



import requests
import re
import json
# 实操为 3,理论为 2,实操加上token
cookie = input("请输入Cookie:\n")
header = {
"Cookie": cookie
}
obj1 = re.compile(r'name="" packageid="(.*?)"')
obj3 = re.compile(r'sectioninsid=(.*?)"')
packageids = []
for i in range(2,11):
url1 = f"http://218.199.190.122:806/index.php/Book/lists?per_page={i}"
with requests.get(url1,headers=header) as r1:
text = r1.text
packageids.extend(obj1.findall(text))
for j in packageids:
url2 = "http://218.199.190.122:806/index.php/Book/createstudy"
data={
"packageid": j
}
with requests.post(url2,data=data,headers=header) as r2:
# {"code":"0000","msg":"下发成功","data":{"taskid":3881}}
json_data = json.loads(r2.text)
taskid = json_data['data']['taskid']
print("start" + str(taskid))
url3 = f"http://218.199.190.122:806/index.php/Study/studydetail?taskid={taskid}"
with requests.get(url3,headers=header) as r3:
sectioninsids = obj3.findall(r3.text)
for k in sectioninsids:
url4 = "http://218.199.190.122:806/index.php/Study/sectionScore/"
data1={
"sectioninsid": k,
"taskid": taskid,
"type": "2"
}
with requests.post(url=url4,headers=header,data=data1) as r4:
print(r4.text)
pass
for k in sectioninsids:
url4 = "http://218.199.190.122:806/index.php/Study/sectionScore/"
data1={
"sectioninsid": k,
"taskid": taskid,
"type": "3"
}
with requests.post(url=url4,headers=header,data=data1) as r0:
print(r0.text)
pass
url5 = "http://218.199.190.122:806/index.php/Study/endstudy"
data3 = {"taskid": taskid}
with requests.post(url5,headers=header,data=data3) as r5:
print("finished" + str(taskid))
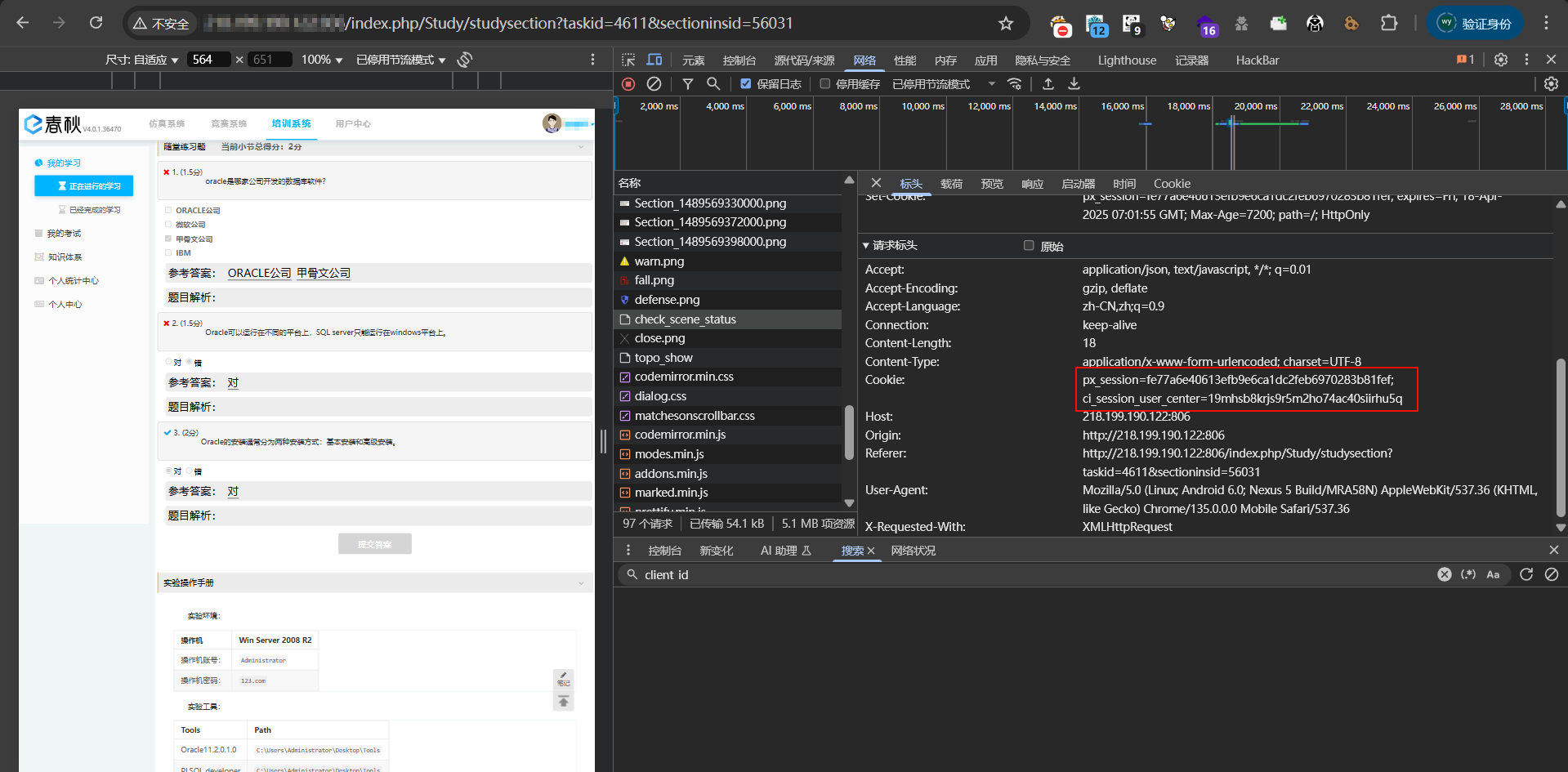
1、登录获取Cookie(这里设置了HttpOnly)我们直接F12抓包获取Cookie
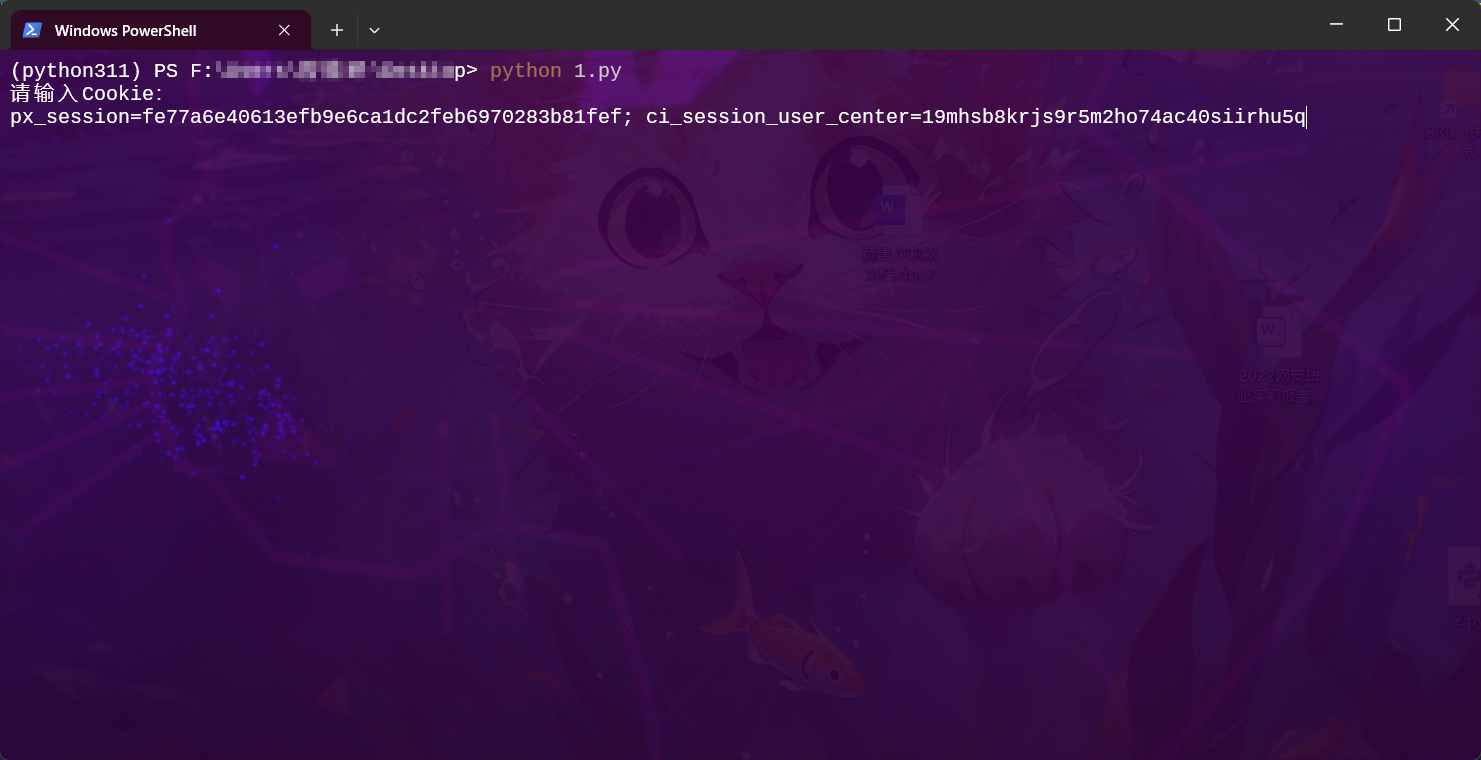
2、运行脚本输出Cookie,会自动刷完所有课程(是所有课程),替换掉域名即可
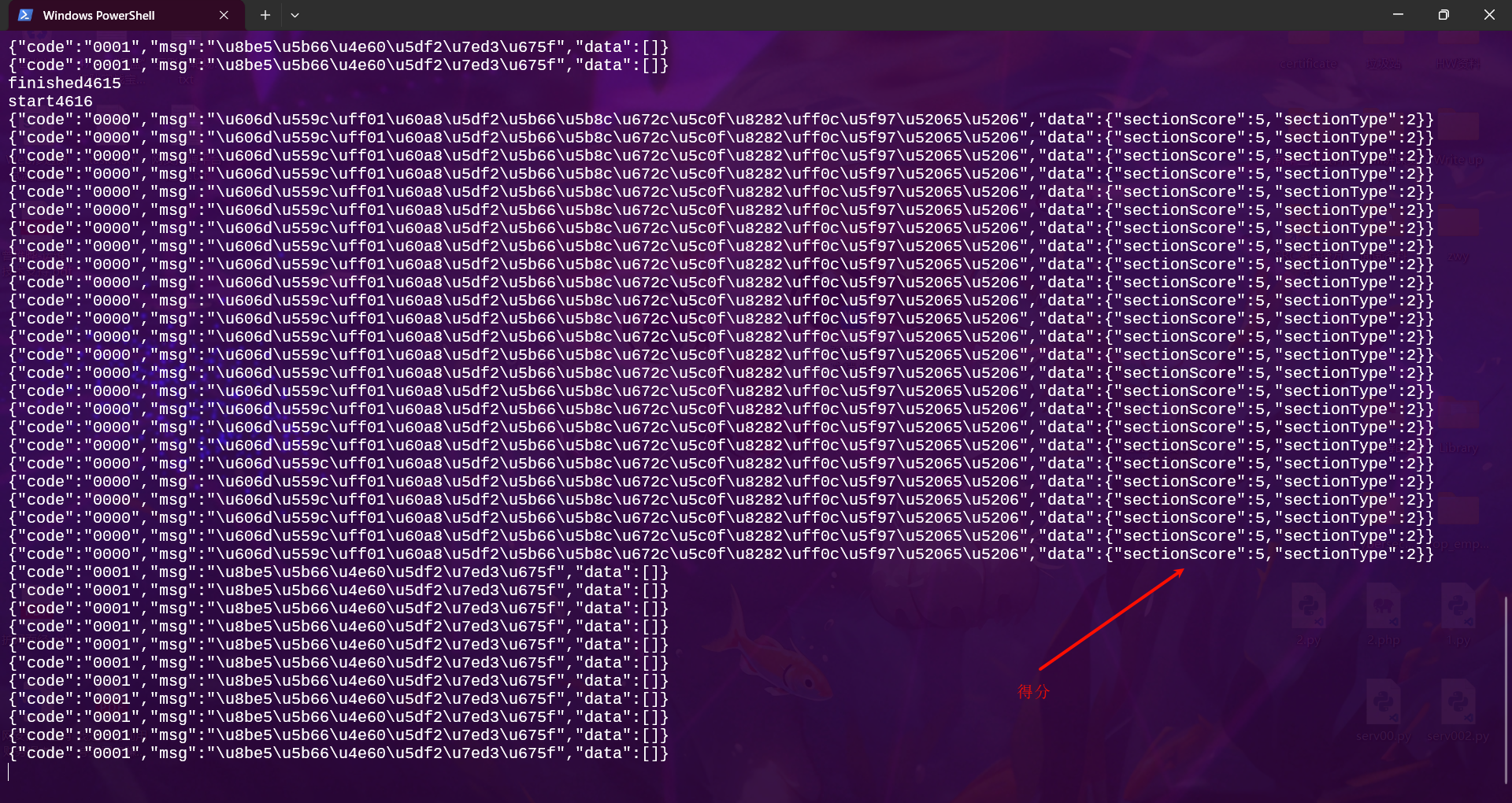
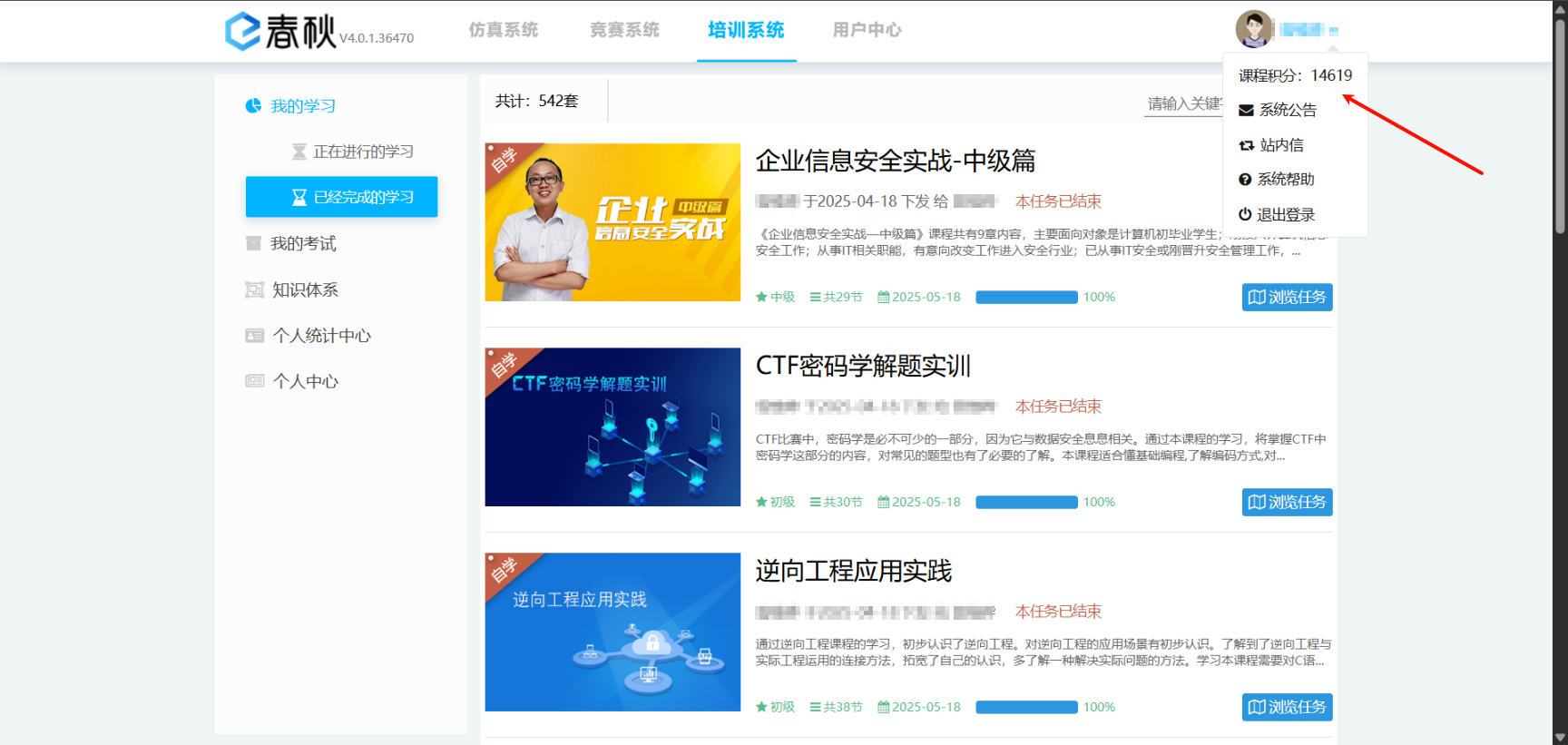
几分钟即可跑完


















 4712
4712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









