



 本文深入探讨了正则表达式的创建方式,包括字面量和构造函数,并详细介绍了正则表达式的基础知识,如修饰符、预定义类、特殊字符等。此外,还讲解了RegExp对象的属性和方法,以及在字符串操作中的应用,如搜索、匹配、替换和分割。文中还提到了正向前瞻和负向前瞻等高级用法,帮助读者全面理解正则表达式的强大功能。
本文深入探讨了正则表达式的创建方式,包括字面量和构造函数,并详细介绍了正则表达式的基础知识,如修饰符、预定义类、特殊字符等。此外,还讲解了RegExp对象的属性和方法,以及在字符串操作中的应用,如搜索、匹配、替换和分割。文中还提到了正向前瞻和负向前瞻等高级用法,帮助读者全面理解正则表达式的强大功能。
正则表达式
创建正则表达式对象
1.字面量创建

2.构造函数创建,使用RegExp对象来封装一个正则表达式

正则表达式基础
1.修饰符
g:global,全文搜索,若不添加,则搜索到第一个匹配即停止。
i:ignore case,忽略大小写,正则表达式是大小写敏感的。
m:multiple lines,多行搜索,搜索时识别换行符。
2.范围类
在[ ]中可以将一些范围连续书写。
3.预定义类,用于快捷的表示一些特定的范围。
. (点),[^\r\n],除了回车符和换行符之外的所有字符。
\d,[0-9],数字字符
\D,[^0-9],非数字字符
\s,[\t\n\x0B\f\r],空白符,\f 换页符,\r 回车符,\t 水平制表符,\n 换行符,\x0b 垂直制表符
\S,[^\t\n\x0b\f\r],非空白符
\w,[a-zA-Z_0-9],单词字符(包括字母、数字和下划线)
\W,[^a-za-z_0-9],非单词字符(除字母、数字和下划线之外的字符)
例如:ab\d. 表示匹配一个"ab+一个数字+一个任意字符"的模式。
^,以 xxx 开始
$,以 xxx 结束
\b,单词边界
\B,非单词边界
?,出现 0 次或 1 次
+,出现 1 次或多次
*,出现 0 次或多次
{n},出现 n 次
{n, m},出现 n 到 m 次
{n,},出现 n 次或更多次
()分组
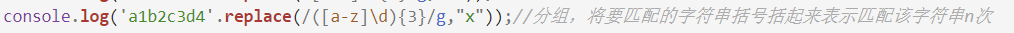
或,使用 | 表示或,表示|左右字符二选一。例如: 比较 Byron|Casper 和 Byr(on|Ca)sper。
反向引用,使用$n的形式引用模式中分组匹配到的文本,例如

忽略分组,当不想捕获分组时,可以使用?:
前瞻,正向前瞻,exp(?=assert),负向前瞻,exp(?!assert)
例如:表达式\w(?=\d),表示匹配到一个单词\w 时还需要向后判断是否为一个数字\d。
RegExp对象属性
global,是否全文搜索,默认 false。
ignoreCase,是否忽略大小写,默认 false。
multiline,是否多行搜索,默认 false。
lastIndex,当前表达式匹配内容的最后一个字符的下一个位置。
source,正则表达式的文本字符串。
RegExp对象方法
test(str),用于测试字符串参数中是否存在匹配正则表达式模式的字符串,返回 true 或 false。
exec(str),使用正则表达式模式对字符串执行搜索,并将更新全部 RegExp 对象的属性以反映匹配结果。
字符串与正则方法
search(reg),用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。返回第一个匹配结果的 index,没有匹配到返回-1。不执行全局匹配。
match(reg),检索字符串以找到一个或多个与 regexp 匹配的文本,未找到返回 null,找到后返回一个数组。与 RegExp 的 exec()方法相同。
split(reg),利用 regexp 匹配结果作为分隔符对字符串进行分割,返回一个数组。
replace(reg, newStr),将 regexp 的匹配结果替换成 newStr,返回一个新字符串。



















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









