




 本文介绍SQL查询优化的方法,包括关联查询、子查询、排序优化等方面的内容,并提供了具体的实践案例。
本文介绍SQL查询优化的方法,包括关联查询、子查询、排序优化等方面的内容,并提供了具体的实践案例。
关联查询的优化(都可以自己去实验一下)
数据准备
#分类
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
分类表中添加20条数据,将下面的SQL语句执行20次。
#向分类表中添加20条记录
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
在想课程表中插入20条数据,将下面的SQL语句执行20次。
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
采取左(右)外连接的方式
没加索引的情况下,驱动表和被驱动表都是全表扫描。
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

给被驱动表的条件字段添加索引。
CREATE INDEX Y ON book(card);

采用内连接
结论:对于内连接来说,查询优化器可以决定谁作为驱动表,谁作为被驱动表,查询优化器会在其中选择一个花费少的。
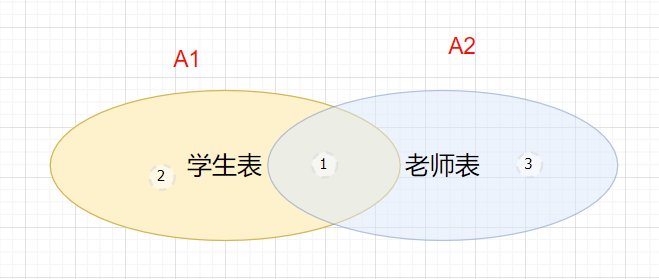
结论1:对于内连接来说,如果表的连接条件只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表出现。
向type表中添加20条数据
结论2:对于内连接来说,在两个表都存在索引的情况下,会选择数据量小的表作为驱动表“小表驱动大表(小表作为驱动表,大表作为被驱动表)
- 一开始都不加索引。
EXPLAIN SELECT SQL_NO_CACHE
* FROM `type` INNER JOIN book
ON type.`card` = book.`card`;
注意到下面的顺序是book是驱动表,type是被驱动表。

- 给book表上的
card字段添加上索引之后
CREATE INDEX Y ON book(card);

book表从驱动表变成了被驱动表。查询优化器在这里做了优化。

子查询优化
MySQL从4.1版本开始支持子查询,使用子查询可以进行SELECT语句的嵌套查询,即一个SELECT查询的结果作为另一个SELECT语句的条件。子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作。
**子查询是MySQL的一项重要的功能,可以帮助我们通过一个sQL语句实现比较复杂的查询。但是,子查询的执行效率不高。**原因:
- 执行子查询时,MySQL需要为内层查询语句的查询结果
建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询 - 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都
不会存在索引,所以查询性能会受到一定的影响。 - 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
举例1:查询班长的信息
- 子查询情况
EXPLAIN SELECT * FROM student stu1
WHERE stu1.`stuno` IN (
SELECT monitor
FROM class c
WHERE monitor IS NOT NULL
);
- 推荐:使用多表连接查询
EXPLAIN SELECT * FROM student stu1
JOIN class c
ON stu1.stuno=c.monitor
WHERE c.monitor IS NOT NULL;
举例2:取所有不为班长的同学
- 不推荐子查询格式
EXPLAIN SELECT SQL_NO_CACHE a.*
FROM student a
WHERE a.stuno NOT IN (
SELECT monitor FROM class b
WHERE monitor IS NOT NULL);
- 推荐,换成多表连接查询
EXPLAIN SELECT SQL_NO_CACHE a.*
FROM student a LEFT JOIN class c
ON a.stuno = c.monitor
WHERE c.monitor IS NULL;
结论:尽量不要使用
NOT IN或者NOT EXISTS,用LEFT JOIN xxx ON xxx WHERE xx IS NULL替代
排序优化
这下面的测试是基于50w条记录的表,数据量不同可能结果会不一样。
排序优化
**问题:**在WHERE条件字段上加索引,但是为什么在ORDER BY字段上还要加索引呢?
回答:
在MySQL中,支持两种排序方式,分别是**FileSort和Index**排序。
- **
Index**排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高。 - **
FileSort**排序则一般在内存中进行排序,占用CPU 较多。如果待排结果较大,会产生临时文件I/O到磁盘进行排序的情况,效率较低。
优化建议:
- SQL中,可以在WHERE子句和ORDER BY字句中使用索引,目的是在WHERE子句中
避免全表扫描,在ORDER BY字句避免使用FilteSort排序。当然某些情况下全表扫描,或者FileSort排序不一定比索引慢。但是总的来说,我们还是要避免,以提高查询效率。 - 尽量使用
Index完成ORDER BY排序。如果WHERE和ORDER BY后面是相同的列就使用单索引列;如果不同就使用联合索引。 - 无法使用Index时,需要对FilteSort方式进行调优
测试
- 删除student和class表中的非主键索引。
call proc_drop_index('atguigudb2','student');
CALL proc_drop_index('atguigudb2','class');
- 没有任何的索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;

- 添加索引
CREATE INDEX idx_age_classid_name ON student (age,classid,NAME);
- 不限制索引失效,数据量太大查询优化器用二级索引去查,找到主键值之后,在去回表操作,花费可能还比文件排序要大,所有干脆就不用索引了。
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;

- 添加条件限制
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid LIMIT 10;

过程三:order by时顺序错误,索引失效
以下哪些索引失效?
再到student表上创建索引
CREATE INDEX idx_age_classid_stuno ON student (age,classid,stuno);
总共两个索引。


EXPLAIN SELECT * FROM student ORDER BY classid LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY classid,NAME LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age,classid,stuno LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age,classid LIMIT 10;
EXPLAIN SELECT * FROM student ORDER BY age LIMIT 10;
过程四:order by时规则不一致,索引失效(顺序错,不索引;方向反,不索引,顺序要都一样,要反着就都反着)
索引失效,你age是按照降序排列的,而classid按升序排列的,查询优化器认为花费比文件排序大,所以,索引失效了
# 索引失效,你age是按照降序排列的,而classid按升序排列的,
# 查询优化器认为花费比文件排序大,所以,索引失效了
EXPLAIN SELECT * FROM student ORDER BY age DESC, classid ASC LIMIT 10;

失效,最左前缀原则,最左边的age没有,索引失效。
EXPLAIN SELECT * FROM student ORDER BY classid DESC, NAME DESC LIMIT 10;
失效,参考上上个。
EXPLAIN SELECT * FROM student ORDER BY age ASC,classid DESC LIMIT 10;
没有失效,直接两个字段都倒过来排序。
EXPLAIN SELECT * FROM student ORDER BY age DESC, classid DESC LIMIT 10;

过程五:无过滤,不索引
只在where字段用到了索引,查完之后,再排序比较费事,就没有用索引了。
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid;

和上面那个一样。
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid,NAME;

用不上索引,数据量太大了,索引失效。
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age;
索引生效,这里可能是查询优化器帮我把order by和where的条件换了,就用了索引。
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age LIMIT 10;

小结
INDEX a_b_c(a,b,c)
order by 能使用索引最左前缀
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by 能使用索引
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b = const ORDER BY c
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b > const ORDER BY b,c
不能使用索引进行排序
- ORDER BY a ASC,b DESC,c DESC /* 排序不一致 */
- WHERE g = const ORDER BY b,c /*丢失a索引*/
- WHERE a = const ORDER BY c /*丢失b索引*/
- WHERE a = const ORDER BY a,d /*d不是索引的一部分*/
- WHERE a in (...) ORDER BY b,c /*对于排序来说,多个相等条件也是范围查询*/
案例实战
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序。执行案例前先清除student上的索引,只留主键:
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid_stuno ON student;
DROP INDEX idx_age_classid_name ON student;
#或者
call proc_drop_index('atguigudb2','student');
场景:查询年龄为30岁的,且学生编号小于101000的学生,按用户名称排序
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;

结论:type 是 ALL,即最坏的情况。Extra 里还出现了 Using filesort,也是最坏的情况。优化是必须
的。
优化思路:
方案一: 为了去掉filesort我们可以把索引建成idx_age_name(age,NAME)
#创建新索引
CREATE INDEX idx_age_name ON student(age,NAME);
再去查询
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE age = 30 AND stuno <101000 ORDER BY NAME ;

执行时间
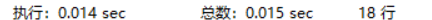
这样就优化了filesort
方案二:给age、stuno、name创建联合索引
虽然extra还是filesort,这是因为使用age和stuno作为条件过滤已经过滤掉大部分数据了,就没有必要再回表操作了。
CREATE INDEX idx_age_stuno_name ON student(age,stuno,NAME);

执行时间
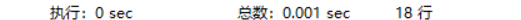
结果竟然有filesort的sql运行速度,超过了已经优化掉 filesort的 sql,而且快了很多,几乎一瞬间就出现了结果。
原因:
所有的排序都是在条件过滤之后才执行的。所以,如果条件过滤掉大部分数据的话,剩下几百几千条数据进行排序其实并不是很消耗性能,即使索引优化了排序,但实际提升性能很有限。相对的stuno<101000这个条件,如果没有用到索引的话,要对几万条的数据进行扫描,这是非常消耗性能的,所以索引放在这个字段上性价比最高,是最优选择。
结论:
- 两个索引同时存在,mysql自动选择最优的方案。(对于这个例子,mysql选择
idx_age_stuno_name)。但是, 随着数据量的变化,选择的索引也会随之变化的 。- 当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段
上。反之,亦然。

















 2812
2812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









