



 文章分别探讨了语音识别中的声学模型,包括高斯混合模型与隐马尔可夫模型、深度神经网络以及长短时记忆网络在文本识别和声纹识别中的应用。同时,介绍了在噪音环境下提升语音识别鲁棒性的各种技术,如特征提取方法、鲁棒性声学模型改进,涉及DNN、CNN和对抗性学习等方法。
文章分别探讨了语音识别中的声学模型,包括高斯混合模型与隐马尔可夫模型、深度神经网络以及长短时记忆网络在文本识别和声纹识别中的应用。同时,介绍了在噪音环境下提升语音识别鲁棒性的各种技术,如特征提取方法、鲁棒性声学模型改进,涉及DNN、CNN和对抗性学习等方法。
2021.03.25
论文:语音识别中声学模型研究综述(作者:叶硕、褚钰、王祎、李田港)
笔记:
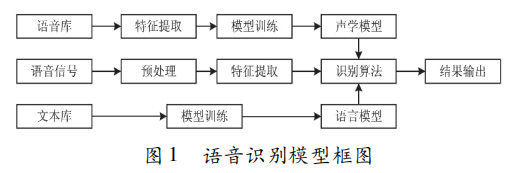
1.语音识别:声学模型、语言模型
2.语音识别可分为三个方向:
文本识别:将语音中的内容转换为文本。
声学模型分析:(1)高斯混合模型(GMM)[可对任意概率密度函数进行拟合逼近]与隐马尔可夫模型(HMM)[HMM转移的概率只与前一时刻有关,无法充分利用上下文信息] 结合。
增强GMM拟合能力时,需要优化的数据也急剧上升,给声学模型的训练带来极大的负担。
(2)深度神经网络(DNN)[对声学特征矢量和状态关系进行建模]与隐马尔可夫模型(HMM)
(3)长短时记忆网络(LSTM)和深度神经网络(DNN)
声纹识别:研究说话人的身份或特定文本。【两类:说话人辨认、说话人验证】
声学模型分析:GMM-UBM。CNN。DNN。
情绪识别:对语音中包含的情感进行识别。
声学模型分析:LSTM-CTC。HMM-LSTM。
论文:鲁棒性语音识别技术研究综述(作者:黄志东)
笔记:本文主要 主题围绕 语音识别技术在噪音环境下的鲁棒性
1.常见的语音特征:滤波器组特征(FBANK)、梅尔频率倒谱系数(MFCC)、相对谱变换与感知性预测等。
2.语音特征提取:
特征线性变换:有线性判别分析(LDA)、最大似然线性变化(MLLT)。
单耳特征增强:基于DNN语音增强框架的听觉单耳特征。类似于人类的听觉系统。
瓶颈特征提取:BN提取器具有共享层(学习语言的不变特性)和独占层(捕获依赖于语言的特性)。共享隐藏层模型、堆叠共享独占模型、并行共享-独占模型(优于前两者)。基于无监督语音标签估计的瓶颈特征提取方式、基于DNN语音水平识别系统。
基于自动编码器的特征提取:去噪自编码器(DAE)、多任务自动编码器[能从噪声语音中估计噪声特征]。
基于迁移学习的特征提取:对抗性师生学习(T/S)。
3.鲁棒性声学模型(识别算法):
基于DNN的声学模型改进:修改了DNN的神经元数量、层的组合以及使用不同的激活函数和算法等方面,提高了语音识别技术在未知噪声下的性能。
基于CNN的声学模型改进:两种CNN:一种是宽带背景窗口的宽带功能,一种是窄带背景窗口的窄带功能。基于DCNN的语音增强方法。
基于生成对抗网络的声学模型改进:基于GAN的声学模型和基于神经网络的声学模型用于训练阶段、结合瓶颈特征提取。

















 3042
3042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









