




 本文介绍了一个使用Python开发的批量测试工具,该工具采用多进程处理大量案例,支持单例模式和队列通信机制,适用于Windows平台。文章详细记录了开发过程中的关键步骤和技术要点。
本文介绍了一个使用Python开发的批量测试工具,该工具采用多进程处理大量案例,支持单例模式和队列通信机制,适用于Windows平台。文章详细记录了开发过程中的关键步骤和技术要点。
经过一周的学习,做出一个简陋的工具(python),但是还没有涉及到网络等方面
#功能描述:辅助性,配合exe文件,对大批量case进行目标对比测试
本博客主要记录在学习过程中遇到的问题,为后面的学习铺路
从最基础的开始记录,毕竟万丈高楼平地起:
1.python中的对缩进要求很严格,区分模块 作用域等
2.if __name__=="__main__": 很强大,在此作用域下的代码只运行在本模块中
3.模块化设计很重要,方便模块测试和维护
4.多了解py自带的模块,提供的功能很全面
5.python支持面向对象设计:数据成员或者方法的属性通过下划线标识,public:常规 protect :_data,开头单下划线 private:__data,开头双下划线
6.类中的方法第一个参数必须是一个标识,一般用self,访问数据也要是self.data
7.用到很多对文件还有字符串的操作,python很灵活
8.python由于各种原因,多线程几乎没有作用,因为只用一个核,所以应该用多进程,Windows和Linux的进程方法不同,我用于Windows平台,import multiprocessing as proc,提供了进程池Pool
9.进程间通信:可以通过消息队列,父子进程间的通信:
manager = multiprocessing.Manager() //Manager类
que = manager.Queue() //主进程中创建消息队列
lock = manager.Lock() //创建锁
for count in range(num): //num是进程池中要处理的事件数量
pool.apply_async(run_proc,args=((option.single_mode,que,num,lock),) //用元组传递参数给子进程
p1.close() #关闭进程池
p1.join() #阻塞进程池
//为什么要锁?因为消息队列读的时候需要加锁操作,防止错乱,本身并不是进程安全的后续还有处理方面的源码之外的部
##main.py
import os
import sys
import time
import logging
import subprocess
import file_find as path
from worker import worker
import multiprocessing as proc
from get_option import Getoption as getop
import multiprocessing
###############################
def run_proc(args): #option.single_mode,que,num,lock
print("step into run_proc")
num = 0
num = args[2]
flag = num
#print(args[0],args[1],args[2])
# -------------error
work = worker()
if args[0] == 1:
if args[1].empty()==True:
return
args[3].acquire()
value = args[1].get()
args[3].release()
work.run(value,args[0])
print("single_mode == 1")
return
else:
while num>0:
if args[1].empty()==True:
break
if flag<=100: ##
num-=1
args[3].acquire()
value = args[1].get()
args[3].release()
work.run(value,args[0])
print("single_mode == 0")
return
#print("proc is :",os.getpid())
######################## log
logging.basicConfig(level=logging.DEBUG,
format='proc id=%(process)5d:%(asctime)5s %(filename)8s[line:%(lineno)3d] %(levelname)s: %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='log.log',
filemode='a')
log = logging.getLogger()
########################
if __name__=="__main__":
option = getop(sys.argv)
option.run()
path.load_name_to_file() # 加载 输入完毕
log.info("load filename to find_file.txt")
lines = 0 ##得到文件行数==>得到要检测的文件数量
load_file = []
load = []
with open(r"find_file.txt","r+") as f:
load_file = f.readlines()
lines = len(load_file)
for i in range(lines):
tmp = load_file[i].strip('\n')
load.append(tmp)
p1=proc.Pool(option.process_num) #设定进程数等于核心数-1
log.info("start %d process",option.process_num)
num = int(lines/option.process_num)+1 ####### 单个进程处理事件个数 待商榷
#print("QWERTYU",num)
#load[get.single_mode]
manager = multiprocessing.Manager()
que = manager.Queue()
for value in load:
que.put(value)
#lock = multiprocessing.Lock()
lock = manager.Lock()
log.info('num of proc is:%d',option.process_num) #+++++++++++
for count in range(lines):
_async(run_pro#args=((option.single_mode,que,num,lock),)) #设定异步执行任务
p1.close() #行
闭
p1.join() #阻塞进程池
print("ending") #打印结束语句
get_option.py
import sys
import getopt as get
import multiprocessing as cpu
# ------ get option ------ # 状态:基本OK
class Getoption:
single_mode = 0
process_num = cpu.cpu_count()-1
argvs = []
def __init__(self,m_argv):
self.argvs = m_argv
#print(argvs[1:])
def help(self):
print()
print("-m : 设置single_mode 1代表是 其他数字代表不是,默认 1")
print("-n : 设置需要的进程数,默认为CPU数-1")
def get_opt(self):
#print("step in get_opt")
try:
option,args = get.getopt(self.argvs[1:],'hm:n:h')
except get.GetoptError:
print("getoption error!");exit(2)
for opt,arg in option:
if opt == '-h':
self.help()
exit()
if opt == '-m':
if arg==1:
self.single_mode = 1
else:
self.single_mode = 0
print("single_mode is",self.single_mode);break
if opt == '-n':
if arg>cpu.cpu_count():
self.process_num = cpu.cpu_count()
else:
self.process_num = arg
print("process_num is",self.process_num);break
def run(self):
self.get_opt()
if __name__ == "__main__":
a = Getoption(sys.argv)
a.run() file_find.py
#本模块将目标文件夹中的目标类型文件path+name打印至find_text.text中
import os
searchFileList = []
def search(start_dir,target):#start_dir(要查找的目录),target(要查找的文件后缀)
global searchFileList
fileList = os.listdir(start_dir)
for filename in fileList:
pathTmp = os.path.join(start_dir,filename) #获取path与filename组合后的路径
if os.path.isdir(pathTmp):#判断path与filename组合后的路径是不是目录
search(pathTmp,target)
else:
postFix = pathTmp[pathTmp.rfind(".")+1:]
if postFix in target:
pathTmp+='\n'
searchFileList.append(pathTmp)
def searchFile():
#给其他模块提供的查找路径下文件的方法
while True:
path = input("请输入你要查找的绝对路径:")
if os.path.isdir(path) == True:
break
print("输入有误,请重新输入")
str = input("请输入你要查找的文件后缀:")
str = str.lower()
postFixList = str.split(",")
search(path,postFixList)
return searchFileList
def load_name_to_file():
s = searchFile()
with open("find_file.txt",'w') as f:
f.writelines(s)
if __name__ == "__main__":
load_name_to_file()
worker.py
import subprocess
import logging
import os
# ------ 子进程中的工作 ------
class worker:
single_mode = 1 #mode
m_path = '' #file
logging.basicConfig(level=logging.DEBUG,
format='proc id=%(process)5d:%(asctime)5s %(filename)8s[line:%(lineno)3d] %(levelname)s: %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='log.log',
filemode='a')
log = logging.getLogger()
##-----------------------
def built_name(self): #根据case名字 给其输出命名
s = "\\"
count = self.m_path.find(s)+1
list_str = self.m_path.split(s,count)
tmp = list_str[count]
name = tmp.split(".",2)
#print("name is:",name[0])
return name[0]
##------------------------
def load_file_to_exe(self):
name = self.built_name()
path_and_name = "recv/%s.txt"%(name)
#print(path_and_name)
cmd = " -m %d -p %s "%(self.single_mode,self.m_path)
#print(cmd)
with open(path_and_name,'w') as outf:
#p = subprocess.Popen([r"E:\码库\Win32Project2\Debug\Win32Project2.exe",cmd],stdout=outf,stderr=outf)
pass
##-----------------------
def cmp_file(): #比对文件 产生对应result -----------
print("start compare file")
##对比模块的
##------------------------
def run(self,path,single):
#print("start work")
self.single_mode = single
self.m_path = path
self.log.info("%6d proc load %s",os.getpid(),self.m_path)
#print(self.single_mode,path)
self.load_file_to_exe()
##-------------------------
if __name__ == "__main__":
work = worker()
work.run(r"E:\PyCode\practice\demo.py",10)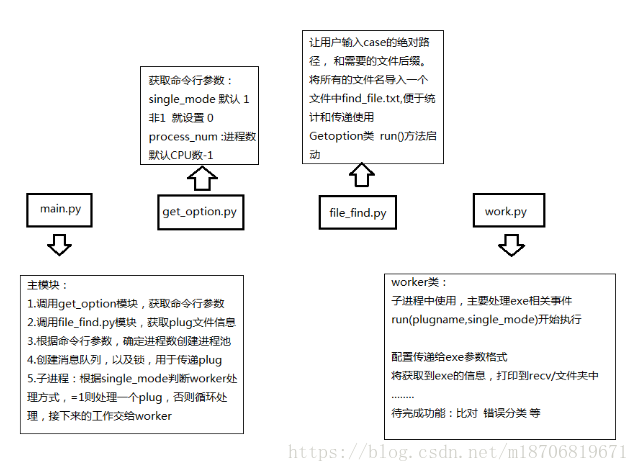


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









