




MySQL索引的数据结构
为什么使用索引
索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本教课书的目录部分,通过目录中找到对应文章的页码,便可快速定位到需要的文章。MySQL中也是一样的道理,进行数据查找时,首先查看查询条件是否命中某条索引,符合则通过索引查找相关数据,如果不符合则需要全表扫描,即需要一条一条地查找记录,直到找到与条件符合的记录。
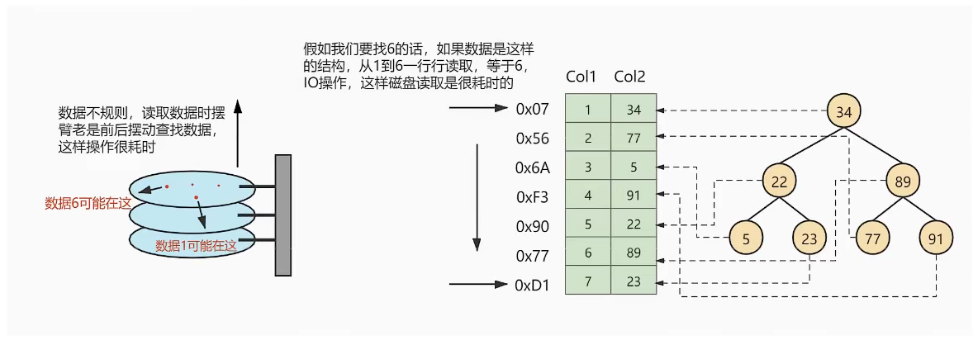
如上图所示,数据库没有索引的情况下,数据分布在硬盘不同的位置上面,读取数据时,摆臂需要前后摆动查找数据,这样操作非常消耗时间。如果数据顺序摆放,那么也需要从1到6行按顺序读取,这样就相当于进行了6次IO操作,依旧非常耗时。如果我们不借助任何索引结构帮助我们快速定位数据的话,我们查找Col2=89这条记录,就要逐行去查找、去比较。从Col2=34开始,进行比较,发现不是,继续下一行。我们当前的表只有不到10行数据,但如果表很大的话,有上千万条数据,就意味着要做很多很多次磁盘I/O才能找到。现在要查找Col2=89这条记录。CPU必须先去磁盘查找这条记录,找到之后加载到内存,再对数据进行处理。这个过程最耗时间的就是磁盘I/O(涉及到磁盘的旋转时间(速度较快)、磁头的寻道时间(速度慢费时))假如给数据使用二叉树这样的数据结构进行存储,如下图所示
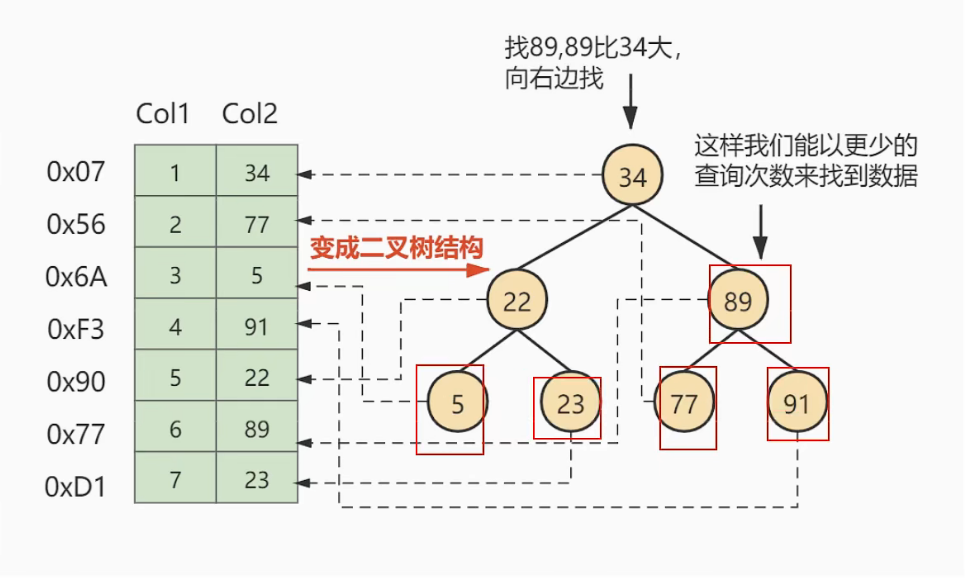
对字段Col 2添加了索引,就相当于在硬盘上为Col 2维护了一个索引的数据结构,即这个二叉搜索树。二叉搜索树的每个结点存储的是(K,V)结构,key是Col 2,value是该key所在行的文件指针(地址)。比如:该二叉搜索树的根节点就是: (34,0x07)。现在对Col2添加了索引,这时再去查找Col2=89这条记录的时候会先去查找该二叉搜索树(二叉树的遍历查找)。读34到内存,89>34;,继续右侧数据,读89到内存,89 == 89;找到数据返回。找到之后就根据当前结点的value快速定位到要查找的记录对应的地址。我们可以发现,只需要查找两次就可以定位到记录的地址,查询速度就提高了。
这就是我们为什么要建索引,目的就是为了减少磁盘I/0的次数,加快查询速率。
索引及其优缺点
索引概述
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
索引的本质:索引是数据结构。你可以简单理解为“排好序的快速查找数据结构”,满足特定查找算法。这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法。
索引是在存储引擎中实现的,因此每种存储引擎的索引不一定完全相同,并且每种存储引擎不一定支持所有索引类型。同时,存储引擎可以定义每个表的最大索引数和最大索引长度。所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节。有些存储引擎支持更多的索引数和更大的索引长度。
优点
(1)类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本,这也是创建索引最主要的原因。
(2)通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
(3) 在实现数据的参考完整性方面,可以加速表和表之间的连接。换句话说,对于有依赖关系的子表和父表联合查询时,可以提高查询速度。
(4)在使用分组和排序子句进行数据查询时,可以显著减少查询中分组和排序的时间,降低了CPU的消耗。
缺点
增加索引也有许多不利的方面,主要表现在如下几个方面:
(1)创建索引和维护索引要耗费时间,并且随着数据量的增加,所耗费的时间也会增加。
(2)索引需要占磁盘空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,存储在磁盘上,如果有大量的索引,索引文件就可能比数据文件更快达到最大文件尺寸。
(3)虽然索引大大提高了查询速度,同时却会降低更新表的速度。当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。
因此,选择索引时,就需要考虑索引的优点和缺点
提示:
索引可以提高查询的速度,但是会影响插入记录的速度。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









