




简介
XPath 是一门在 XML 文档中快速查找信息的技术 。XPath 可用来在 XML 文档中对元素和属性进行遍历。
如果需要使用xpath表达式,那么需要导入jaxen-1.1-beta-6.jar包。该jar包存在dom4j压缩包的lib文件加中,如下图所示:
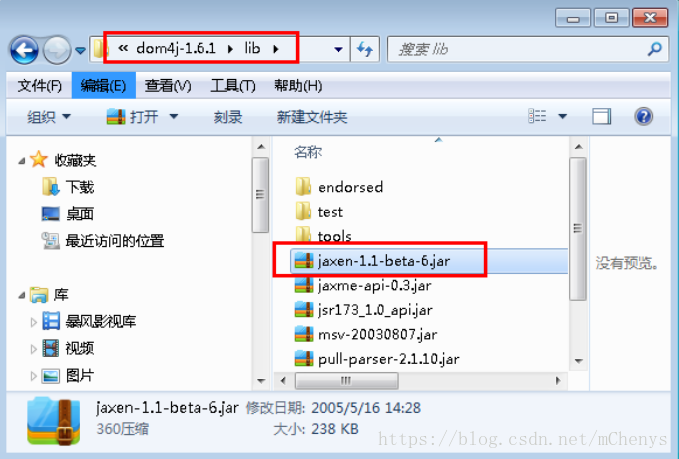
Xpath的两个常用方法
selectSingleNode() 获取单个节点,如果有多个节点符合,那么只获取其中的第一个节点。
selectNodes() 获取符合xpath表达式的所有节点,返回的是一个集合对象。 这个集合对象就存储了所有的节点信息。
例如:
String xpath = "//person";
String name = document.selectSingleNode(xpath).getName();//获取单个节点的名称
List<Node> list = document.selectNodes(xpath);//获取多个节点
for(Node node : list){
System.out.println(node);
}Xpath的语法
通过demo演示xpath语法的使用,项目工程如下:
package demo;
import java.io.File;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
/**
* xpath语法:
*
* xpath找元素的时候可以根据绝对路径去寻找节点元素。
*
* @author mChenys
*
*/
public class Demo {
public static void main(String[] args) throws Exception {
// 先得到document对象
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("person.xml"));
//定义xpath表达式
String xpath = "/"; // "/" 则代表了document对象。
// (1)根据绝对路径寻找节点的元素 绝对路径是以 / 开头的。
xpath = "/person-list/person";
xpath = "/person-list/person/name";
// (2)相对路径找节点: 相对路径就是相对于当前指定selectNodes方法的节点。 相对路径没有以“/”开头的
xpath = "."; // 代表了当前路径
xpath = ".."; // 上一个节点
xpath = "name"; // 这种写法就相当于是 ./name
xpath = "./name";
// (3)不管任何路径,在整个文档上去找对应的节点。 在整个文档上去寻找的路径是以 "//"
xpath = "//name"; // 在文档上找所有的name节点。
xpath = "/person-list/person//name"; // 先要符合前面的路径信息,然后前面基础上再去找name节点。
// (4)找属性 在名字前面加上@符号
xpath = "//person/@id";
// (5)找到节点添加附加属性
xpath = "//person[@id=200]"; // 附加添加是写到[]中去的。
xpath = "//person[2]"; // 获取位置是2 的person元素,这里所说的位置是指当前节点相对于它的父节点的位置。
xpath = "//person[3]";
xpath = "//person[last()-1]"; // last() 代表最后一个元素
xpath = "//person[position()>2]"; // position() 代表的是位置。
xpath = "//person[position()=2]";
xpath = "//person[@id>200]";
// (6)通配符 *
xpath = "//*"; // *号代表了所有的节点
xpath = "//@*"; // @*代表了所有的属性节点
List<Node> nodes = document.selectNodes(xpath);
for (Node node : nodes) {
System.out.println(node.getText());
}
}
}
















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









