



某天,小H在公司摸鱼,突然ld发来消息:小H,把这一份文件转换成我们常用的csv方便后续处理。小H一看都蒙圈了,什么c3d文件,根本没有见过,赶紧上网搜索起来。
原来啊,c3d文件通俗解释其作为运动捕捉数据 "容器" 的特性,比如它如何同时存储标记点轨迹(如膝盖、脚踝的三维坐标)、肌电信号(肌肉活动)、测力台数据(地面反作用力)等多类信息。
小H拿到的这份是关于一个步态分析的数据《A multimodal dataset of human gait at different walking speeds》,数据内容如下:
标记点轨迹数据:记录 52 个反光标记点的三维坐标,涵盖全身各部位,用于分析关节运动学。
模拟数据:包括肌电信号、地面反作用力和力矩,反映肌肉活动和力学特征。
力板数据:包含力板中心压力坐标、三维地面反作用力和力矩,用于研究步态动力学。
元数据:存储参与者年龄、性别、体重、身高、腿长等信息,以及脚步事件时间,为数据分析提供背景信息。
那我们要处理出的csv文件就显而易见了,列名就是对应的数据嘛,然后根据不同的数据类型放到不同的文件夹下面。
但是c3d文件到底是长什么样子的呢,小H还是有点好奇的,如果能像文件夹一样可视化看到文件结构就好了,于是上网找到了 VBC3Deditor 这下总算是能够看到文件具体是什么样子的。打开其中的一份文件结构就如下了:
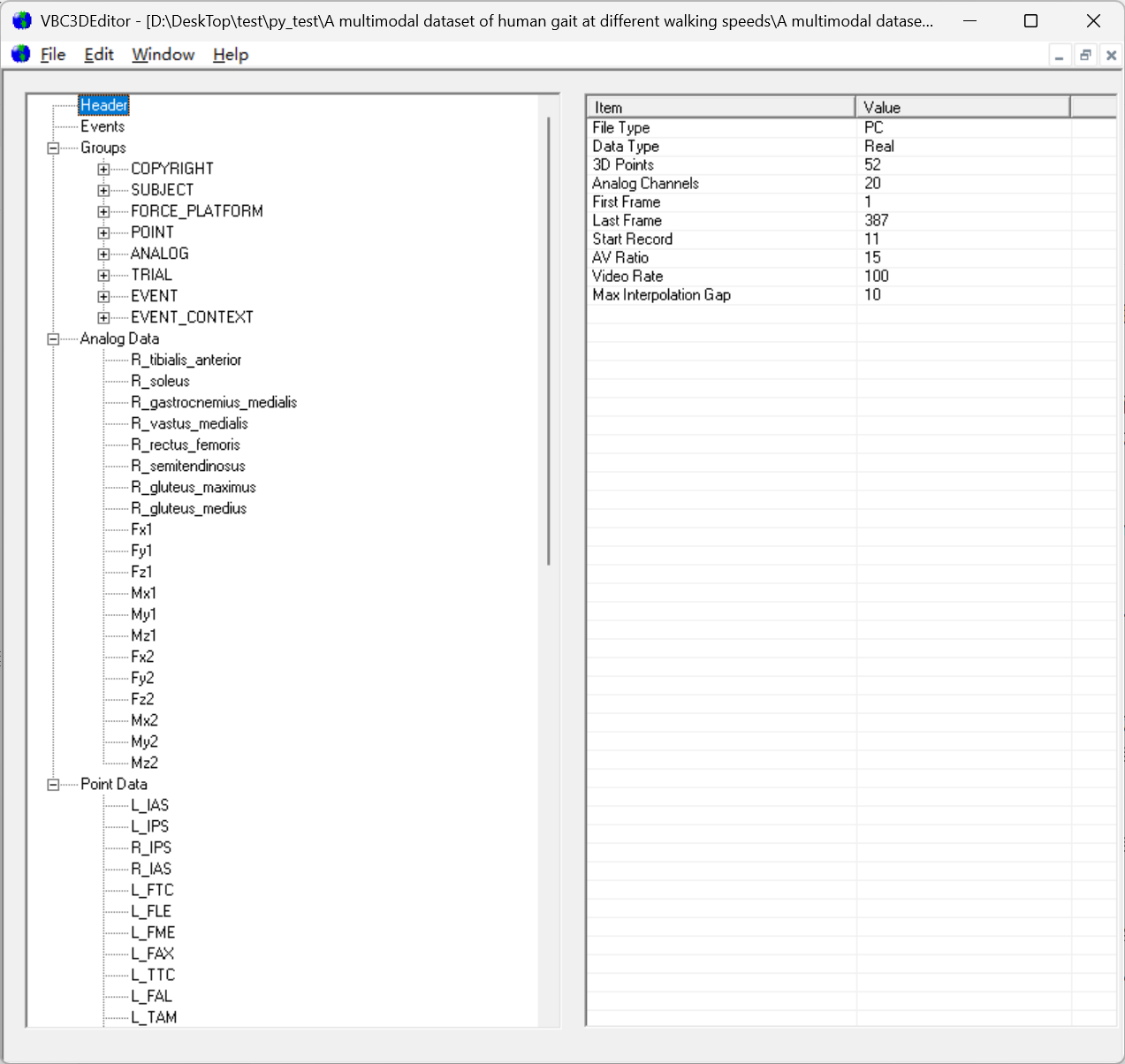
就好像每一个文件夹都有了属性一样,不过这些先不管了,小H决定就交一份数据上去再说,所以上网查找什么东西能够快速帮自己读取c3d文件,然后就找到了python c3d库。
import c3d
with open(file_path, 'rb') as f:
reader = c3d.Reader(f) # 创建读取器对象
很简单的导入库和创建读取器对象,然后要读取什么内容呢?
首先我们关注到这个文件夹有四个大类比,首先看到header。
Header(头信息)
-
含义:C3D 文件的 “元数据总览”,存储整个文件的基础参数,是解析文件的 “钥匙”。
-
包含内容:
-
标记点数量(
point_count)、模拟信号通道数(analog_count); -
标记点帧率(
point_rate,如 100Hz,每秒采集 100 帧标记点); -
模拟信号采样率(
analog_rate,如 1500Hz,力台、肌电等信号的采样频率); -
文件版本、总帧数、数据起始地址等底层格式信息。
-
-
作用:告诉解析工具 “如何解读后续数据”,例如 “有多少个标记点”“每秒钟采集多少帧”。
那我们就看到header里面有什么内容。
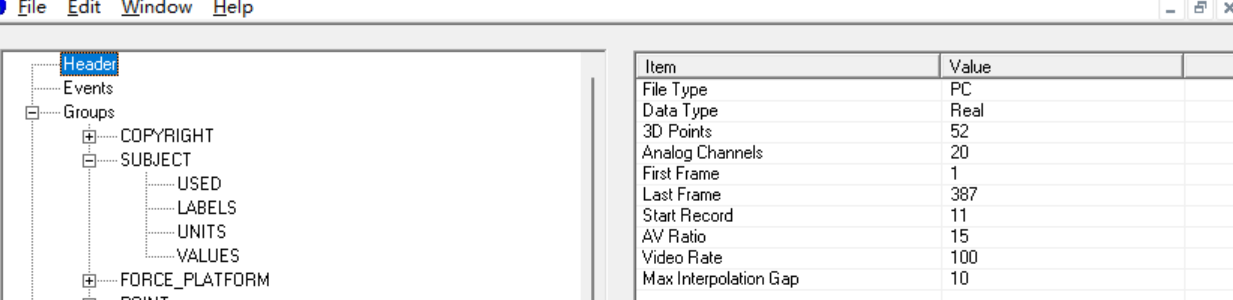
看起来确实是一些参数相关的,可以试着使用reader读取对应的内容。不过我们使用c3d库来进行解析的话有另外一套标准命名,就不能这样直接读取了。
直接使用reader.header就可以看到有什么属性了。
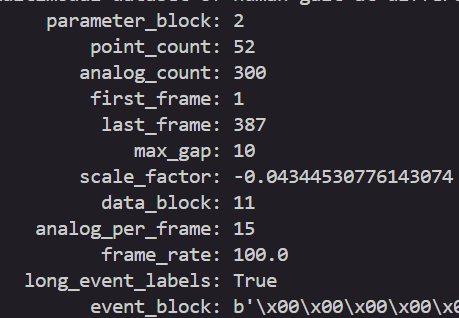
可见他解析的命名和原始的还是有一定区别的,不过基本上都可以对应上,然后根据数据集给出的说明文档,我们首要就是提取标记点数据和模拟数据了,也就是Point和analog。
Point Data(标记点数据)
-
含义:存储运动捕捉中标记点的 3D 空间坐标数据,是文件的核心数据之一。
-
包含内容:
-
每个标记点在每帧的 X、Y、Z 三维坐标(单位通常为毫米);
-
其他
-
Analog Data(模拟信号数据)
-
含义:存储连续采集的模拟信号(非离散标记点),通常与标记点数据同步记录。
-
包含内容:
-
肌电信号(EMG):肌肉活动的电压变化(单位:伏特);
-
力台数据:地面反作用力(Fx、Fy、Fz,单位:牛顿)和力矩(Mx、My、Mz,单位:牛・毫米);
-
其他传感器数据:如加速度计、陀螺仪信号等。
-
对于以上俩种数据,我们使用reader.read_frames()来读取,c3d库在这里返回的是(frame_number, points_array, analog_array) (当然也能没有analog这一列)
for frame_num,points,analog_points in reader.read_frames():
print(frame_num)
print(points.shape)
print(analog_points.shape)
其中一帧输出是 1 (52,5) (20,15) 和文档说明对上了,接下来就按照目录进行解析就可以了,也就是应该有什么列名写入到csv中。
看到我们的points坐标应该是x,y,z三维的,所以只需要前面的3项就可以了,analog我们截取15项,因为采样率是point的15倍,也就是说每个frame应该有15个sample
for frame_info in reader.read_frames():
frame_num = frame_info[0]
points = frame_info[1]
analog_data = frame_info[2]
point_data.append(points[:,:3])
print(frame_num)
print(point_data)
print(analog_data.shape[0])
print(analog_data.shape[1])
这样就可以看到我们完整一帧想要的数据内容有什么了。

后续我们只要使用point_label 和 analog_label就可以得到上述对应的列名了。
到这里基本上任务已经可以完成了,提取出数据之后转换为numpy格式在和平时一样去保存到csv里面就可以了。
小H高高兴兴地把数据都处理完就上传了,但是回过头去看别人给的文档,那么里面应该还有和力平台啊、受测试的人的信息呢?都放在哪里了,那我们文件夹下还有Events和Groups俩个大类好像都没有用到一样。
Events(事件数据)
-
含义:记录运动过程中的关键时间点,用于标记动作的重要阶段。
-
包含内容:
-
事件时间(对应标记点的帧编号或模拟信号的采样点);
-
事件标签(如 “heel_strike” 脚跟着地、“ toe_off ” 脚趾离地、“ stance ” 支撑相、“ swing ” 摆动相);
-
事件类型(如手动标记、自动检测)。
-
-
作用:将原始数据与运动学阶段关联,例如 “第 100 帧是左脚着地时刻”,方便后续分析步态周期。
不过这份文件并没有这部分,在可视化的文件里面没有,或者直接使用reader.events也没有访问到。
Groups(分组信息)
-
含义:对标记点或模拟信号通道进行逻辑分组,便于批量处理同类数据
我们直接使用_groups访问到了group的内容:

基本和可视化软件给出的是一样的,可以清楚看到有SUBJECT和FORCE_PLATFORM这俩个目标内容,那就可以去访问了。
如果存在什么问题可以和我联系。




















 8322
8322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











