






近年来,多模态大语言模型(MLLM)在跨模态理解和生成任务中取得显著突破,其核心创新包括:
√架构融合:如Google的Gemini和OpenAI的GPT-4V通过统一Transformer框架实现文本、图像、视频和音频的联合编码与推理,显著提升跨模态对齐能力;
√小样本泛化:Meta的Flamingo和LLaVA-1.5引入可训练适配器与视觉提示,仅需少量标注数据即可完成复杂任务(如视觉问答、图文生成);
√推理增强:微软的KOSMOS-2.5结合符号推理模块,解决数学公式与图表的多模态解析难题;
√高效训练:DeepSeek-VL采用混合专家(MoE)技术降低计算成本,同时支持高分辨率图像输入。
这些进展推动了医疗影像分析、跨模态内容创作等应用,但模型幻觉、多模态数据偏差等问题仍是未来研究重点。我整理了10篇【多模态大语言模型】的相关论文,全部论文PDF版,工中号【沃的顶会】回复“MLLMs”即可领取。
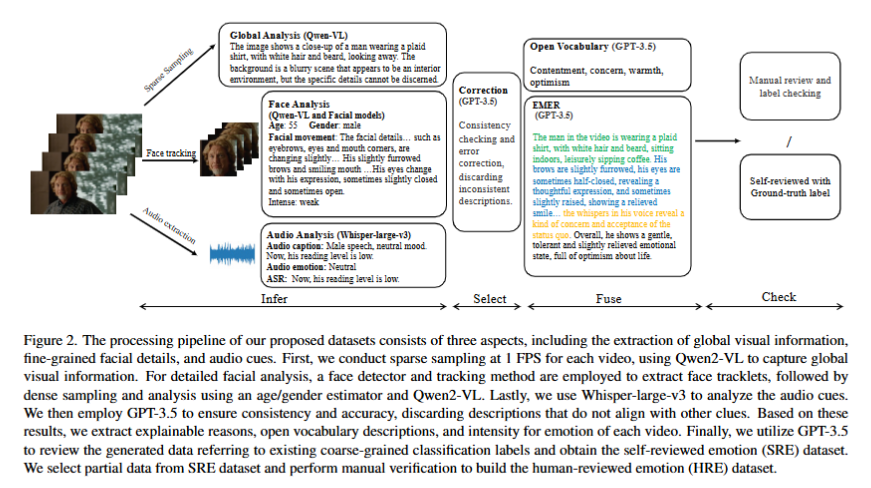
Omni-Emotion:Extending Video MLLM with Detailed Face and Audio Modeling for Multimodal Emotion Analysis
文章解析
本文提出了一种新的多模态情感分析方法Omni-Emotion,通过整合精细的面部编码模型和音频特征到现有的视频多模态大语言模型(MLLM)中,解决了当前模型在捕捉微妙面部表情和音频线索上的不足。
同时构建了高质量的自审与人工审阅数据集,显著提升了情感识别与推理任务的性能。
创新点
提出了将面部编码模型显式集成到视频MLLM中以捕捉细微面部线索。
构建了包含24,137个粗粒度样本和3,500个人工标注样本的高质量数据集。
实现了多模态情感分析领域的最先进性能,特别是在开放词汇情感识别任务中表现突出。
研究方法
通过整合FaceXFormer和Whisper-large-v3等模型提取面部和音频特征,并将其对齐到通用视频MLLM嵌入空间。
设计了三阶段训练过程,有效统一音频编码器和细粒度面部编码器到视频MLLM中。
利用GPT-3.5生成一致性描述并筛选高质量的多模态情感推理标签。
研究结论
提出的Omni-Emotion模型在多种情感分析任务中取得了最先进的结果。
高质量数据集的构建显著提高了模型的泛化能力和实际应用效果。
该方法为未来多模态情感分析研究提供了新方向。
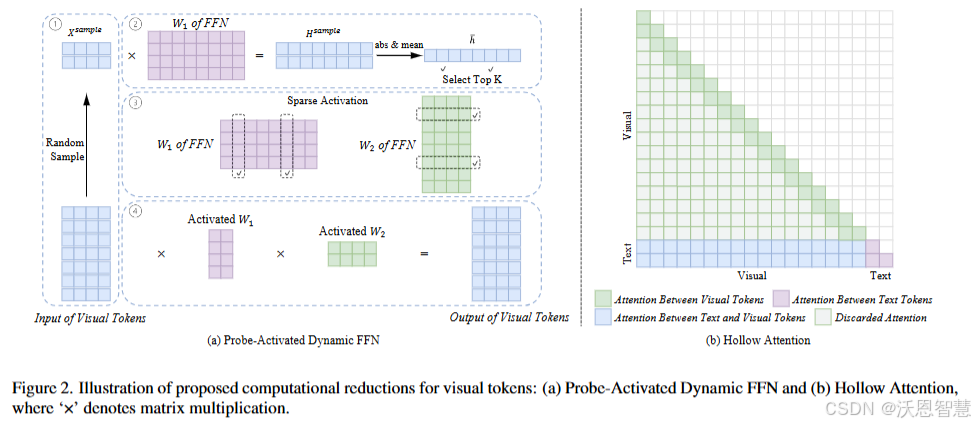
Beyond Token Compression: A Training-Free Reduction Framework for Efficient Visual Processing in MLLMs
文章解析
本文提出了一种无需重新训练的分析框架,通过Hollow Attention和Probe-Activated Dynamic FFN方法减少解码器-only架构中视觉Token的计算冗余,显著降低计算成本同时保持甚至提升模型性能,揭示了当前MLLMs中视觉Token处理的大量冗余,并为未来更高效的模型设计提供了重要启示。
创新点
提出了Hollow Attention,限制视觉Token的全局自注意力为局部注意力,同时保留视觉与文本的关联性。
设计了Probe-Activated Dynamic FFN,仅激活部分FFN参数处理视觉Token,无需额外训练。
引入了一种无训练加速方法,可与现有Token压缩技术结合,实现互补加速。
研究方法
通过分析解码器-only架构中视觉Token的自注意力和FFN操作的高计算成本问题,提出针对性的优化策略。
设计了贪婪搜索方法,评估不同层应用减少策略的影响,选择最优层进行优化。
在多个最先进的MLLMs上进行实验,验证减少策略的有效性和适用性。
研究结论
当前解码器-only MLLMs中存在显著的计算冗余,约一半的层可以通过减少计算维持或提升性能。
所提出的无训练加速方法效果优于或等同于现有Token压缩技术,且具有自然兼容性。
研究发现为未来更高效的MLLMs设计提供了重要参考。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









