https://www.ptorch.com/news/108.html
问题交流群 :168117787

















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









