




 本文介绍了如何在Flask应用中使用SQLAlchemy进行数据库操作,包括基础安装、配置数据库连接、创建ORM模型、表的CRUD操作以及常用的查询过滤和执行。
本文介绍了如何在Flask应用中使用SQLAlchemy进行数据库操作,包括基础安装、配置数据库连接、创建ORM模型、表的CRUD操作以及常用的查询过滤和执行。
文章目录
Flask-SQLAIchemy基本建立操作(实验项目第一期)
SQLAIchemy是什么
使用SQLAIchemy的一个优势在于不需要使用SQL语句来进行数据库的操作,它有一套自定义的更易于理解的规范,对没学过SQL语句的使用者比较友好

ORM
SQLAlchemy是一种在Python中使用的流行的SQL工具包,提供了ORM(对象关系映射),ORM可以将Python类和SQL表进行映射,它允许开发人员通过面向对象的方式使用关系数据库。
Flask框架的一个扩展
Flask-SQLAlchemy是Flask 框架的一个扩展,其对SQLAlchemy进行了封装,借助Flask-SQLAlchemy,可以使用Python类定义数据库模型,然后使用这些类来创建、读取、更新和删除相应的数据库表中的记录。此外,Flask-SQLAlchemy还提供了对数据库迁移的支持,使得随着应用程序的不断演进,修改数据库模式变得更加容易。
1.基础安装
版本依赖说明:

首先是最基础的安装Flask-SQLAlchemy(如果使用MySQL数据库的话还需要安装mysqldb)
pip install flask-sqlalchemy
pip install flask-mysqldb
2.数据库连接配置
Flask的数据库基本设置:
数据库使用URL指定,而且程序使用的数据库必须保存到Flask配置对象(通常取名app)的’SQLALCHEMY_DATABASE_URI’中
# 创建Flask对象
app = Flask(__name__)
# 数据库配置:
# Flask数据库的设置: app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://账号:密码@数据库ip地址:端口号/数据库名"
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:123456@127.0.0.1:3306/mysqltest'
# 动态追踪修改设置,如未设置只会提示警告, 不建议开启
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# 查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
其他的设置:
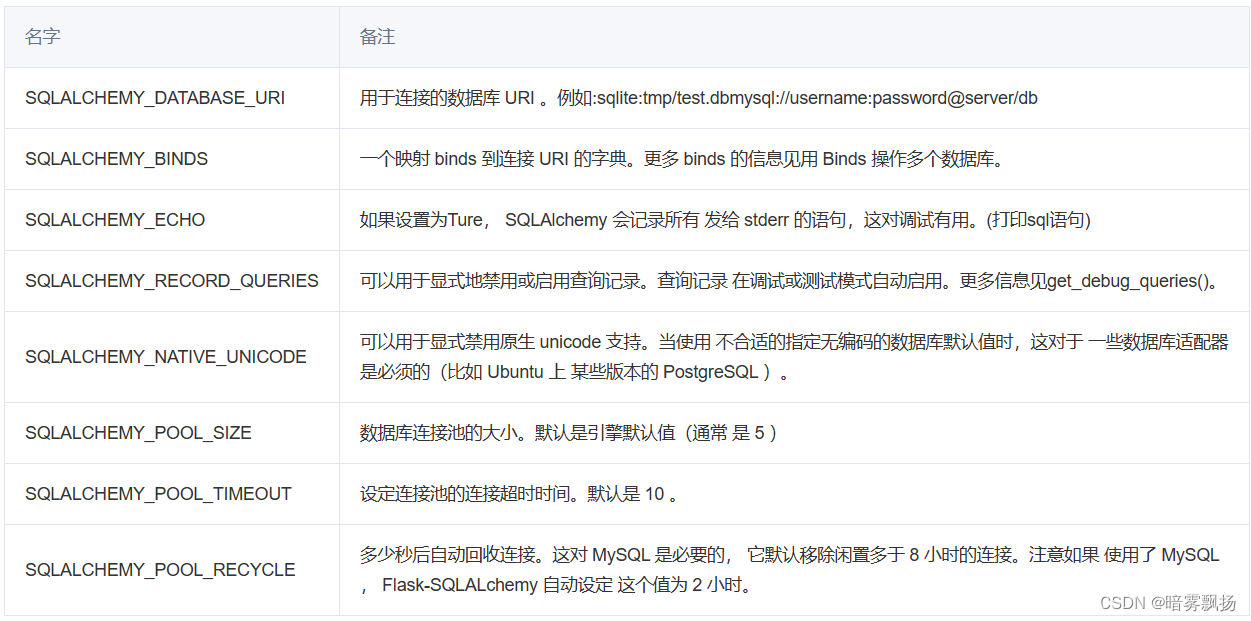
(更多设置请查阅flask-sqlaichemy文档)
常用的SQLAIchemy字段类型
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
常用的SQLAlchemy列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
常用的SQLAIchemy关系选项
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多中记录的排序方式 |
| secondary join | 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
(更多设置请查阅flask-sqlaichemy文档)
3.创建实例对象
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 创建Flask对象
app = Flask(__name__)
#数据库配置(此处省略,2.数据库连接配置里有)
app.config['SQLALCHEMY_DATABASE_URI'] = ....
...
...
# 实例化SQLAlchemy对象db[这两行也可以写成db = SQLAlchemy(app)]
db = SQLAlchemy()
db.init_app(app)
注意:在单独运行调试时,对数据库操作需要在Flask的应用上下文中进行
否则会出现:RuntimeError: Working outside of application context.
# 防止出现RuntimeError: Working outside of application context.
app.app_context().push()
此处请注意:app对象为Flask的应用配置,db对象为SQLAIchemy对象,SQLAIchemy对象需要知道它将要与哪个Flask应用程序实例绑定,如果在一个工程项目中不同的python文件中创建了不同的Flask实例,并且在每个文件中都创建了一个SQLAIchemy实例,则会导致问题:
RuntimeError: The current Flask app is not registered with this ‘SQLAlchemy’ instance. Did you forget to call ‘init_app’, or did you create multiple ‘SQLAlchemy’ instances?
(后期的项目文章里会具体讲到)
4.创建数据库表(定义ORM模型类)
创建User类继承自db.Model类,同时定义id,username,email,password…等属性,分别对应数据库中表user的列。
class User(db.Model):
# 定义表名
__tablename__ = 'users'
# 定义列对象
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(32), unique=True, index=True)
email = db.Column(db.String(32), unique=True)
password = db.Column(db.String(32))
# repr()方法显示一个可读字符串
def __repr__(self):
return '<User: %d %s %s %s>' % (self.id, self.username, self.email, self.password)
# 创建表
db.create_all()
# 删除表:db.drop_all()
主程序中运行时还可能会出现Restarting with stat的问题
if __name__ == '__main__':
app.debug = True # 开启debug
app.run(use_reloader=False)
# 在run()里加入参数 use_reloader=False,就可以解决 * Restarting with stat
常用参数说明(个人写的比较浅显,更多用法请查阅文档):
db.Model:所有模型类都应该继承自 db.Model。
__tablename__:指定模型类对应的数据库表名。如果不指定,则默认为类名的小写形式。
db.Column:用来定义模型类中的各个字段,需要指定字段类型。
primary_key=True:用来指定主键字段。
default:用来指定字段的默认值。
unique=True:用来指定字段的唯一性约束。
index=True:用来指定字段是否需要创建索引。
db.ForeignKey():用来定义外键关系。需要传入对应的表格的主键作为参数
db.relationship():用来定义模型之间的关系。第一个参数需要传入要关联的模型类名,第二个参数可以通过 backref 来指定反向引用
lazy:用来指定关系的加载方式,有两种常见的方式:
lazy=True:表示使用惰性加载,即在首次访问相关属性时才会加载数据。
lazy=False:表示立即加载,即在查询时同时加载相关数据。
5.数据库的增删改查
Flask-SQLAlchemy中,插入、修改、删除操作(不使用SQL语句),均由数据库会话管理。
查询操作则是使用query对象操作数据。
1)插入、修改、删除操作
会话用db.session表示。在准备把数据写入数据库前,要先将数据添加到会话中然后调用 commit() 方法提交会话。
1)增删改:
1. db.session.add(role) 添加到数据库的session中
2. db.session.add_all([user1, user2]) 添加多个信息到session中
3. db.session.commit() 提交数据库的修改(包括增/删/改)
4. db.session.rollback() 数据库的回滚操作
5. db.session.delete(user) 删除数据库(需跟上commit)
例子:
# 1.添加数据
user1 = User(id=1, name="小明")
user2 = User(id=2, name="小白", password="123")
try:
db.session.add_all([user1, user2]) # 添加多个用add_all()
# 提交添加,可通过rollback撤回
db.session.commit()
except Exception:
print("add error")
# 2.查询数据
try:
results = User.query.all()
print(results)
except Exception:
print("query error")
# 3.修改数据
try:
user1.username = "小红"
db.session.commit()
except Exception:
print("update error")
# 4.删除数据(需跟上commit)
try:
db.session.delete(user2)
db.session.commit()
db.session.rollback() # 回滚
except Exception:
print("delete error")
2)查询操作
查询操作则是使用query对象操作数据。
2)查询:
1. all()返回查询到的所有对象
User.query.all()
2. 查询有多少个用户
User.query.count()
3. 查询第1个用户
User.query.first()
4. 查询id为4的用户[3种方式]
# filter_by直接用属性名,比较用=, filter用类名.属性名,比较用==
# filter_by用于查询简单的列名,不支持比较运算符
# filter比filter_by的功能更强大,支持比较运算符,支持or_、in_等语法。
User.query.get(4)
User.query.filter_by(id=4).first() #属性 =
User.query.filter(User.id==4).first() #对象名.属性 ==
User.query.filter_by(id=4).first() #属性 =
例子:
# 获取用户提交的表单数据
username = request.form.get('username')
# 查询数据库,查看该用户名是否已经被注册
existing_user = User.query.filter_by(username=username).first()
if existing_user:
# 如果用户名已经存在,返回一个错误信息
response = {
'status': 'error',
'message': '该用户名已经被注册,请选择其他用户名'
}
return jsonify(response), 400
# 如果用户名不存在,可以继续进行用户注册的逻辑
email = request.form.get('email')
password = request.form.get('password')
常用的SQLAIchemy查询过滤器:

常用的SQLAIchemy查询执行器:
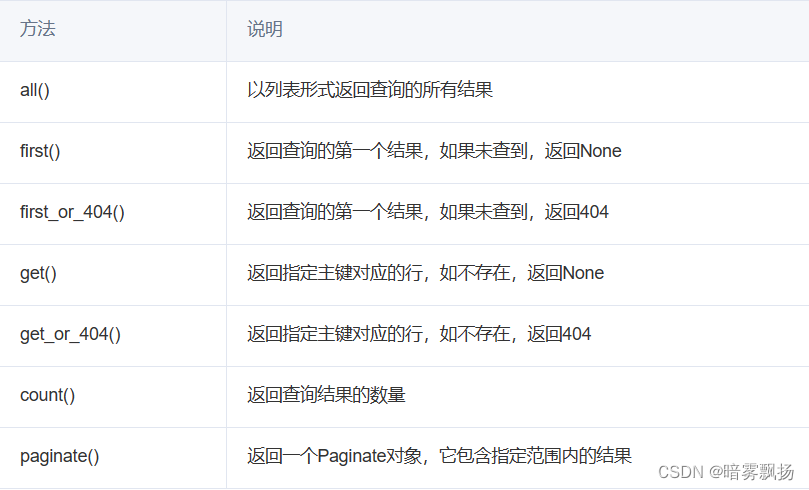
此处不再过多叙述,更多请查阅文档

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







