




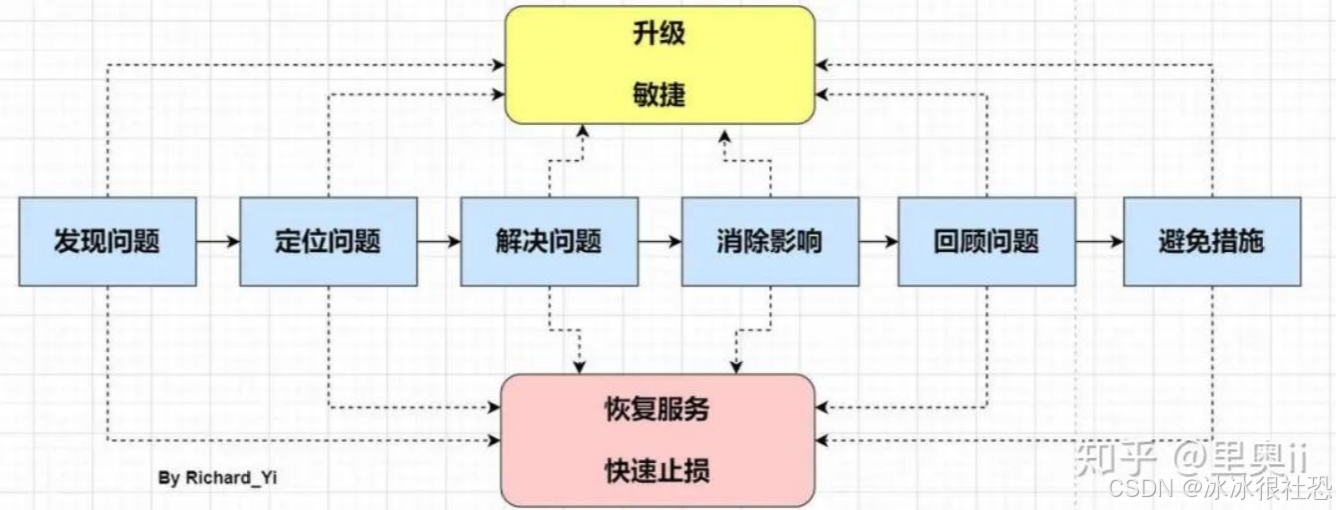
在线上应急过程中要记住,只有一个总体目标:尽快恢复服务,消除影响。不管处于应急的哪个阶段,我们首先必须想到的是恢复问题,恢复问题不一定能够定位问题,也不一定有完美的解决方案,也许是通过经验判断,也许是预设开关等,但都可能让我们达到快速恢复的目的,然后保留部分现场,再去定位问题、解决问题和复盘。
在大多数情况下,我们都是先优先恢复服务,保留下当时的异常信息(内存dump、线程dump、gc log等等,在紧急情况下甚至可以不用保留,等到事后去复现),等到服务正常,再去复盘问题。
常见现象:CPU 利用率高/飙升
场景预设:
监控系统突然告警,提示服务器负载异常。
预先说明:
CPU飙升只是一种现象,其中具体的问题可能有很多种,这里只是借这个现象切入。
注:CPU使用率是衡量系统繁忙程度的重要指标。但是 CPU使用率的安全阈值是相对的,取决于你的系统的IO密集型还是计算密集型。一般计算密集型应用CPU使用率偏高load偏低,IO密集型相反。
常见原因:
- 频繁 gc
- 死循环、线程阻塞、io wait...etc
模拟
这里为了演示,用一个最简单的死循环来模拟CPU飙升的场景,下面是模拟代码,
在一个最简单的SpringBoot Web 项目中增加CpuReaper这个类,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











