






〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生
知识库主页:https://oizxc9sdhbc.feishu.cn/wiki/FGS5wST0Hiy6xJklyPTcTVOqnAd
引言
2025年 7 月,科技巨头与创新力量纷纷发力,一系列令人瞩目的 AI 开源项目接连登场,涵盖了机器人、换脸、多模态生成等多个热门且极具潜力的领域。
本月,我们精心筛选出十二大具有代表性的 AI 开源项目。
从字节跳动的通用机器人“大脑”GR - 3,到阿里发布的高效音频驱动全身动画视频生成技术 OmniAvatar;从英伟达推出的高精度图像和视频局部区域描述生成技术 DAM,到能实现零延迟、实时、无限视频生成的 MirageLSD 等。
这些项目不仅在技术创新上各有千秋,更在实际的行业落地应用中展现出广阔的前景。
接下来,让我们一同深入解析这十二大 AI 开源项目,探寻它们背后的技术奥秘以及可能为各个行业带来的变革与机遇。
一、视频生成与编辑:低成本与实时性的突破
1. PUSA V1.0:500美元超越SOTA的I2V生成技术
技术亮点:通过向量化解耦时序适应(VTA),将标量时间步扩展为向量,实现细粒度时间控制。仅需500美元训练成本(对比Wan-I2V-14B的≥10万美元)和4K数据集(对比≥10M样本),性能却超越后者(VBench-I2V 87.32%)。支持零样本任务如视频扩展、起始/结束帧生成。
项目主页:https://yaofang-liu.github.io/Pusa_Web/

行业应用:低成本影视预告片生成、广告创意快速原型设计。
技术点评:非破坏性微调保留预训练模型能力,避免组合爆炸问题,为中小企业提供高性价比方案。
2. FreeAudio:无需训练的长文本到音频生成
技术亮点:全球首个训练-free的时序控制音频生成框架,通过LLM分解复杂时间提示(如“猫叫0s-24s”)为时间窗口,结合解耦注意力控制和上下文潜在组合,实现高精度音画同步。
项目主页:https://freeaudio.github.io/FreeAudio/
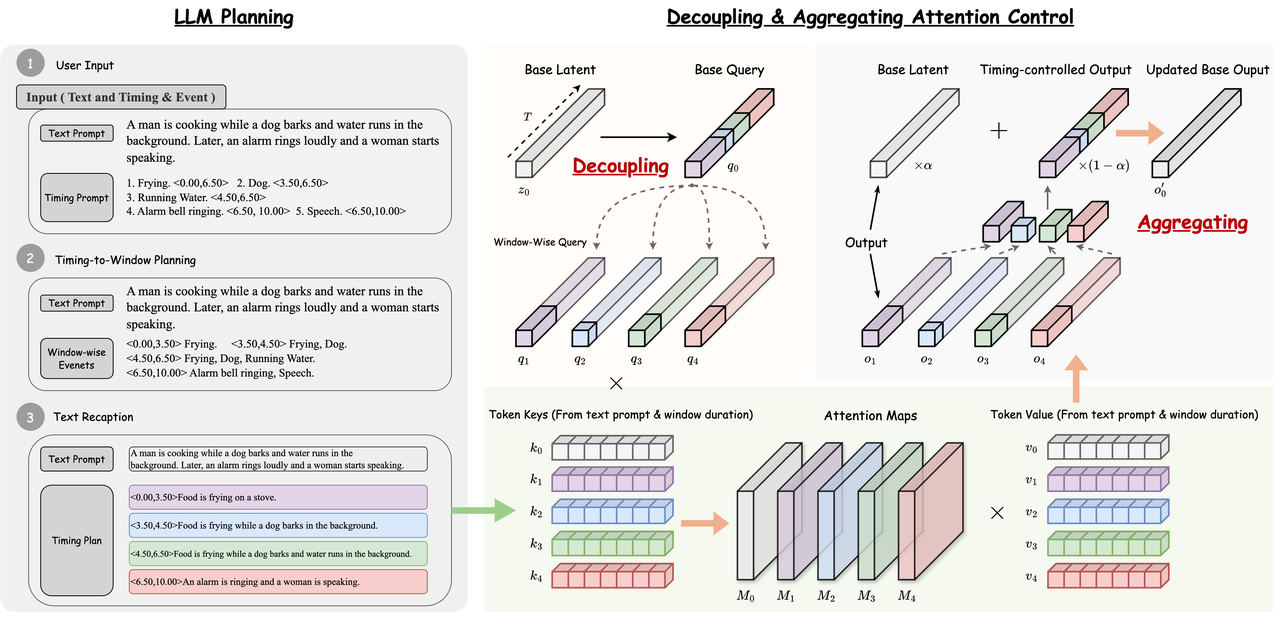
行业应用:有声书制作、游戏背景音乐动态生成。
技术点评:解决长音频生成中时间对齐难题,无需微调即可适配复杂指令,降低创作门槛。
3. MirageLSD:零延迟无限实时视频生成
技术亮点:全球首个实时无限视频流模型,基于Live Stream Diffusion(LSD),每帧生成延迟<40ms(24FPS),支持无限长度内容创作与实时交互编辑(如将棍棒变成光剑)。
项目主页:https://about.decart.ai/publications/mirage
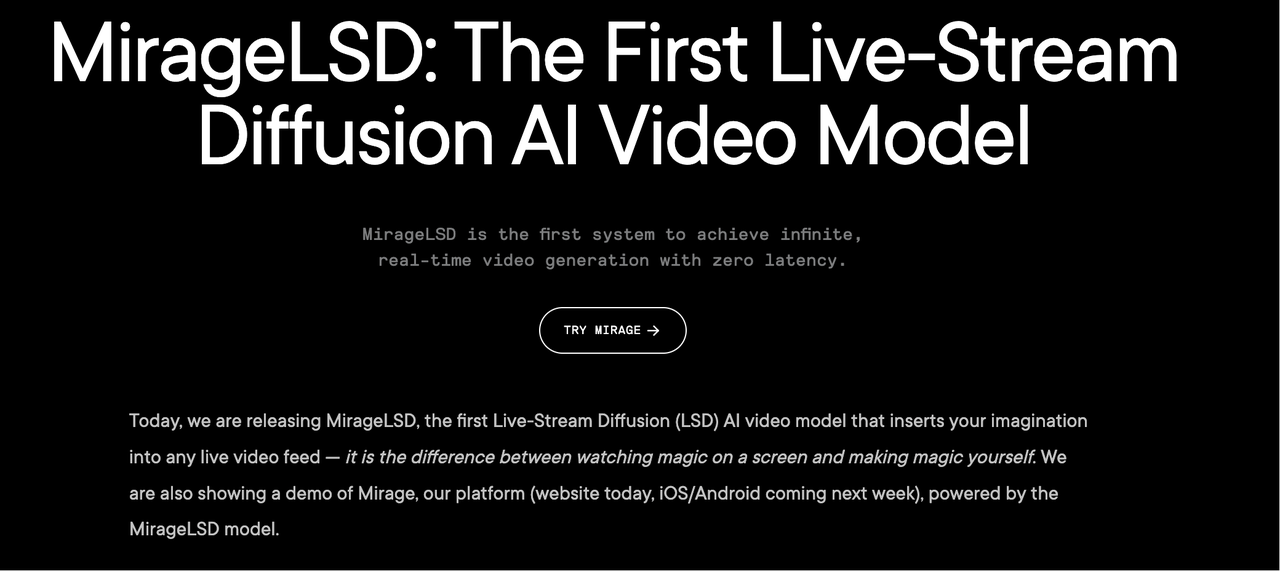
行业应用:直播特效、沉浸式虚拟场景构建。
技术点评:通过历史帧增强训练解决误差累积问题,结合CUDA优化实现低延迟,开启交互式视频生成新范式。
二、多模态生成与理解:精准控制与跨模态协同
4. XVerse:DiT调制实现多主体一致性控制
技术亮点:通过文本流调制偏移量和T-Mod适配器,独立控制多个主体身份(如人脸、动物)及语义属性(姿态、光照),解决传统方法的属性纠缠问题。配套XVerseBench基准测试。
项目主页:https://bytedance.github.io/XVerse/
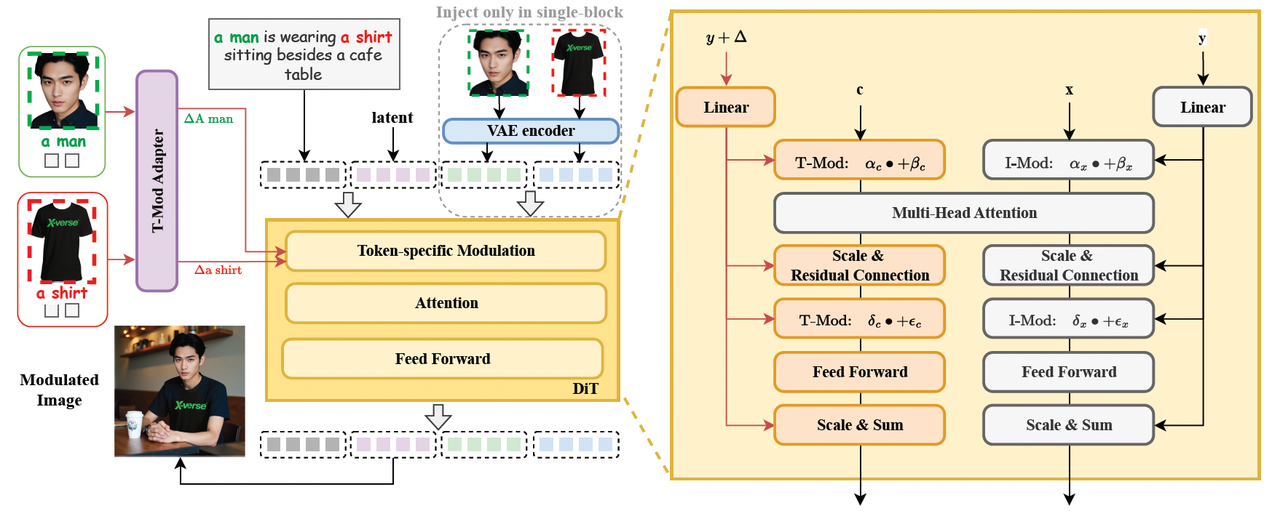
行业应用:影视角色设计、虚拟社交场景生成。
技术点评:Diffusion Transformer的精细化调制能力,为复杂叙事场景提供技术支撑。
5. Qwen VLo:从理解到生成的跨模态模型
技术亮点:多模态统一模型,支持渐进式图像生成(从左到右逐块清晰化)、多语言指令(中英文)、开放编辑(风格迁移、深度图检测)。动态分辨率适配海报、社交媒体等场景。
项目主页:https://qwenlm.github.io/zh/blog/qwen-vlo/

行业应用:内容创作工具链、跨境电商产品可视化。
技术点评:渐进式生成提升可控性,多语言支持打破全球化协作壁垒。
6. 英伟达DAM:图像/视频局部精准描述
技术亮点:多模态大模型可针对用户指定的区域(点/框/涂鸦)生成详细描述(如“红色项圈银色标签”),通过局部视觉骨干网络和半监督数据管道平衡细节与全局上下文。
项目主页:https://describe-anything.github.io/

行业应用:医疗影像分析、安防监控目标标注。
技术点评:DLC-Bench基准验证其细节准确性优于通用模型,推动垂直领域智能化。
三、机器人技术:泛化与复杂操作
7. GR-3:字节跳动的通用机器人“大脑”
技术亮点:大规模视觉-语言-动作(VLA)模型,通过VR设备采集人类轨迹数据微调,支持长序列灵巧操作(如双手整理餐桌)和新物体泛化(45种未见物品)。配套双臂机器人ByteMini。
项目主页:https://seed.bytedance.com/zh/GR3
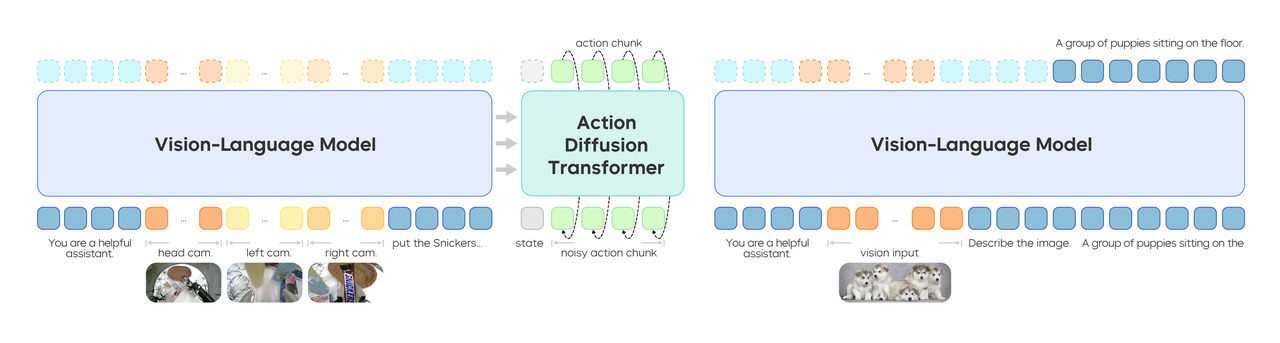
行业应用:制造业自动化、家庭服务机器人。
技术点评:视觉-语言联合训练提升泛化能力,低成本适应新任务,加速通用机器人落地。
8. Reachy Mini:开源AI教育机器人
技术亮点:轻量级人形机器人,支持编程交互、创意实验,降低AI教育门槛。
项目主页:https://describe-anything.github.io/

行业应用:STEM教育、科研原型开发。
技术点评:开源生态促进技术民主化,适合教学与创新实践。(注:原文未提供详细技术链接,补充说明)
四、图像生成与编辑:风格化与个性化
9. NovelAI Diffusion Anime V2:动漫风格图像生成
技术亮点:基于Stable Diffusion 1.5优化,支持高分辨率动漫图像生成,开源权重便于二次开发。
项目主页:https://huggingface.co/NovelAI/nai-anime-v2

行业应用:插画创作、游戏美术资源生产。
技术点评:平衡生成质量与计算效率,满足二次元文化市场需求。
10. CanonSwap:高保真视频换脸技术
技术亮点:通过规范空间解耦分离运动与外观信息,部分身份调制模块精准控制面部区域,解决传统换脸的身份失真与动态不一致问题。
项目主页:https://luoxyhappy.github.io/CanonSwap/

行业应用:影视特效、虚拟数字人。
技术点评:时空一致性保障换脸真实性,适用于内容创作与隐私保护场景。
五、动画与视频生成:长序列与语义控制
11. LongAnimation:动态全局-局部记忆的长动画生成
技术亮点:结合SketchDiT和动态全局-局部记忆(DGLM),实现500帧长动画的颜色一致性(优于局部融合方法),支持文本引导背景生成。
项目主页:https://cn-makers.github.io/long_animation_web/
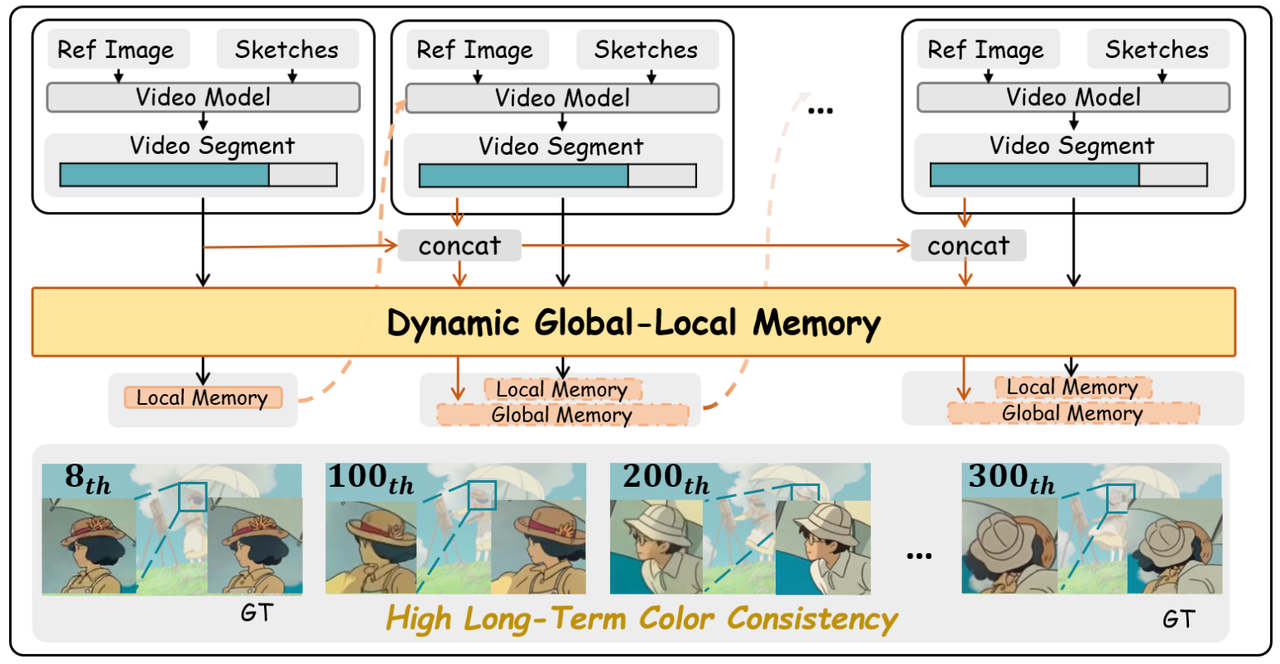
行业应用:动画剧集制作、广告长镜头设计。
技术点评:全局记忆机制解决长时序依赖问题,提升创作效率。
12. OmniAvatar:音频驱动全身动画
技术亮点:像素级多层级音频嵌入提升口型同步精度,LoRA训练兼容基础模型,支持情感、背景、动作幅度控制。
项目主页:https://omni-avatar.github.io/
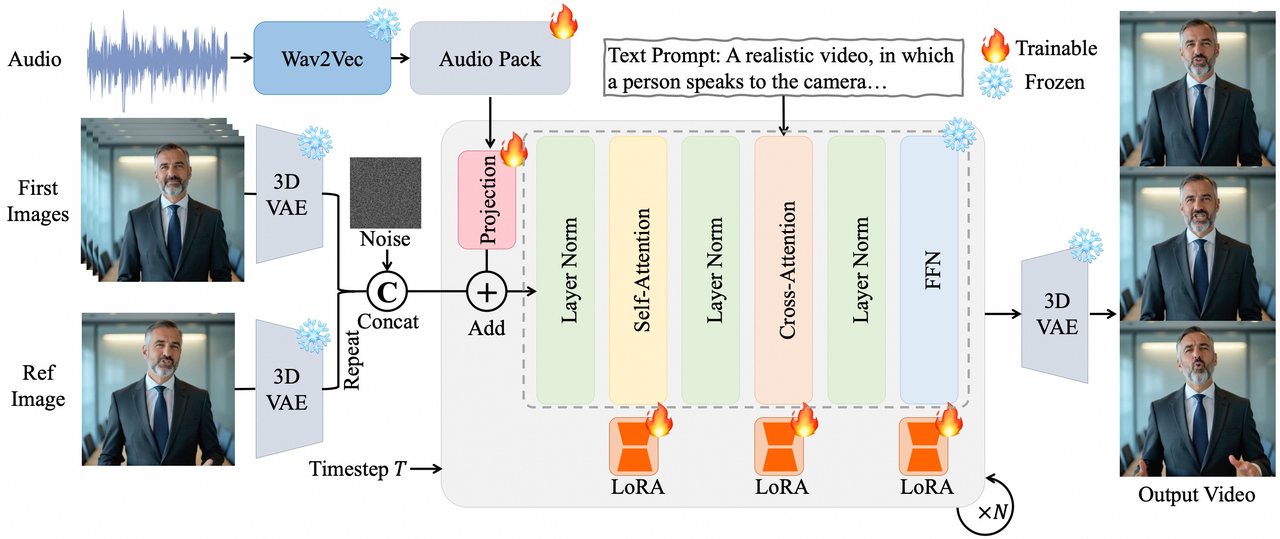
行业应用:虚拟主播、互动影视内容。
技术点评:多模态融合实现自然表演效果,拓展数字人应用边界。
总结与展望
7月的AIGC开源项目覆盖视频、图像、机器人、多模态理解四大领域,核心趋势包括:
-
低成本高性能(如PUSA、FreeAudio);
-
实时交互性(如MirageLSD);
-
精准控制与泛化能力(如XVerse、GR-3)。
未来,随着这些技术的落地,内容创作民主化、机器人智能化、多模态交互自然化将成为可能。开发者可重点关注Qwen VLo的多语言支持、GR-3的VLA架构及MirageLSD的实时生成优化,挖掘商业化潜力。
推荐阅读
► AGI新时代的探索之旅:2025 AIGCmagic社区全新启航
► 技术资讯: 魔方AI新视界
► 项目应用:开源视界
► 技术专栏: 多模态大模型最新技术解读专栏 | AI视频最新技术解读专栏 | 大模型基础入门系列专栏 | 视频内容理解技术专栏 | 从零走向AGI系列
► 技术综述: 一文掌握视频扩散模型 | YOLO系列的十年全面综述 | 人体视频生成技术:挑战、方法和见解 | 一文读懂多模态大模型(MLLM)|一文搞懂RAG技术范式演变及Agentic RAG|强化学习技术全面解读 SFT、RLHF、RLAIF、DPO|一文搞懂DeepSeek的技术演进之路



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









